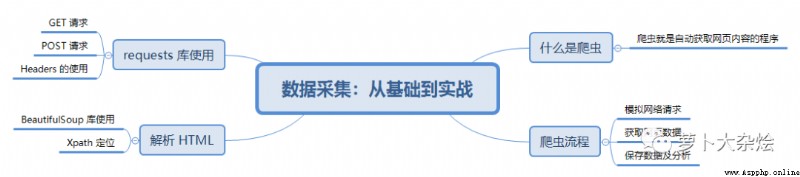
其實在當今社會,網絡上充斥著大量有用的數據,我們只需要耐心的觀察,再加上一些技術手段,就可以獲取到大量的有價值數據。這裡的“技術手段”就是網絡爬蟲。今天就給大家分享一篇爬蟲基礎知識和入門教程:
爬蟲就是自動獲取網頁內容的程序,例如搜索引擎,Google,Baidu 等,每天都運行著龐大的爬蟲系統,從全世界的網站中爬蟲數據,供用戶檢索時使用。
其實把網絡爬蟲抽象開來看,它無外乎包含如下幾個步驟
那麼我們該如何使用 Python 來編寫自己的爬蟲程序呢,在這裡我要重點介紹一個 Python 庫:Requests。
Requests 庫是 Python 中發起 HTTP 請求的庫,使用非常方便簡單。
模擬發送 HTTP 請求
發送 GET 請求
當我們用浏覽器打開豆瓣首頁時,其實發送的最原始的請求就是 GET 請求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
<Response [200]>
<class 'requests.models.Response'>
可以看到,我們得到的是一個 Response 對象
如果我們要獲取網站返回的數據,可以使用 text 或者 content 屬性來獲取
text:是以字符串的形式返回數據
content:是以二進制的方式返回數據
print(type(res.text))
print(res.text)
>>>
<class 'str'> <!DOCTYPE HTML>
<html lang="zh-cmn-Hans" class="">
<head>
<meta charset="UTF-8">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<meta name="description" content="提供圖書、電影、音樂唱片的推薦、評論和價格比較,以及城市獨特的文化生活。">
<meta name="keywords" content="豆瓣,廣播,登陸豆瓣">.....
發送 POST 請求
對於 POST 請求,一般就是提交一個表單
r?=?requests.post('http://www.xxxx.com',?data={"key":?"value"})
data 當中,就是需要傳遞的表單信息,是一個字典類型的數據。
header 增強
對於有些網站,會拒絕掉沒有攜帶 header 的請求的,所以需要做一些 header 增強。比如:UA,Cookie,host 等等信息。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "your cookie"}
2020-10-25 14:56·數據分析不是個事兒
其實在當今社會,網絡上充斥著大量有用的數據,我們只需要耐心的觀察,再加上一些技術手段,就可以獲取到大量的有價值數據。這裡的“技術手段”就是網絡爬蟲。今天就給大家分享一篇爬蟲基礎知識和入門教程:
爬蟲就是自動獲取網頁內容的程序,例如搜索引擎,Google,Baidu 等,每天都運行著龐大的爬蟲系統,從全世界的網站中爬蟲數據,供用戶檢索時使用。
其實把網絡爬蟲抽象開來看,它無外乎包含如下幾個步驟
那麼我們該如何使用 Python 來編寫自己的爬蟲程序呢,在這裡我要重點介紹一個 Python 庫:Requests。
Requests 庫是 Python 中發起 HTTP 請求的庫,使用非常方便簡單。
模擬發送 HTTP 請求
發送 GET 請求
當我們用浏覽器打開豆瓣首頁時,其實發送的最原始的請求就是 GET 請求
import?requests
res?=?requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
<Response?[200]>
<class?'requests.models.Response'>
可以看到,我們得到的是一個 Response 對象
如果我們要獲取網站返回的數據,可以使用 text 或者 content 屬性來獲取
text:是以字符串的形式返回數據
content:是以二進制的方式返回數據
print(type(res.text))
print(res.text)
>>>
<class?'str'>?<!DOCTYPE?HTML>
<html?lang="zh-cmn-Hans"?class="">
<head>
<meta?charset="UTF-8">
<meta?name="google-site-verification"?content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw"?/>
<meta?name="description"?content="提供圖書、電影、音樂唱片的推薦、評論和價格比較,以及城市獨特的文化生活。">
<meta?name="keywords"?content="豆瓣,廣播,登陸豆瓣">.....
發送 POST 請求
對於 POST 請求,一般就是提交一個表單
r?=?requests.post('http://www.xxxx.com',?data={"key":?"value"})
data 當中,就是需要傳遞的表單信息,是一個字典類型的數據。
header 增強
對於有些網站,會拒絕掉沒有攜帶 header 的請求的,所以需要做一些 header 增強。比如:UA,Cookie,host 等等信息。
header?=?{"User-Agent":?"Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/76.0.3809.100?Safari/537.36",
?????????"Cookie":?"your?cookie"}
res?=?requests.get('http://www.xxx.com',?headers=header)
解析 HTML
現在我們已經獲取到了網頁返回的數據,即 HTML 代碼,下面就需要解析 HTML,來提取其中有效的信息。
BeautifulSoup
BeautifulSoup 是 Python 的一個庫,最主要的功能是從網頁解析數據。
from bs4 import BeautifulSoup # 導入 BeautifulSoup 的方法
# 可以傳入一段字符串,或者傳入一個文件句柄。一般都會先用 requests 庫獲取網頁內容,然後使用 soup 解析。
soup = BeautifulSoup(html_doc,'html.parser') # 這裡一定要指定解析器,可以使用默認的 html,也可以使用 lxml。
print(soup.prettify()) # 按照標准的縮進格式輸出獲取的 soup 內容。
BeautifulSoup 的一些簡單用法
print(soup.title) # 獲取文檔的 title
print(soup.title.name) # 獲取 title 的 name 屬性
print(soup.title.string) # 獲取 title 的內容
print(soup.p) # 獲取文檔中第一個 p 節點
print(soup.p['class']) # 獲取第一個 p 節點的 class 內容
print(soup.find_all('a')) # 獲取文檔中所有的 a 節點,返回一個 list
print(soup.find_all('span', attrs={'style': "color:#ff0000"})) # 獲取文檔中所有的 span 且 style 符合規則的節點,返回一個 list
具體的用法和效果,我會在後面的實戰中詳細說明。
XPath 定位
XPath 是 XML 的路徑語言,是通過元素和屬性進行導航定位的。幾種常用的表達式
表達式含義node選擇 node 節點的所有子節點/從根節點選取//選取所有當前節點.當前節點…父節點@屬性選取text()當前路徑下的文本內容
一些簡單的例子
xpath('node') # 選取 node 節點的所有子節點
xpath('/div') # 從根節點上選取 div 元素
xpath('//div') # 選取所有 div 元素
xpath('./div') # 選取當前節點下的 div 元素
xpath('//@id') # 選取所有 id 屬性的節點
當然,XPath 非常強大,但是語法也相對復雜,不過我們可以通過 Chrome 的開發者工具來快速定位到元素的 xpath,如下圖
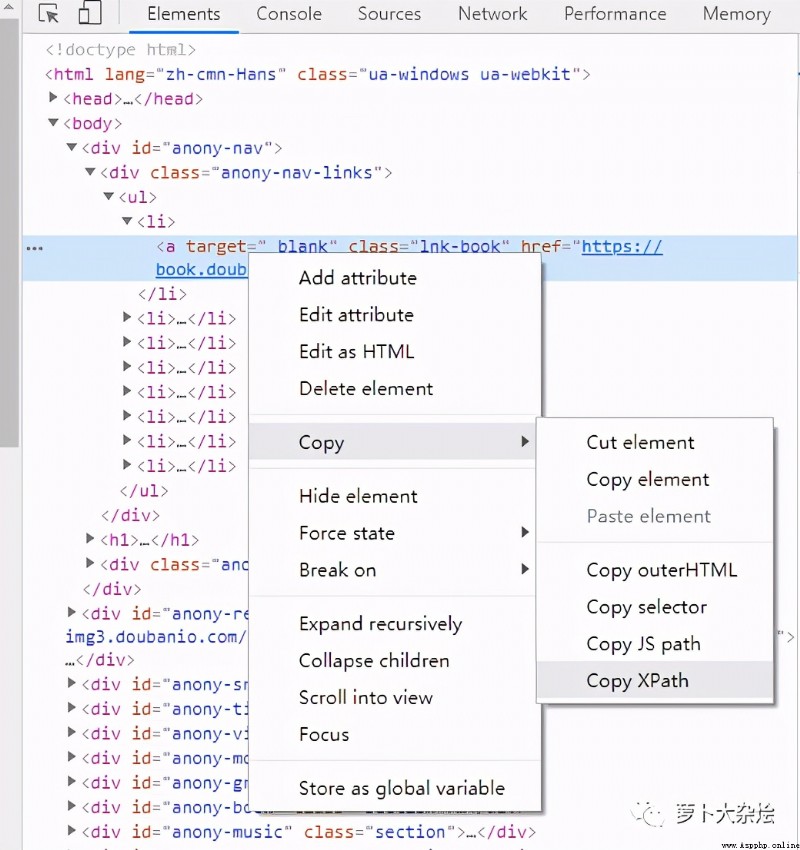
得到的 xpath 為
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
在實際的使用過程中,到底使用 BeautifulSoup 還是 XPath,完全取決於個人喜好,哪個用起來更加熟練方便,就使用哪個。
我們可以從豆瓣影人頁,進入都影人對應的影人圖片頁面,比如以劉濤為例子,她的影人圖片頁面地址為
https://movie.douban.com/celebrity/1011562/photos/
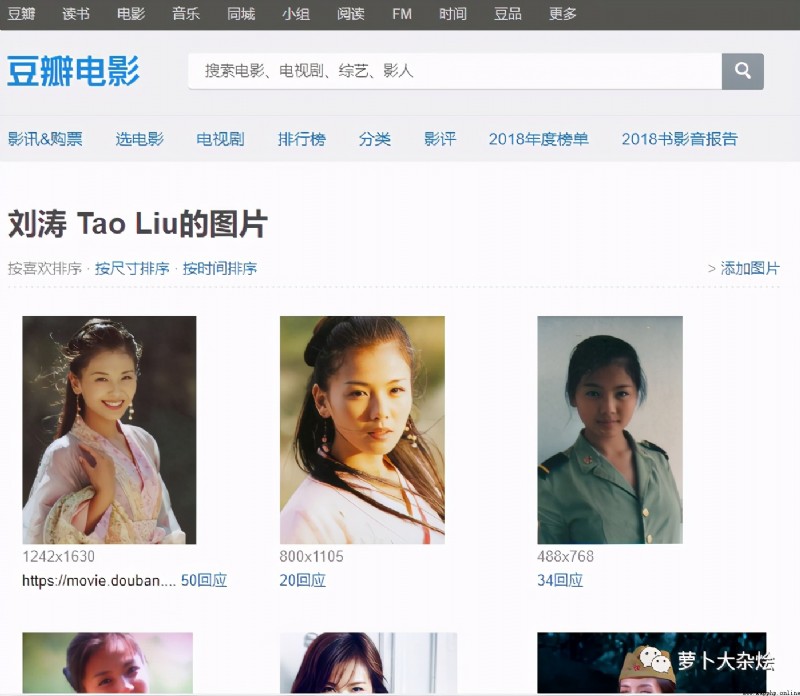
下面我們就來分析下這個網頁
注意:網絡上的網站頁面構成總是會變化的,所以這裡你需要學會分析的方法,以此類推到其他網站。正所謂授人以魚不如授人以漁,就是這個原因。
Chrome 開發者工具(按 F12 打開),是分析網頁的絕佳利器,一定要好好使用。
我們在任意一張圖片上右擊鼠標,選擇“檢查”,可以看到同樣打開了“開發者工具”,而且自動定位到了該圖片所在的位置
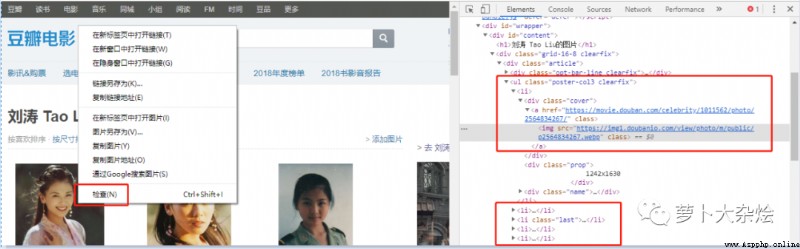
可以清晰的看到,每張圖片都是保存在 li 標簽中的,圖片的地址保存在 li 標簽中的 img 中。
知道了這些規律後,我們就可以通過 BeautifulSoup 或者 XPath 來解析 HTML 頁面,從而獲取其中的圖片地址。
我們只需要短短的幾行代碼,就能完成圖片 url 的提取
import?requests
from?bs4?import?BeautifulSoup?
url?=?'https://movie.douban.com/celebrity/1011562/photos/'
res?=?requests.get(url).text
content?=?BeautifulSoup(res,?"html.parser")
data?=?content.find_all('div',?attrs={'class':?'cover'})
picture_list?=?[]
for?d?in?data:
????plist?=?d.find('img')['src']
????picture_list.append(plist)
print(picture_list)
>>>
['https://img1.doubanio.com/view/photo/m/public/p2564834267.jpg',?'https://img1.doubanio.com/view/photo/m/public/p860687617.jpg',?'https://img1.doubanio.com/view/photo/m/public/p2174001857.jpg',?'https://img1.doubanio.com/view/photo/m/public/p1563789129.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2363429946.jpg',?'https://img1.doubanio.com/view/photo/m/public/p2382591759.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2363269182.jpg',?'https://img1.doubanio.com/view/photo/m/public/p1959495269.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2356638830.jpg',?'https://img3.doubanio.com/view/photo/m/public/p1959495471.jpg',?'https://img3.doubanio.com/view/photo/m/public/p1834379290.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2325385303.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2361707270.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2325385321.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2196488184.jpg',?'https://img1.doubanio.com/view/photo/m/public/p2186019528.jpg',?'https://img1.doubanio.com/view/photo/m/public/p2363270277.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2325240501.jpg',?'https://img1.doubanio.com/view/photo/m/public/p2258657168.jpg',?'https://img1.doubanio.com/view/photo/m/public/p2319710627.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2319710591.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2311434791.jpg',?'https://img1.doubanio.com/view/photo/m/public/p2363270708.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2258657185.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2166193915.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2363265595.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2312085755.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2311434790.jpg',?'https://img3.doubanio.com/view/photo/m/public/p2276569205.jpg',?'https://img1.doubanio.com/view/photo/m/public/p2165332728.jpg']
可以看到,是非常干淨的列表,裡面存儲了海報地址。
但是這裡也只是一頁海報的數據,我們觀察頁面發現它有好多分頁,如何處理分頁呢。
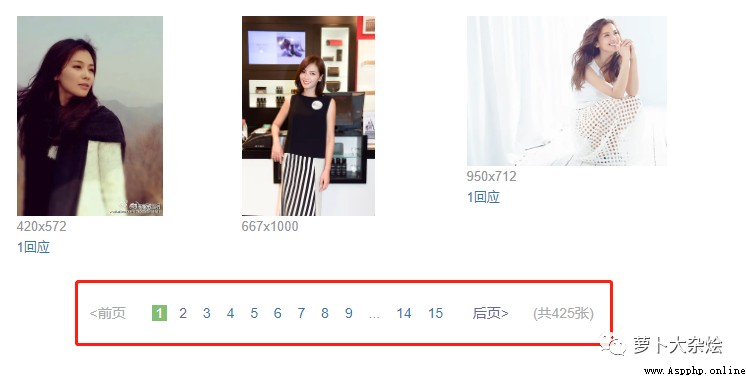
我們點擊第二頁,看看浏覽器 url 的變化
https://movie.douban.com/celebrity/1011562/photos/type=C&start=30&sortby=like&size=a&subtype=a
發現浏覽器 url 增加了幾個參數
再點擊第三頁,繼續觀察 url
https://movie.douban.com/celebrity/1011562/photos/type=C&start=60&sortby=like&size=a&subtype=a
通過觀察可知,這裡的參數,只有 start 是變化的,即為變量,其余參數都可以按照常理來處理
同時還可以知道,這個 start 參數應該是起到了類似於 page 的作用,start = 30 是第二頁,start = 60 是第三頁,依次類推,最後一頁是 start = 420。
於是我們處理分頁的代碼也呼之欲出了
首先將上面處理 HTML 頁面的代碼封裝成函數
def?get_poster_url(res):
????content?=?BeautifulSoup(res,?"html.parser")
????data?=?content.find_all('div',?attrs={'class':?'cover'})
????picture_list?=?[]
????for?d?in?data:
????????plist?=?d.find('img')['src']
????????picture_list.append(plist)
????return?picture_list
然後我們在另一個函數中處理分頁和調用上面的函數
def?fire():
????page?=?0
????for?i?in?range(0,?450,?30):
????????print("開始爬取第?%s 頁"?%?page)
????????url?=?'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
????????res?=?requests.get(url).text
????????data?=?get_poster_url(res)
????????page?+=?1
此時,我們所有的海報數據都保存在了 data 變量中,現在就需要一個下載器來保存海報了
def?download_picture(pic_l):
????if?not?os.path.exists(r'picture'):
????????os.mkdir(r'picture')
????for?i?in?pic_l:
????????pic?=?requests.get(i)
????????p_name?=?i.split('/')[7]
????????with?open('picture\'?+?p_name,?'wb')?as?f:
????????????f.write(pic.content)
再增加下載器到 fire 函數,此時為了不是請求過於頻繁而影響豆瓣網的正常訪問,設置 sleep time 為1秒
def?fire():
????page?=?0
????for?i?in?range(0,?450,?30):
????????print("開始爬取第?%s 頁"?%?page)
????????url?=?'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
????????res?=?requests.get(url).text
????????data?=?get_poster_url(res)
????????download_picture(data)
????????page?+=?1
????????time.sleep(1)
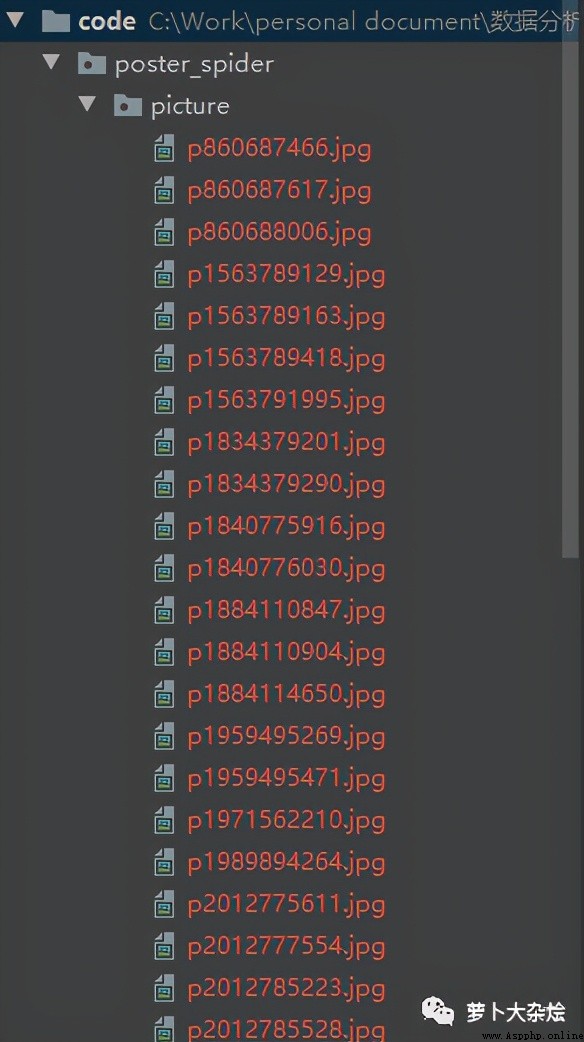
下面就執行 fire 函數,等待程序運行完成後,當前目錄下會生成一個 picture 的文件夾,裡面保存了我們下載的所有海報
下面再來看下完整的代碼
import?requests
from?bs4?import?BeautifulSoup
import?time
import?osdef?fire():
????page?=?0
????for?i?in?range(0,?450,?30):
????????print("開始爬取第?%s 頁"?%?page)
????????url?=?'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
????????res?=?requests.get(url).text
????????data?=?get_poster_url(res)
????????download_picture(data)
????????page?+=?1
????????time.sleep(1)def?get_poster_url(res):
????content?=?BeautifulSoup(res,?"html.parser")
????data?=?content.find_all('div',?attrs={'class':?'cover'})
????picture_list?=?[]
????for?d?in?data:
????????plist?=?d.find('img')['src']
????????picture_list.append(plist)
????return?picture_listdef?download_picture(pic_l):
????if?not?os.path.exists(r'picture'):
????????os.mkdir(r'picture')
????for?i?in?pic_l:
????????pic?=?requests.get(i)
????????p_name?=?i.split('/')[7]
????????with?open('picture\'?+?p_name,?'wb')?as?f:
????????????f.write(pic.content)if?__name__?==?'__main__':
????fire()
fire 函數
這是一個主執行函數,使用 range 函數來處理分頁。
get_poster_url 函數
這個就是解析 HTML 的函數,使用的是 BeautifulSoup
download_picture 函數
簡易圖片下載器
本節講解了爬蟲的基本流程以及需要用到的 Python 庫和方法,並通過一個實際的例子完成了從分析網頁,到數據存儲的全過程。其實爬蟲,無外乎模擬請求,解析數據,保存數據。
當然有的時候,網站還會設置各種反爬機制,比如 cookie 校驗,請求頻度檢查,非浏覽器訪問限制,JS 混淆等等,這個時候就需要用到反反爬技術了,比如抓取 cookie 放到 headers 中,使用代理 IP 訪問,使用 Selenium 模擬浏覽器等待方式。
由於本課程不是專門的爬蟲課,這些技能就留待你自己去探索挖掘啦。
作為過來人,跟大家聊一聊我的自學心得,希望可以幫助大家少走彎路,少踩坑。
更多Python、爬蟲、人工智能配套視頻教程+書籍可以+v 免費領取。

對方向選擇、學習規劃、學習路線、職業發展方面有問題的可以加群:809160367

先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦