最近我突然有了一些富余的整塊時間。於是我實現了一些有意思的論文的 idea, 其中印象最深的還是《Hierarchical Attention Networks for Document Classification》。我把相關代碼放到這裡了:
今天,基本上所有的 NLP 方面的應用,如果想取得 state-of-art 的結果,就必須要經過 attention model 的加持。比如 machine translation, QA(question-answer), NLI(natural language inference), etc, etc…. 但是這裡有個問題: 傳統上的 attention 的應用,總是要求我們的 task 本身同時有源和目標的概念。比如在 machine translation 裡, 我們有源語言和目標語言,在 QA 裡我們有問題和答案,NLI 裡我們有 sentence pairs …… 而 Attention 常常被定義為目標和源的相關程度。
但是還有很多 task 不同時具有源和目標的概念。比如 document classification, 它只有原文,沒有目標語言/文章, 再比如 sentiment analysis(也可以看做是最簡單的一種 document classification),它也只有原文。那麼這種情況下 attention 如何展開呢? 這就需要一個變種的技術,叫 intra-attention(或者 self-attention), 顧名思義,就是原文自己內部的注意力機制。
intra-attention 有不同的做法。比如前一段 Google 發的那篇《Attention is All You Need》,在 machine translation 這個任務中,通過把 attention 機制 formularize 成 Key-Value 的形式,很自然的表達出源語言和目標語言各自的 intra-attention. 這麼做的好處是在句子內部產生清晰的 1.語法修飾 2. 語義指代關系 方面的理解,也就是說對句子的結構和意義有了更好的把控。
如下盜圖所示:
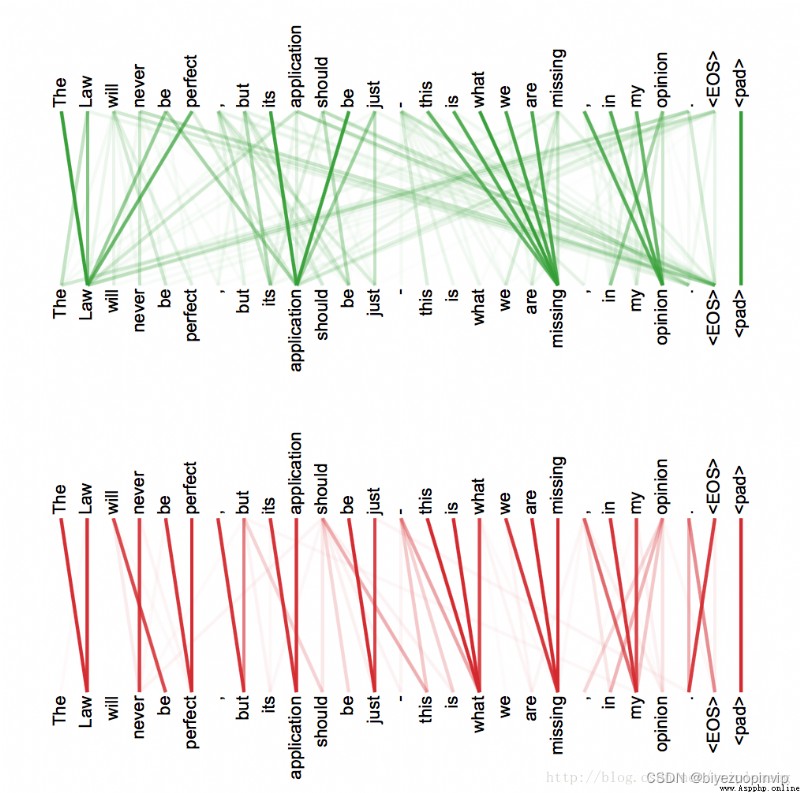
如上兩圖分別代表了原文在兩個不同子空間的投影的注意力結果(具體做法見原 Google 的論文,這裡的介紹從略)。我們可以看到清晰的指代關系和修飾關系。文章引入的 self-attention 機制加上 positional embedding 的做法,可能是將來的一個發展方向。
這篇論文采取了非常不一樣的做法。它引入了 context vector 用來發現每個詞語和每個句子的重要性。
它基於這樣的 observation:
每個 document 由多個句子組成,而在決定文章的類型時,每個句子有不同的重要性。有的更相關一些,有的用處不大。比如說在一篇有關動物科學的文章中,某些句子和文章的主題相關性就很高。比如包含類似於“斑馬”或者“獵食者”,“偽裝”這樣詞語的句子。我們在建造模型時,最好能夠給這樣的句子更多的“attention”。 同樣的,對於每個句子而言,它所包含的每個詞語的重要性也不一樣,比如在 IMDB 的 review 中, 如 like, amazing, terrible 這樣的詞語更能夠決定句子的 sentiment
所以,在分類任務中,如果我們給模型一篇文章,我們想問模型的問題是:1. 在這篇文章中,哪些句子更重要,能夠決定它的分類? 2. 在這篇文章的某個句子中,哪些詞語最重要,能夠影響句子在文章裡的重要性?
那麼,如何向模型提出這樣的問題呢? 或者說如何讓模型理解我們的意圖呢? 作者是通過引入 context vector 做到的。這個 context vector 有點天外飛仙的感覺, 之所以給我這樣的感覺,是因為:
context vector 是人工引入的,它不屬於 task 的一部分。它是隨機初始化的。
它代替了 inter-attention 中目標語言/句子,能夠和 task 中的原文產生相互作用,計算出原文各個部分的相關程度,也就是我們關心的 attention。
它是 jointly learned。 也就是說,它本身,也是學習得來的 !!
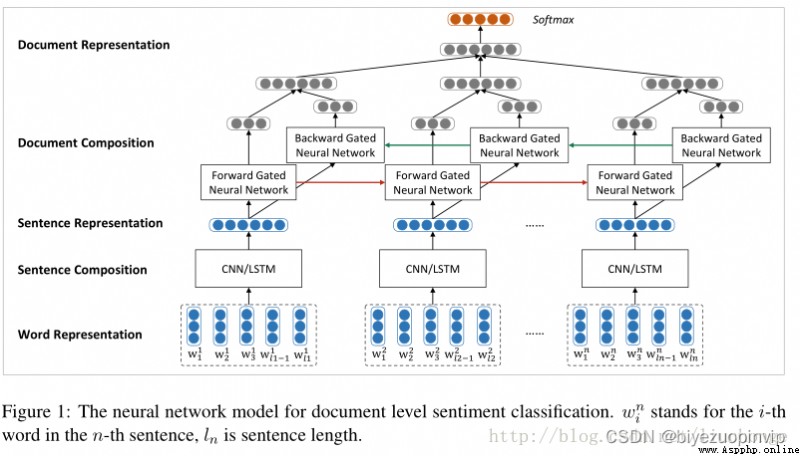
具體而言,網絡的架構如下:
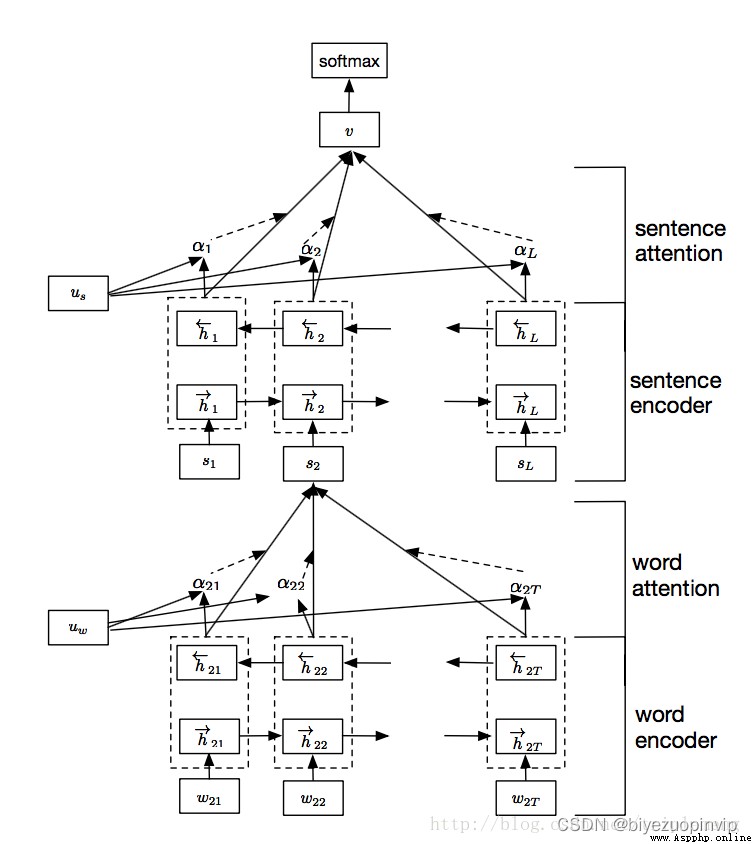
網絡由四個部分組成:word sequence layer, word-attention layer, sentence sequence layer, and sentence-attention layer
如果沒有圖中的 uw(詞語級別的 context vector)和 us(句子級別的 context vector),這個模型也沒有什麼特殊的地方。它無非是由 word sequence layer 和 sentence sequence layer 組成的一個簡單的層級的 sequence 模型而已。而有了這兩個 context vector, 我們就可以利用它們產生 attention layer, 求出每個詞語和每個句子的任務相關程度。
具體做法如下,針對每一個句子,用 sequence model, 就是雙向的 rnn 給表達出來,在這裡用的是 GRU cell。每個詞語對應的 hidden vector 的輸出經過變換(affine+tanh)之後和 uwuw 相互作用(點積),結果就是每個詞語的權重。加權以後就可以產生整個 sentence 的表示。從高一級的層面來看(hierarchical 的由來),每個 document 有 L 個句子組成,那麼這 L 個句子就可以連接成另一個 sequence model, 同樣是雙向 GRU cell 的雙向 rnn,同樣的對輸出層進行變換後和 us 相互作用,產生每個句子的權重,加權以後我們就產生了對整個 document 的表示。最後用 softmax 就可以產生對分類的預測。
每次的“提問”,都是由 uw 和 us 來實現的,它們用來找到高權重的詞語和句子。下面看看實現。
下面是我用 tensorflow 的實現。具體見我的 github:
word-sequence 和 sentence-sequence 都通過下面這個 module 實現。
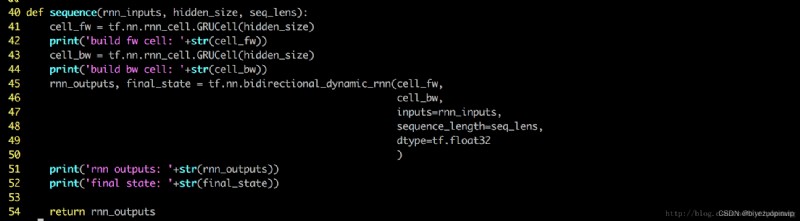
這裡使用了雙向的 dynamic 的 rnn,實際上 static 的 rnn 效果也不錯
不同的 IMDB 的 reviews 大小不一樣,有的包含了幾十個句子,有的只包含了幾個句子, 為了讓 rnn 模型更加精確,我把每個 batch 內部的 review 的實際長度(review 所包含的句子個數)存在了 seq_lens 裡面。這樣在調用 bidirectional_dynamic_rnn 時,rnn 精確的知道計算該在哪裡停止。
word-attention 和 sentence-attention 都通過調用這個 module 來實現
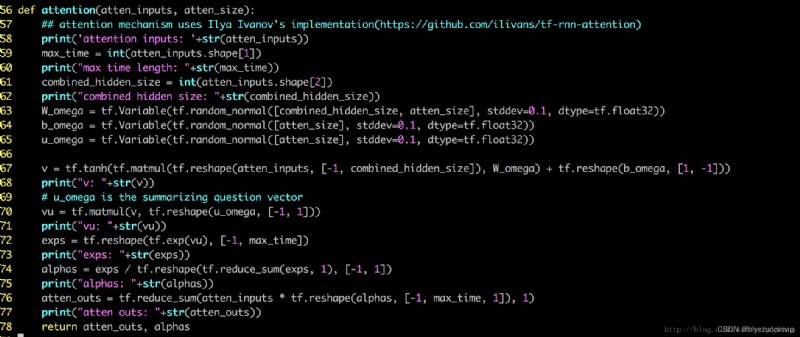
注意第 65 行 uw 就是我們說的 context vector (我在第 69 行把它稱之為 summarizing question vector)
根據原 paper 的做法,利用 data 先 pretrain 了 word embeddings sequence 層之後加了 dropout, 用處不甚明顯。
最大的 review 長度控制在 15 個句子, 每個句子的長度固定為 70。
最後的大概精度是 0.9 左右。我現在的計算資源非常有限,所以不能實驗太多別的參數。
以下是幾個例子。紅色的深度代表句子對於 review 的 sentiment 的重要性,黃色的深度代表詞語對於句子的重要性。
0 代表 negative, 1 代表 positive


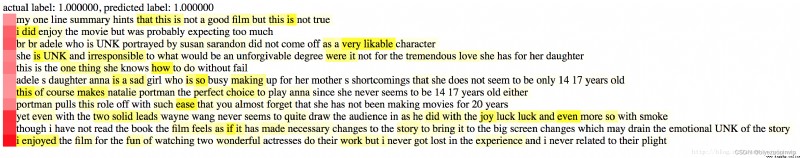
總結一下: 這種 intra-attention 機制很有創意,也挺有效。根據我不完全的實驗,hierarchical attention model 明顯好於其他的比如 stacked bi-directional RNN, CNN text(Yoon Kim 的版本)。 說不完全是因為我的計算資源非常有限,我只是實現了這些模型,沒有仔細的調參, 而且我只對 2-class 的 IMDB 作了實驗。 所以上面的結論不夠嚴謹,僅供參考。
我當然相信 attention 的效果,但是比較無法忍受 sequence model 的速度。最近新的突破(SRU)或許能夠大幅度提升 sequence model 的效率,但是我還是想試試 CNN+attention, 原因是一來比較看好 CNN 的速度,而來 attention 可以一定程度上彌補 CNN 在長程相關性上的缺陷。
https://zhuanlan.zhihu.com/p/26892711
在 componet 裡面定義了 sequence 和 attention 兩個模塊
在 models 裡面 build graph 的時候,
先用一個 embeddings 對詞進行向量化詞編碼器,reshape 之後得到 word_rnn_inputs_formatted,作為 sequence 的輸入,
word_rnn_outputs = sequence(word_rnn_inputs_formatted, hidden_size, None)
在 sequence 模塊中用雙向的 GRU 網絡,可以將正向和反向的上下文信息結合起來,獲得隱藏層輸出。
然後把隱藏層拼在一起 atten_inputs = tf.concat(word_rnn_outputs, 2),作為 attention 模塊的輸入。
後面句子層面類似
向的上下文信息結合起來,獲得隱藏層輸出。
然後把隱藏層拼在一起 atten_inputs = tf.concat(word_rnn_outputs, 2),作為 attention 模塊的輸入。