Today, let's take a look at some tips of the reptile process, or some attention or pits , Because bloggers are just getting started , So it is also to share some learned objects , Then the first pit : When browsing the web, we often see such things :
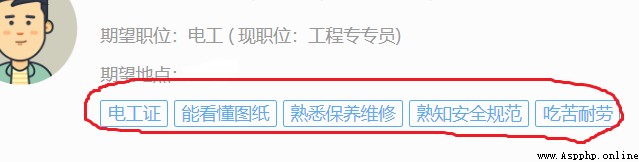
That is, the so-called multi label , Let's take a look at its corresponding HTML structure , open F12( If you press F12 Nothing happened , You can read the first article of the blogger )
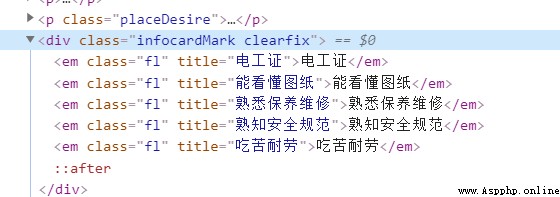
You can find , This information is nested in a HTML Under the , The information in the figure is located in <div class = "infocardMark clearfix"></div> In the label , So how do we get this information , At this time, we can only analyze div.infocardMark.clearfix This floor ( Using the browser Copy selector Method can obtain ), By the way, let's talk about it here , Bloggers use Google browser , Of course , You can also use Firefox or something , There are corresponding F12 Interface , And then use stripped_strings Method , The explanation is like this :
stripped_strings: Used to get all descendant non label strings under the target path , Will automatically remove the blank string , The return is a generator
Then the specific use of this case can be as follows :
date = soup.select('div.infocardMark.clearfix')
for info in zip(date):
print(list(info.stripped_strings))
If you encounter :AttributeError: 'tuple' object has no attribute 'stripped_strings', You need to analyze the structure of tuples first , Then take the specific elements and use them
stripped_strings Method , For example, you can try to use list(info[0].stripped_strings) Try it , Of course, this is a code modification based on the analysis of errors and data .
Then the second question is , Sometimes we will for various reasons , such as : The data of the web page is through js Control the transmitted , At this time, we need to analyze js Is relatively troublesome , Then we can try the black technology of Google browser (p≧w≦q), stay F12 Then we can simulate the way of mobile phones to view web pages , Because of adaptation , Sometimes it is a relatively simple method to obtain information by using mobile pages , How do you do that ? First of all, I want to briefly talk about , Something that initiates a request ( In fact, bloggers don't know very well , But I will speak rudely ), When we initiate a service request URL outside , In fact, some message headers should be added ( Request header ) Information about , But we didn't report the header before, and we can access the network normally , Specifically, you can check the information by yourself , Here is a brief introduction about how to check the message header , And how to use . First , Definitely F12 了 : And then switch to Network, choice XHR, Select the first request , Click on Headers, Then the message header that transmits the information is request Headers in , forehead ... Well, here are these things :
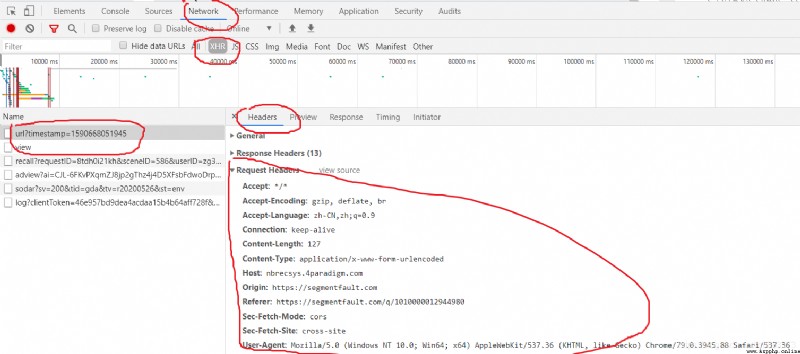
So what's the use of knowing this information , Hey , Two aspects , For example, your login information can rely on here Request Headers Get the information in , Then put it in the link , So your request has identity information , Um. .... How to put it? , That is to say, our previous requests are only in the form of tourists , If we want to make a request in our logged in state , You can start from Request Headers To find clues , ok , If the important thing is Headers Medium Cookie( Check the specific information ), It is the object of recording our identity .......... Okay , If you don't say much, you'd better say that you'll get to the point , How can we imitate mobile login , At this time, I need to click the icon of that mobile phone , That's it :
Click Finish , You can switch between different mobile phone models for access , Is it exciting (p≧w≦q)( Well, I'm not excited .....):
With these preparations , Let's go back to F12 Check again in request headers Information in ,
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36
User-Agent:
Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1
The first is for normal use Windows Information when accessing , The second is simulation Iphone Information when accessing , You can rest assured that changes have taken place , With this information, we can visit the website as follows :
It's going on request Let's define before requesting header, Then specify headers that will do :
header = {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
wb_data = requests.get(url,headers = header )
If you need to add login information , You need to log in first , Then go to check Headers Medium Cookie, stay header It is specified in Cookie The corresponding information is just .