數據源:
一個啤酒的數據源,為了方便演示,數據只有20行。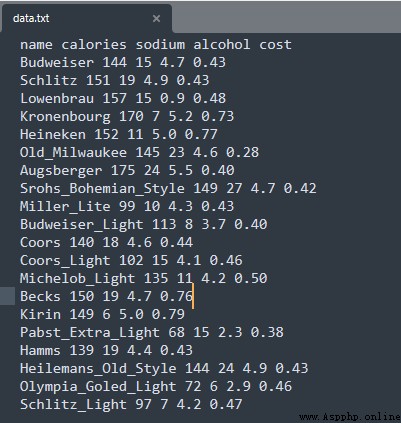
代碼:
import pandas as pd
from sklearn.cluster import DBSCAN
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
# 讀取數據源
beer = pd.read_csv('E:/file/data.txt', sep=' ')
X = beer[["calories","sodium","alcohol","cost"]]
# 訓練數據源
db = DBSCAN(eps=10, min_samples=2).fit(X)
# 加上標簽
labels = db.labels_
beer['cluster_db'] = labels
beer.sort_values('cluster_db')
# 畫圖
colors = np.array(['red', 'green', 'blue', 'yellow'])
pd.scatter_matrix(X, c=colors[beer.cluster_db], figsize=(10,10), s=100)
plt.show()
# 驗證模型效果
score_scaled = metrics.silhouette_score(X,beer.cluster_db)
print("使用DBSCAN的模型效果:")
print(score_scaled)
測試記錄:
使用DBSCAN的模型效果:
0.49530955296776086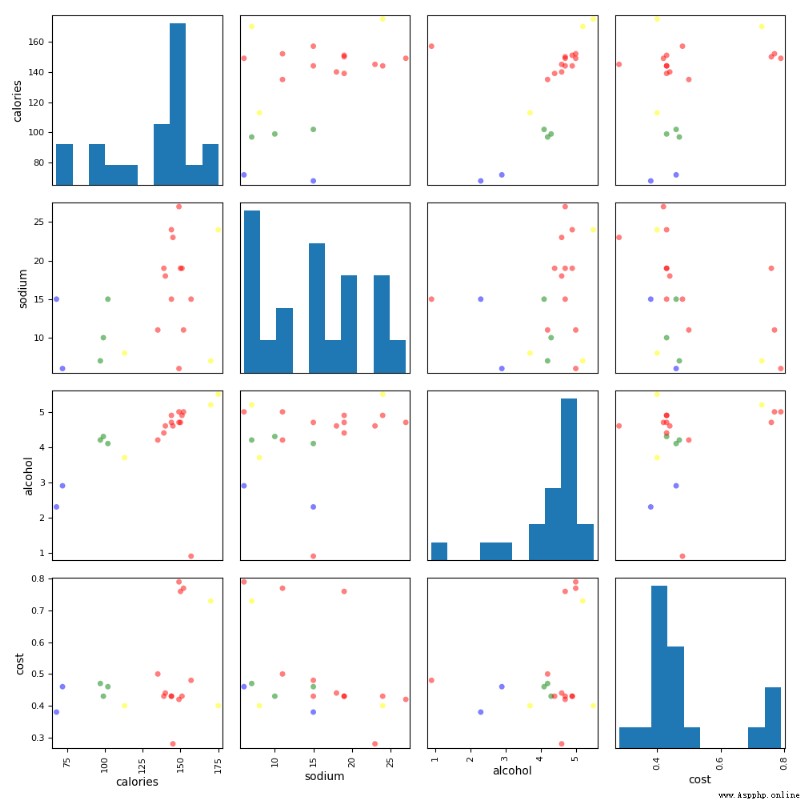
分析:
從評分及可視化效果來看,聚類效果不理想,不如K-Means效果。
對於樣本集復雜的使用DBSCAN。
對於樣本集簡單的直接使用K-Means即可。