在數據挖掘項目的數據中,數據類型可以分為兩種:有序的連續數值 和 無序的類別型特征。
對於xgboost、GBDT等boosting樹模型,基學習通常是cart回歸樹,而cart樹的輸入通常只支持連續型數值類型的,像年齡、收入等連續型變量Cart可以很好地處理,但對於無序的類別型變量(如 職業、地區等),cart樹處理就麻煩些了,如果是直接暴力地枚舉每種可能的類別型特征的組合,這樣找類別特征劃分點計算量也很容易就爆了。
在此,本文列舉了 樹模型對於類別型特征處理的常用方法,並做了深入探討~喜歡記得點贊、收藏、關注。
注意:文末有技術交流方法
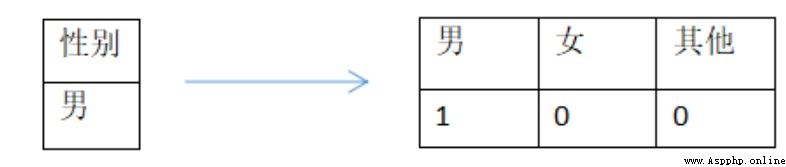 我們可以直接對類別型特征做Onehot處理(這也是最常用的做法),每一類別的取值都用單獨一位0/1來表示, 也就是一個“性別”類別特征可以轉換為是否為“男”、“女” 或者“其他” 來表示,如下:
我們可以直接對類別型特征做Onehot處理(這也是最常用的做法),每一類別的取值都用單獨一位0/1來表示, 也就是一個“性別”類別特征可以轉換為是否為“男”、“女” 或者“其他” 來表示,如下:
display(df.loc[:,['Gender_Code']].head())
# onehot
pd.get_dummies(df['Gender_Code']).head()
但是onehot的重大缺點在於,對於取值很多的類別型特征,可能導致高維稀疏特征而容易導致樹模型的過擬合。如之前談到面對高維稀疏的onehot特征,一旦有達到劃分條件,樹模型容易加深,切分次數越多,相應每個切分出的子特征空間的統計信息越來越小,學習到的可能只是噪音(即 過擬合)。
使用建議:Onehot天然適合神經網絡模型,神經網絡很容易從高維稀疏特征學習到低微稠密的表示。當onehot用於樹模型時,類別型特征的取值數量少的時候還是可以學習到比較重要的交互特征,但是當取值很多時候(如 大於100),容易導致過擬合,是不太適合用onehot+樹模型的。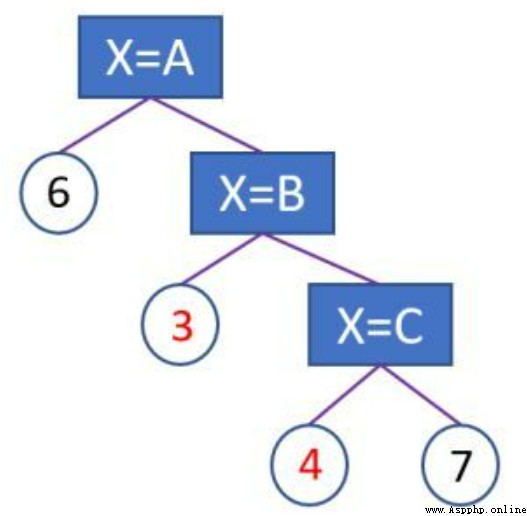 (注:此外 onehot 還有增加內存開銷以及訓練時間開銷等缺點)
(注:此外 onehot 還有增加內存開銷以及訓練時間開銷等缺點)
OrdinalEncoder也稱為順序編碼 (與 label encoding,兩者功能基本一樣),特征/標簽被轉換為序數整數(0 到 n_categories - 1)
使用建議:適用於ordinal feature ,也就是雖然類別型特征,但它存在內在順序,比如衣服尺寸“S”,“M”, “L”等特征就適合從小到大進行整數編碼。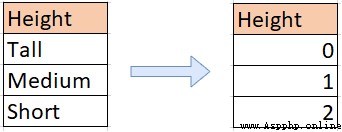
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df[col] = encoder.transform(df[col])
target encoding 目標編碼也稱為均值編碼,是借助各類別特征對應的標簽信息做編碼(比如二分類 簡單以類別特征各取值 的樣本對應標簽值“0/1”的平均值),是一種常用有監督編碼方法(此外還有經典的WoE編碼),很適合邏輯回歸等弱模型使用。
使用建議 : 當樹模型使用目標編碼,需加入些正則化技巧,減少Target encoding方法帶來的條件偏移的現象(當訓練數據集和測試數據集數據結構和分布不一樣的時候會出條件偏移問題),主流的方法是使用Catboost編碼 或者 使用cross-validation求出target mean或bayesian mean。

# 如下簡單的target mean代碼。也可以用:from category_encoders import TargetEncoder
target_encode_columns = ['Gender_Code']
target = ['y']
target_encode_df = score_df[target_encode_columns + target].reset_index().drop(columns = 'index', axis = 1)
target_name = target[0]
target_df = pd.DataFrame()
for embed_col in target_encode_columns:
val_map = target_encode_df.groupby(embed_col)[target].mean().to_dict()[target_name]
target_df[embed_col] = target_encode_df[embed_col].map(val_map).values
score_target_drop = score_df.drop(target_encode_columns, axis = 1).reset_index().drop(columns = 'index', axis = 1)
score_target = pd.concat([score_target_drop, target_df], axis = 1)
CatBoostEncoder是CatBoost模型處理類別變量的方法(Ordered TS編碼),在於目標編碼的基礎上減少條件偏移。其計算公式為:
TargetCount : 對於指定類別特征在target value的總和
prior:對於整個數據集而言,target值的總和/所有的觀測變量數目
FeatureCount:觀測的特征列表在整個數據集中的出現次數。
CBE_encoder = CatBoostEncoder()
train_cbe = CBE_encoder.fit_transform(train[feature_list], target)
test_cbe = CBE_encoder.transform(test[feature_list])
也稱為頻數編碼,將類別特征各取值轉換為其在訓練集出現的頻率,這樣做直觀上就是會以類別取值的頻次為依據 劃分高頻類別和低頻類別。至於效果,還是要結合業務和實際場景。
## 也可以直接 from category_encoders import CountEncoder
bm = []
tmp_df=train_df
for k in catefeas:
t = pd.DataFrame(tmp_df[k].value_counts(dropna=True,normalize=True)) # 頻率
t.columns=[k+'vcount']
bm.append(t)
for k,j in zip(catefeas, range(len(catefeas))):# 聯結編碼
df = df.merge(bm[j], left_on=k, right_index=True,how='left')
當類別的取值數量很多時(onehot高維),如果直接onehot,從性能或效果來看都會比較差,這時通過神經網絡embedding是不錯的方法,將類別變量onehot輸入神經網絡學習一個低維稠密的向量,如經典的無監督詞向量表征學習word2vec 或者 基於有監督神經網絡編碼。
使用建議:特別適合類別變量取值很多,onehot後高維稀疏,再做NN低維表示轉換後應用於樹模型。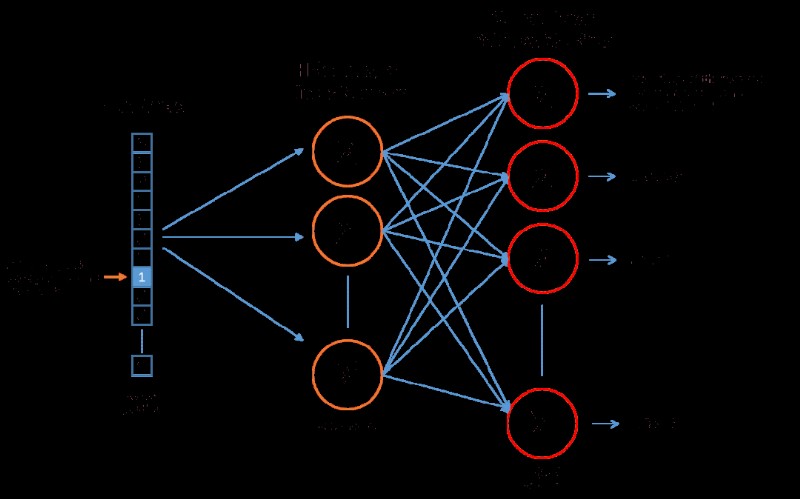
# word2vec
from gensim.models import word2vec
# 加載數據
raw_sentences = ["the quick brown fox jumps over the lazy dogs","yoyoyo you go home now to sleep"]
# 切分詞匯
sentences= [s.encode('utf-8').split() for s in sentences]
# 構建模型
model = word2vec.Word2Vec(sentences,size=10) # 詞向量的維數為10
# 各單詞學習的詞向量
model['dogs']
# array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
為了解決one-hot編碼(one vs many )處理類別特征的不足。lgb采用了Many vs many的切分方式,簡單來說,是通過對每個類別取值進行數值編碼(類似於目標編碼),根據編碼的數值尋找較優切分點,實現了類別特征集合的較優切分。
1 、特征取值數目小於等於4(參數max_cat_to_onehot):直接onehot 編碼,逐個掃描每一個bin容器,找出最佳分裂點;
2、 特征取值數目大於4:max bin的默認值是256 取值的個數大於max bin數時,會篩掉出現頻次少的取值。再統計各個特征值對應的樣本的一階梯度之和,二階梯度之和,以一階梯度之和 / (二階梯度之和 + 正則化系數)作為該特征取值的編碼。將類別轉化為數值編碼後,從大到小排序,遍歷直方圖尋找最優的切分點
簡單來說,Lightgbm利用梯度統計信息對類別特征編碼。我個人的理解是這樣可以按照學習的難易程度為依據劃分類別特征組,比如某特征一共有【狼、狗、貓、豬、兔】五種類別取值,而【狼、狗】類型下的樣本分類難度相當高(該特征取值下的梯度大),在梯度編碼後的類別特征上,尋找較優劃分點可能就是【狼、狗】|vs|【貓、豬、兔】
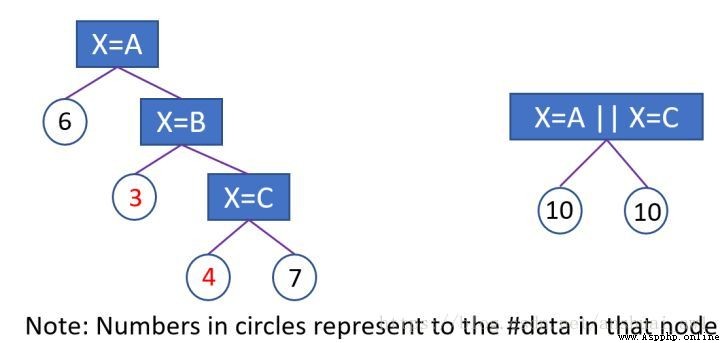
使用建議: 通常使用lgb類別特征處理,效果是優於one-hot encoding,而且用起來也方便。
# lgb類別處理:簡單轉化為類別型特征直接輸入Lgb模型訓練即可。
for ft in category_list:
train_x[ft] = train_x[ft].astype('category')
clf = LGBMClassifier(**best_params)
clf.fit(train_x, train_y)
對於取值數量很少(<10)的類別型特征,相應的各取值下的樣本數量也比較多,可以直接Onehot編碼。
對於取值數量比較多(10到幾百),這時onehot從效率或者效果,都不及lightgbm梯度編碼或catboost目標編碼,而且直接使用也很方便。(需要注意的是,個人實踐中這兩種方法在很多取值的類別特征,還是比較容易過擬合。這時,類別值先做下經驗的合並或者嘗試剔除某些類別特征後,模型效果反而會更好)
當幾百上千的類別取值,可以先onehot後(高維稀疏),借助神經網絡模型做低維稠密表示。
以上就是主要的樹模型對類別特征編碼方法。實際工程上面的效果,還需具體驗證。計算資源豐富的情況下,可以多試幾種編碼方法,再做特征選擇,選取比較有效的特征,效果槓槓的!!
目前開通了技術交流群,群友已超過3000人,添加時最好的備注方式為:來源+興趣方向,方便找到志同道合的朋友,資料獲取也可以加入
方式1、添加微信號:dkl88191,備注:來自CSDN
方式2、微信搜索公眾號:Python學習與數據挖掘,後台回復:加群