基於Python實現ID3算法 演示視頻
目錄
一、作業任務
二、 運行環境
三、算法介紹
四、程序分析
制作數據集:
輸出決策樹結果
可視化決策樹:
五、 界面截圖與分析
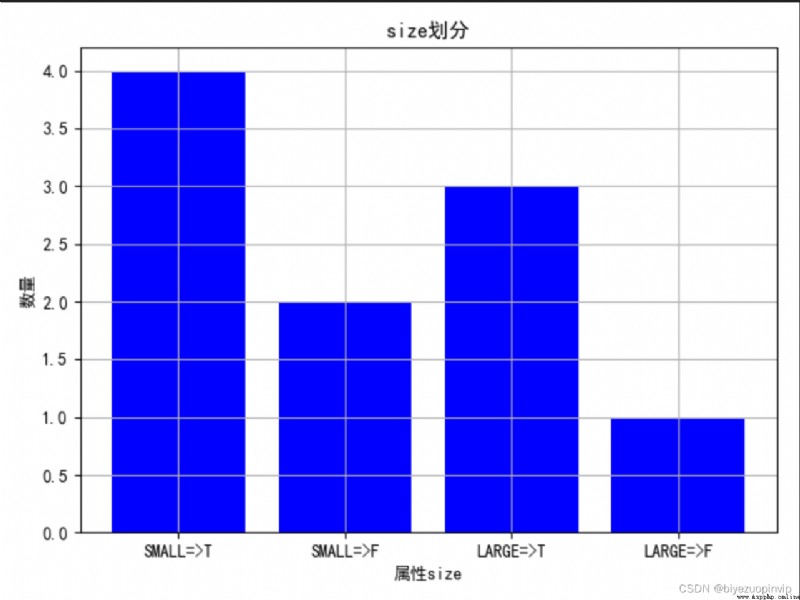
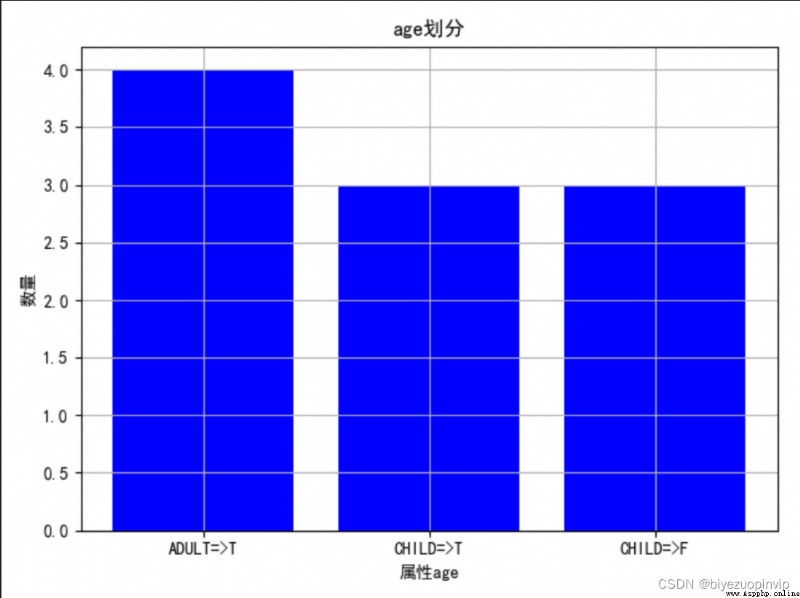
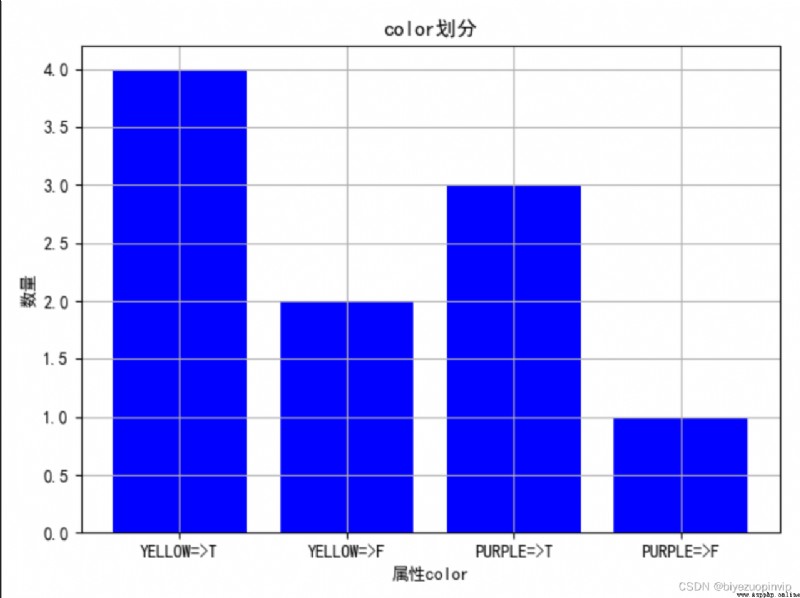
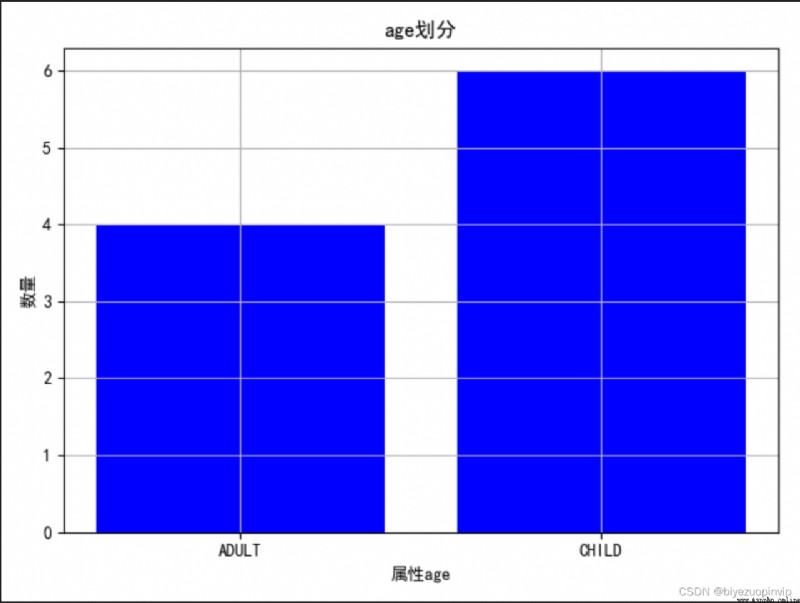
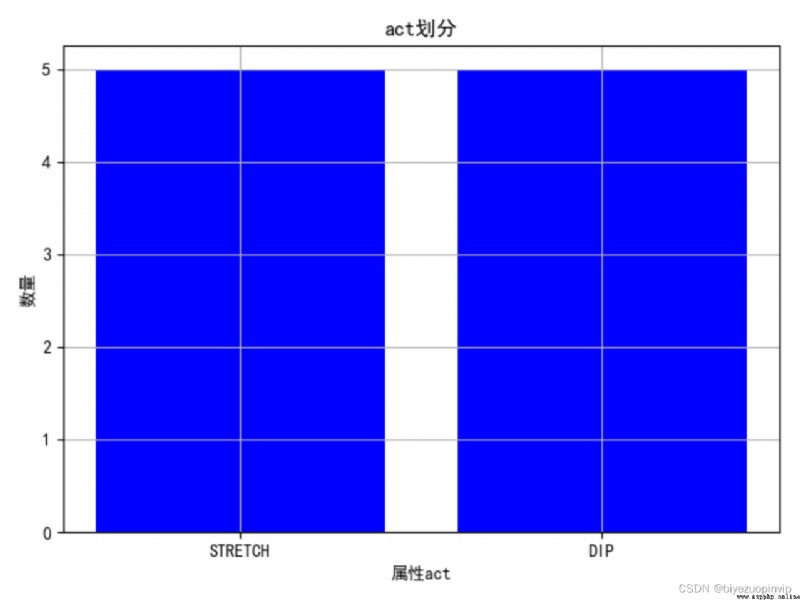
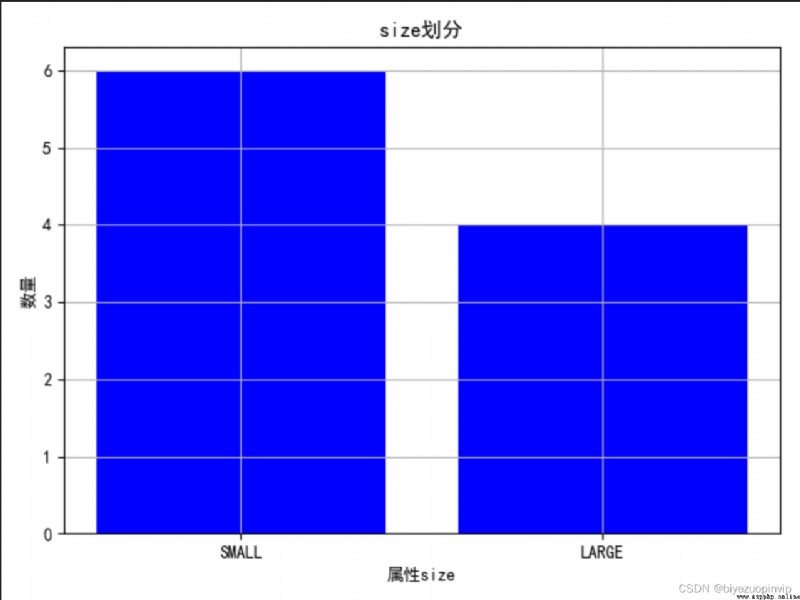
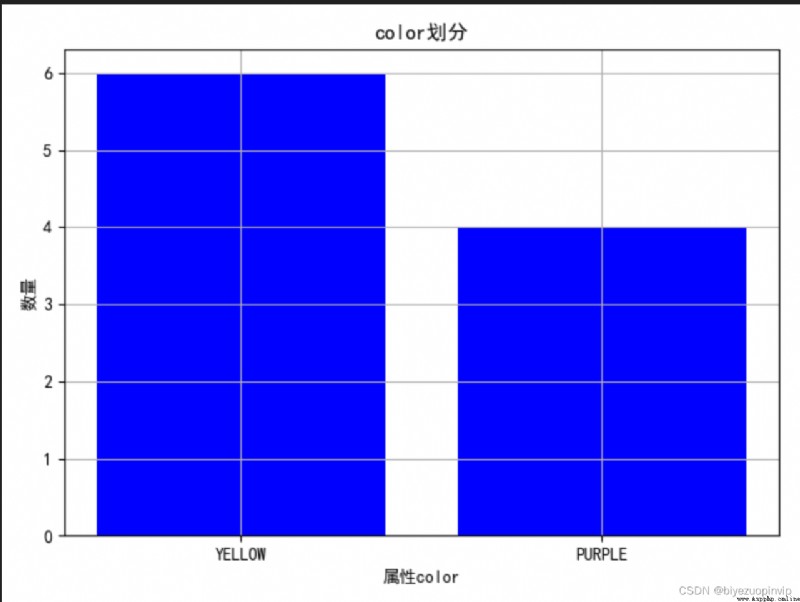
1.通過圖來大致觀察一下不同屬性的劃分情況:
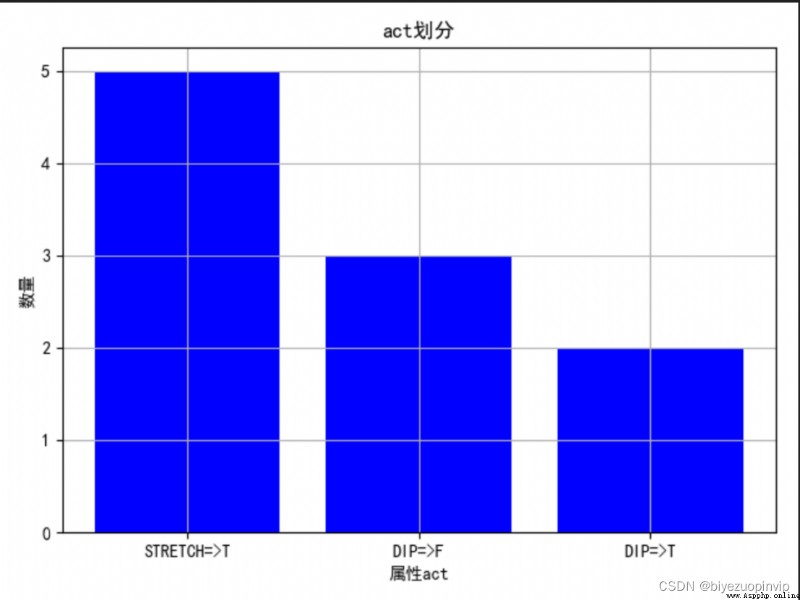
2.查看屬性對於結果的劃分影響:
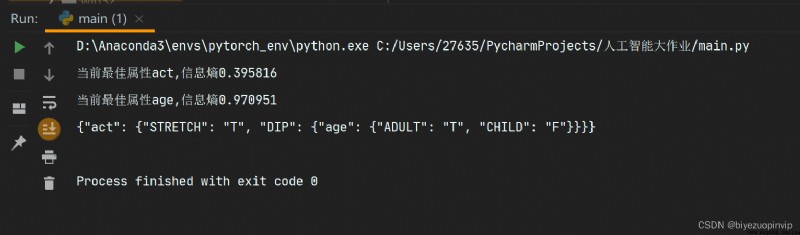
3.程序運行控制台輸出結果:
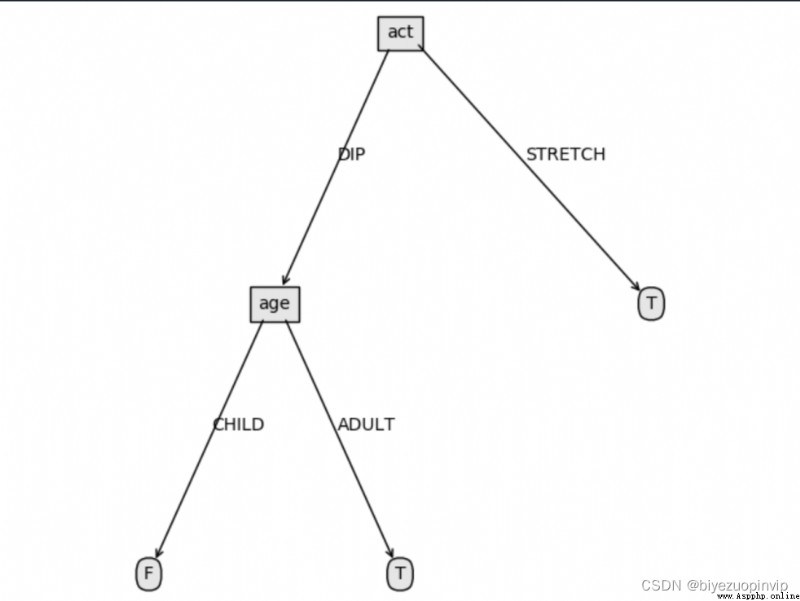
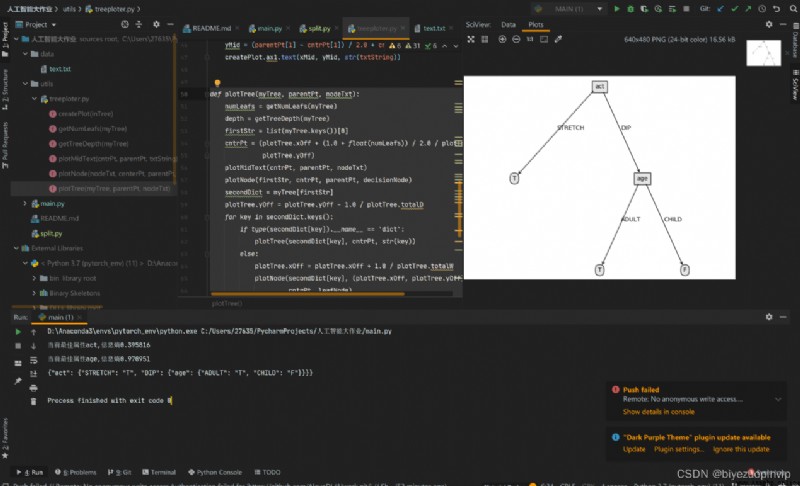
4.決策樹可視化結果:
六、心得體會
七、參考資料
八、附錄
代碼
一、作業任務
1.編程實現ID3算法,針對下表數據,生成決策樹。
問題提示:可設計數據文件格式,如color屬性取值YELLOW:0,PURPLE:1等,程序從指定數據文件中讀取訓練集數據。
問題拓展:要求將計算各屬性信息增益過程及決策樹生成過程演示出來。
二、運行環境
編程語言:Python
使用第三方庫:Numpy,Matplotlib,Scikit-learn
IDE:PyCharm
操作系統:WIndows10
決策樹(decision tree)是一個樹結構(可以是二叉樹或非二叉樹)。其每個非葉節點表示一個特征屬性上的測試,每個分支代表這個特征屬性在某個值域上的輸出,而每個葉節點存放一個類別。使用決策樹進行決策的過程就是從根節點開始,測試待分類項中相應的特征屬性,並按照其值選擇輸出分支,直到到達葉子節點,將葉子節點存放的類別作為決策結果。引用《機器學習》(西瓜書)中的例子:
本文轉載自:http://www.biyezuopin.vip/onews.asp?id=16531
from math import log
import operator # 此行加在文件頂部
import json
from utils.treeploter import *
# 計算信息熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet) # 樣本數
labelCounts = {
}
for featVec in dataSet: # 遍歷每個樣本
currentLabel = featVec[-1] # 當前樣本的類別
if currentLabel not in labelCounts.keys(): # 生成類別字典
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts.keys(): # 計算信息熵
prob = float(labelCounts[key]) / numEntries
shannonEnt = shannonEnt - prob * log(prob, 2)
# print("屬性%s 信息熵為%f"%(key,shannonEnt))
return shannonEnt
# 劃分數據集,axis:按第幾個屬性劃分,value:要返回的子集對應的屬性值
def splitDataSet(dataSet, axis, value):
retDataSet = []
featVec = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 選擇最好的數據集劃分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 # 屬性的個數
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures): # 對每個屬性技術信息增益
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) # 該屬性的取值集合
newEntropy = 0.0
for value in uniqueVals: # 對每一種取值計算信息增益
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain): # 選擇信息增益最大的屬性
bestInfoGain = infoGain
bestFeature = i
return bestFeature,bestInfoGain
# 通過排序返回出現次數最多的類別
def majorityCnt(classList):
classCount = {
}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(),
key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 遞歸構建決策樹
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet] # 類別向量
if classList.count(classList[0]) == len(classList): # 如果只有一個類別,返回
return classList[0]
if len(dataSet[0]) == 1: # 如果所有特征都被遍歷完了,返回出現次數最多的類別
return majorityCnt(classList)
bestFeat,bestGain = chooseBestFeatureToSplit(dataSet) # 最優劃分屬性的索引
bestFeatLabel = labels[bestFeat] # 最優劃分屬性的標簽
print("當前最佳屬性%s,信息熵%f" % (bestFeatLabel,bestGain))
myTree = {
bestFeatLabel: {
}}
del (labels[bestFeat]) # 已經選擇的特征不再參與分類
featValues = [example[bestFeat] for example in dataSet]
uniqueValue = set(featValues) # 該屬性所有可能取值,也就是節點的分支
for value in uniqueValue: # 對每個分支,遞歸構建樹
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(
splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
if __name__ == '__main__':
fr = open(r'data/text.txt')
listWm = [inst.strip().split(',')[1:] for inst in fr.readlines()[1:]]
# print(listWm)
fr.close()
fr = open(r'data/text.txt')
labels = fr.readlines()[0].split(',')[1:]
Trees = createTree(listWm, labels)
fr.close()
print(json.dumps(Trees, ensure_ascii=False))
createPlot(Trees)