目錄
哈喽O(∩_∩)O??
什麼是正則表達式(⊙_⊙)
簡單說,正則表達式是…
正則表達式怎麼用?
sreach的用法??
匹配連續的多個數值??
?字符"+"重復前面一個匹配字符一次或者多次??
字符"*"重復前面一個匹配字符零次或者多次??
字符"?"重復前面一個匹配字符零次或者一次??
特殊字符使用反斜槓"“引導,例如” “、” “、” “、”"分別表示回車、換行、制表符號與反斜線自己本身
?
?完整表??
?match用法??
match用法??
?match對象??
數量詞??
匹配開頭、結尾??
?
?匹配分組??
match總結??
實踐出真知 凸(`0′)凸 ??
寫在最後??
今天來發一下python正則表達式,其實這個也是比較簡單的
肝了好幾個小時才寫出來呀
目前越來越多的網站、編輯器、編程語言都已支持一種叫“正則表達式”的字符串查找“公式”,有過編程經驗的同學都應該了解正則表達式(Regular Expression 簡寫regex)是什麼東西,它是一種字符串匹配的模式(pattern),更像是一種邏輯公式。
python中必備的工具,主要是用來查找和匹配字符串的。
正則表達式尤其在python爬蟲上用的多。
首先,我們要導入頭文件(寫c++寫習慣了)模塊
import re
因為re是內置模塊,所以不需要額外安裝,就很銀杏

import re
r=r"d+"
m=re.search(r,"YRYR567eruwgf")#目標是567
print(m)
re模塊中,r“d+”正則表達式表示匹配連續的多個數值,search是re中的函數,從"YRYR567eruwgf"字符串中搜索連續的數值,得到"567"
結果:
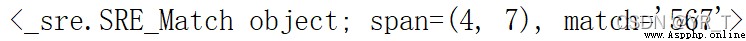
可以看到,搜索到了連續值“567”
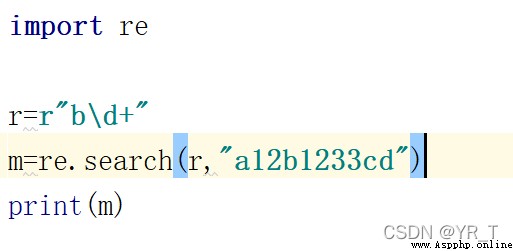
import re
r=r"bd+"
m=re.search(r,"a12b1233cd")
print(m)
這樣,結果就是b後面的連續數字
結果:

“*" 與 "+"類似,但有區別,列如:
可見 r"ab+“匹配的是"ab”,但是r"ab“匹配的是"a”,因為表示"b"可以重復零次,但是”+“卻要求"b"重復一次以上

import re
r=r"ab+"
m=re.search(r,"acabc")
print(m)
r=r"ab*"
m=re.search(r,"acabc")
print(m)
結果:

匹配結果"ab”,重復b一次

import re
r=r"ab?"
m=re.search(r,"abbcabc")
print(m)
結果:


import re
r=r"a
b"
m=re.search(r,"ca
bcaba")
print(m)
結果:

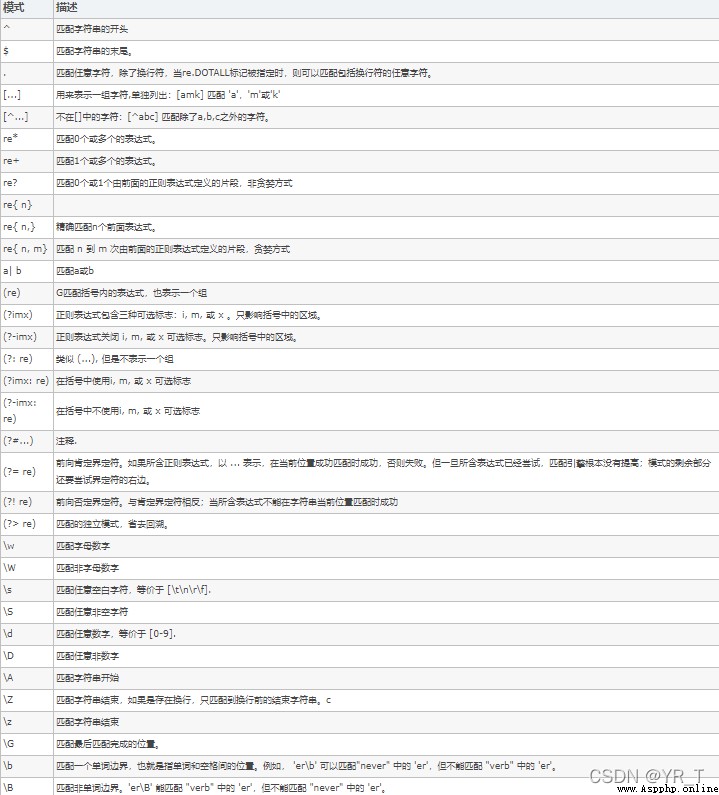
其實上面說這些都是比較基礎,比較簡單的,還有復雜一點的,都在這張表裡
語法:re.match(pattern, string[, flags])
從首字母開始開始匹配,string如果包含pattern子串,則匹配成功,返回Match對象,失敗則返回None,若要完全匹配,pattern要以$結尾。
#示例:
name='張三'
if re.match('張w+',name):
print('{},你好!'.format(name))
# 張三,你好!
輸出結果:張三,你好

張三:誰叫我?
不開玩笑了,繼續
總的來說,match就是
Match對象的幾個屬性:
注意,前面是有“.”的
1..string 待匹配的文本
2..re 匹配使用的pattern對象
3..pos 正則表達式搜索文本的開始位置
4..endpos 正則表達式搜索文本的結束位置
Match對象的幾個方法:
1.group(0) 返回匹配到的子串
2.start() 返回匹配子串的開始位置
3.end() 返回匹配子串的結束位置
4.span() 返回start()、end()



好了,看了上面幾張表,其實我覺得最重要的在下面
其實沒啥好總結的,但你要看懂這張圖,這個很重要

我框出來的是我自己感覺經常用的
其實我自己剛學的時候也聽不懂,現在覺得可簡單了
所以,你應該現在就覺得很簡單吧?
但是,正則表達式的字符很多,容易記混,一不小心就好幾十個報錯,很讓人崩潰

學了這麼多,是不是想撸個程序了?
已經給你准備好了
程序效果:輸入手機號,通過正則表達式判斷手機號合不合法,
如果合法,就輸出這個手機號的信息(所屬地等)
如果不合法,就重新輸入,簡單吧?
這裡我想重點說一下怎麼獲取手機號的信息
我一開始打算上網上百度一波的,沒想到直接復制過來23個報錯、我也是醉了

哎呀,不能再發表情包了

ε=(′ο`*)))唉,還是自己寫吧、、、
我想起了有個模塊叫phone,可以實現這個功能
但是你可能還沒有安裝這個模塊,要按命令行模式下輸入pip install phone
等個六六四十九秒就下載下來了
然後你就可以體驗一下了
代碼(PyCharm運行通過)
import phone
from time import *
import re
def begin():
print("歡迎來到查詢小程序")
print("1.查詢")
print("2.用戶")
def p(n):
if re.match(r'1[3,4,5,7,8]d{9}', n):
if re.match(r'13[0,1,2]d{8}', n) or
re.match(r"15[5,6]d{8}", n) or
re.match(r"18[5,6]", n) or
re.match(r"145d{8}", n) or
re.match(r"176d{8}", n):
return True
elif re.match(r"13[4,5,6,7,8,9]d{8}", n) or
re.match(r"147d{8}|178d{8}", n) or
re.match(r"15[0,1,2,7,8,9]d{8}", n) or
re.match(r"18[2,3,4,7,8]d{8}", n):
return True
else:
return True
else:
return False
if __name__ == "__main__":
s=0
begin()
while True:
op = int(input("請輸入:"))
if op==1:
phoneNum = str(input("請輸入你的電話號碼"))
if p(phoneNum)==False:
print("該手機號無效")
for i in range(100):
print('
')
begin()
else:
info = phone.Phone().find(phoneNum)
print("手機號碼:"+str(info["phone"]))
print("手機所屬地:"+str(info["province"])+"省"+str(info["city"])+"市")
print("郵政編號:"+str(info["zip_code"]))
print("區域號碼:"+str(info["area_code"]))
print("手機類型:"+str(info["phone_type"]))
s+=1
i = input("輸入任意數退出...")
for i in range(100):
print('
')
begin()
if op==2:
print("使用次數:"+str(s))
i = input("輸入任意數退出...")
for i in range(100):
print('
')
begin()
感覺這次的博客好像比較長,你能看到這裡,已經超越了60%的人了,如果有誰還不是很明白,或者有c++和python的問題,都可以私信我,我看到後會一一回復哦

另外,互粉必回??
感謝您的閱讀,拜拜!