Although at present dask,cudf Wait for the bag to appear , So that our data processing has been greatly accelerated , But not everyone has better gpu, A lot of friends are still using pandas tool kit , But sometimes it's really helpless ,pandas Many of the questions we need to use apply Function to handle , and apply Functions are very slow , In this article, we will introduce how to accelerate apply function 600 Double skill .
Experimental comparison
We use Apply For example , The original Apply The function handles the following problem , need 18.4s Time for .
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(0, 11, size=(1000000, 5)), columns=('a','b','c','d','e'))
def func(a,b,c,d,e):
if e == 10:
return c*d
elif (e < 10) and (e>=5):
return c+d
elif e < 5:
return a+b
%%time
df['new'] = df.apply(lambda x: func(x['a'], x['b'], x['c'], x['d'], x['e']), axis=1)
CPU times: user 17.9 s, sys: 301 ms, total: 18.2 s
Wall time: 18.4 sBecause the processing is parallel , So we can use it Swift Accelerate , In the use of Swift after , The same operation can be upgraded to... On my machine 7.67s.
%%time # !pip install swifter import swifter df['new'] = df.swifter.apply(lambda x : func(x['a'],x['b'],x['c'],x['d'],x['e']),axis=1) HBox(children=(HTML(value='Dask Apply'), FloatProgress(value=0.0, max=16.0), HTML(value=''))) CPU times: user 329 ms, sys: 240 ms, total: 569 ms Wall time: 7.67 s
Use Pandas and Numpy The quickest way is to vectorize the function . If our operation can be vectorized directly , So we try to avoid using :
After transforming the above problem into the following treatment , Our time is shortened to :421 ms.
%%time df['new'] = df['c'] * df['d'] #default case e = =10 mask = df['e'] < 10 df.loc[mask,'new'] = df['c'] + df['d'] mask = df['e'] < 5 df.loc[mask,'new'] = df['a'] + df['b'] CPU times: user 134 ms, sys: 149 ms, total: 283 ms Wall time: 421 ms
Let's convert the above categories into int16 type , Then perform the same vectorization operation , The discovery time is shortened to :116 ms.
for col in ('a','b','c','d'):
df[col] = df[col].astype(np.int16)
%%time
df['new'] = df['c'] * df['d'] #default case e = =10
mask = df['e'] < 10
df.loc[mask,'new'] = df['c'] + df['d']
mask = df['e'] < 5
df.loc[mask,'new'] = df['a'] + df['b']
CPU times: user 71.3 ms, sys: 42.5 ms, total: 114 ms
Wall time: 116 msCan be transformed into .values Where possible, turn into .values, Do it again .
therefore , The above operation time is shortened to :74.9ms.
%%time df['new'] = df['c'].values * df['d'].values #default case e = =10 mask = df['e'].values < 10 df.loc[mask,'new'] = df['c'] + df['d'] mask = df['e'].values < 5 df.loc[mask,'new'] = df['a'] + df['b'] CPU times: user 64.5 ms, sys: 12.5 ms, total: 77 ms Wall time: 74.9 ms
Through some of the above tips , We will simply Apply The function accelerates hundreds of times , Concrete :
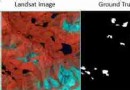 Ice lake extraction algorithm based on bimodal threshold segmentation (implemented in Python)
Ice lake extraction algorithm based on bimodal threshold segmentation (implemented in Python)
One 、 background This algorit
 About Python using face on MAC_ Recognize error oserror: dlopen (libc.so.6, 6): image not found
About Python using face on MAC_ Recognize error oserror: dlopen (libc.so.6, 6): image not found
Find and edit the file venv/li