要完成本次任務,我們需要導入requests來獲取對應網址的數據,導入re利用正則表達式來截取所需的數據(例如電影名,評分以及評分人數等),導入prettytable來格式化輸出,導入csv模塊將數據寫入csv文件中。具體導入模塊代碼如下所示:
import requests
import re
import prettytable as pd
import csv
由於我們使用requests一次只能請求一頁的排行榜數據,一頁一共有25條電影的數據,而我們要獲取Top250的數據,所以一共要獲取10頁的數據。因為我們要發現其分頁的規律,從而來使用循環來自動獲取每一頁的數據並寫入文件。通過點擊對應頁數的鏈接,便可以很輕松發現其中的規律,具體每一頁的網址鏈接情況如下所示: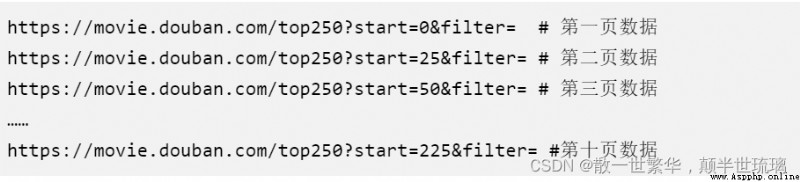
因此,我們可以使用一個for循環便可以實現依次訪問每一頁的鏈接數據,具體如下所示:
for i in range(10):
url = 'https://movie.douban.com/top250?start='+str(25*i)+'&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Mobile Safari/537.36'
}
response = requests.get(url, headers=headers)
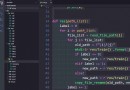
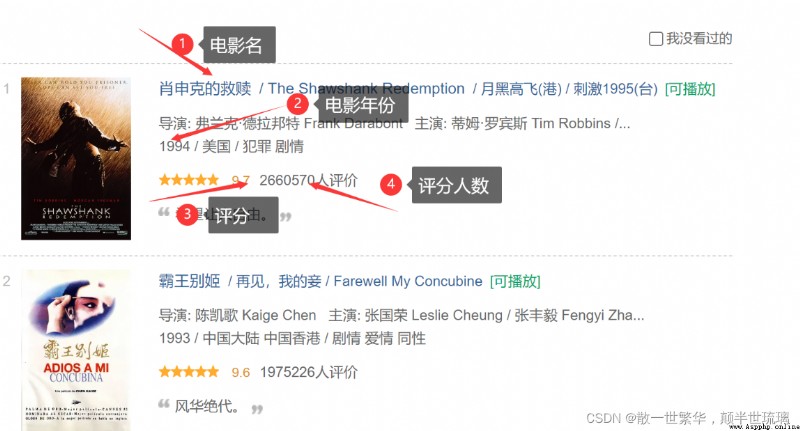
正如下圖所示,我們需要的是電影名,電影年份,電影評分以及電影評分人數,在對應的網址頁面按下F12或者直接右鍵點擊檢查打開開發者工具,選擇下圖所示的圖標後,然後點擊需要爬取的信息內容,這樣我們就可以在眾多冗余的代碼中找到我們所需要的信息所在的位置。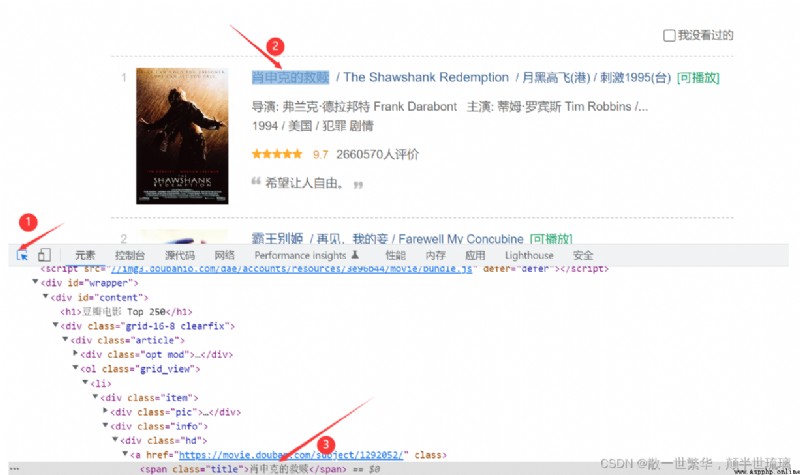
找到對應信息所在的位置後,我們就可以根據其層級關系來編寫正則表達式獲取所需要的內容了。具體編寫的正則表達式代碼如下所示:
p = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<year>.*?) '
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)</span>', re.S)
for it in p.finditer(response.text):
print(it.group('name'))
print(it.group('year'))
print(it.group('score'))
print(it.group('num'))
這裡需要注意,編寫正則表達式需要注意大小寫,如果不想注意大小寫,我們可以設置re.I使得對大小寫不敏感,compile()函數的第二個參數是設置一些可選標志修飾符來控制匹配的模式,修飾符被指定為一個可選的標志,多個標志可以通過按位OR(|)來指定,如(re.I)|(re.M)被設置為I和M標志。具體修飾符以及描述如下表所示:
這一部分知識錦上添花的作用,並無實際作用,可以作為拓展知識學習,如果不敢興趣可以直接跳過!這一部分就相當於是把通過正則表達式截取的數據,使用prettytable做到格式化輸出,使得輸出效果更好,具體操作代碼如下所示:
# 格式化輸出
table = pd.PrettyTable()
# 設置表頭
table.field_names = ['電影名', '年份', '評分', '評分人數']
for it in p.finditer(response.text):
# 添加表數據
table.add_row([it.group('name'), it.group('year').strip(), it.group('score'), it.group('num')])
print(table)
運行效果如下所示: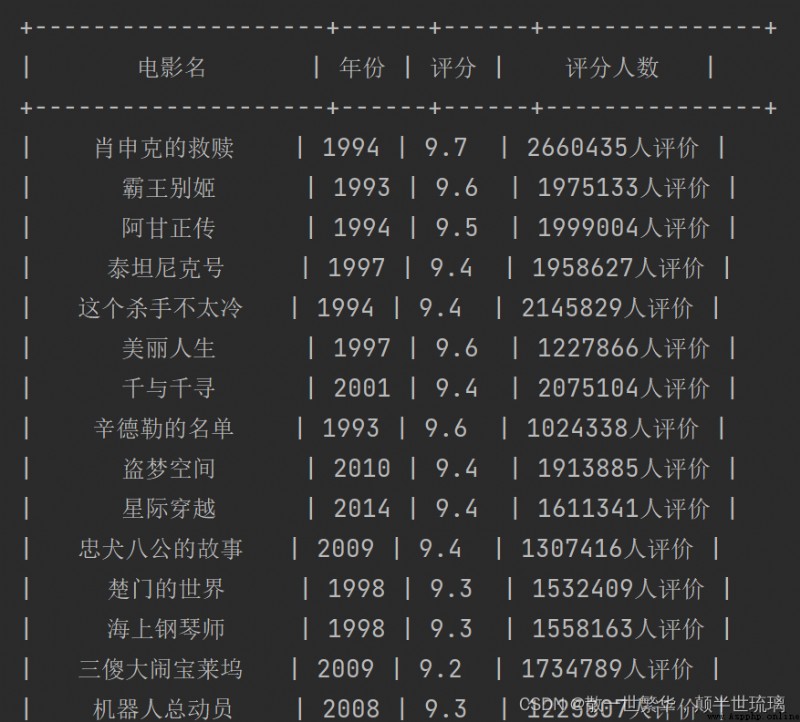
這一部分代碼比較簡單,就不做過多的贅述,主要就是打開文件代碼如下所示:
# 以追加的形式打開文件對象
f = open('data.csv', mode='a')
csv_write = csv.writer(f)
for it in p.finditer(response.text):
# 將迭代器it轉換為字典
dic = it.groupdict()
# 對鍵為year的值去除空格
dic['year'] = dic['year'].strip()
# 將字典的values寫入data.csv
csv_write.writerow(dic.values())
print('寫入完成')
這裡需要注意,如果寫入csv的文件在PyCharm不能正常展示,我們可以去下載一個CSV插件,這裡就可以在PyCharm中正常顯示數據了。具體操作步驟如下所示:
鼠標選擇文件,點擊下面的設置
打開設置,出現下面的界面後,選擇插件,在搜索框中輸入CSV,在下面出現的插件中選擇正確的CSV閱讀器,點擊安裝最後重啟即可。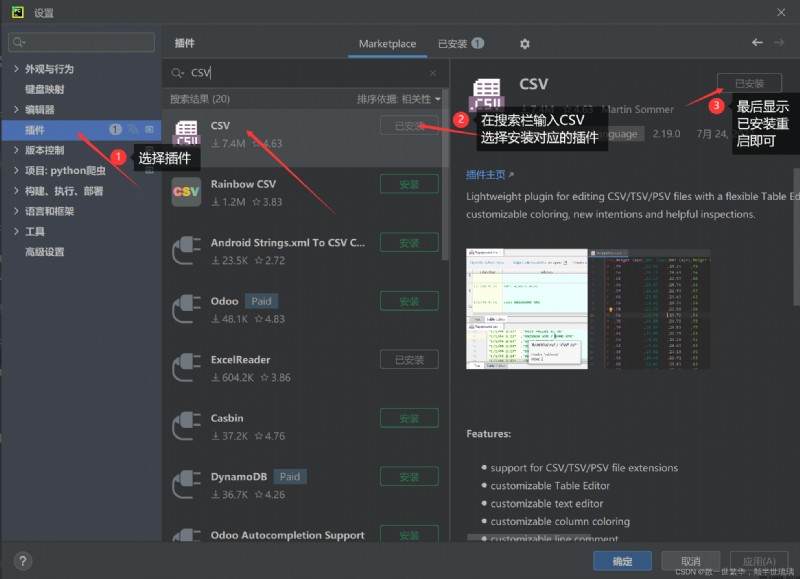
import requests
import re
import prettytable as pd
import csv
for i in range(10):
# 評分排行榜的網址
url = 'https://movie.douban.com/top250?start='+str(25*i)+'&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Mobile Safari/537.36'
}
response = requests.get(url, headers=headers)
result = response.text
p = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<year>.*?) '
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)</span>', re.S)
# 格式化輸出
table = pd.PrettyTable()
# 設置表頭
table.field_names = ['電影名', '年份', '評分', '評分人數']
for it in p.finditer(result):
# 添加表數據
table.add_row([it.group('name'), it.group('year').strip(), it.group('score'), it.group('num')])
print(table)
# 以追加的形式打開文件
f = open('data.csv', mode='a')
csv_write = csv.writer(f)
for it in p.finditer(result):
# 將迭代器it轉換為字典
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csv_write.writerow(dic.values())
print('寫入完成')