“ 用過sql中的row_number函數,習慣了他的方便,那麼在pandas處理數據時,有沒有類似的函數用來排序呢,當然也有,比如rank函數。”
rank(axis=0, method='average', numeric_only=None,
na_option='keep', ascending=True, pct=False)
默認情況下:axis=0表示按索引排序;ascending=True排序按升序排列;pct=False表示不輸出百分比;na_option='keep'表示空值不做處理。
下面將通過數據來學習下rank函數下各參數作用: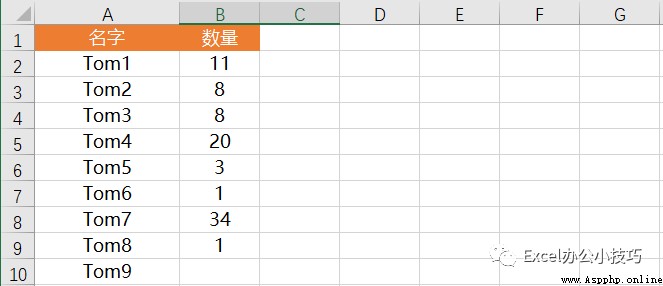
01 method:你想怎麼排
更改參數method的可選項,其他默認參數不更改:
first:表示按數值大小排列,如果數值相同時,按出現先後排序。如1,2,3,4,5,...,類似SQL中的row_number函數;
min:表示按數值大小排列,如果數值相同時,序號相同,但後面的序號仍按數值數目順延,如1,2,2,4,5,...,類似SQL中的rank函數;
dense:表示按數值大小排列,如果數值相同時,序號相同,同時後面的序號不受影響,如1,2,2,3,4,...,類似SQL中的dense_rank函數;
data['first']=data['數量'].rank(method='first' )
data['min']=data['數量'].rank(method='min' )
data['dense']=data['數量'].rank(method='dense')結果如下:
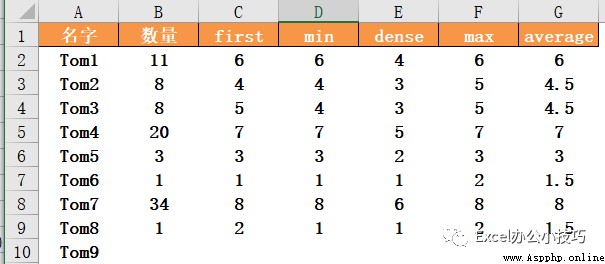
另外兩個可選項,method='max'時,相同的數值,按最大的序號輸出。可以理解成,在first排序結果的基礎上,數值相同時,兩個數值都按最大序號輸出;而method='average'時,兩個數值按對應序號的均值輸出。
02 ascending:誰小誰有理?
上面介紹method我們默認是升序排列,那麼如果數量表示銷售完成的訂單數時,當然是完成的多的才要排前面,所以,ascending=False時,降序排列。
data['降序']=data['數量'].rank(method='min',ascending=False) 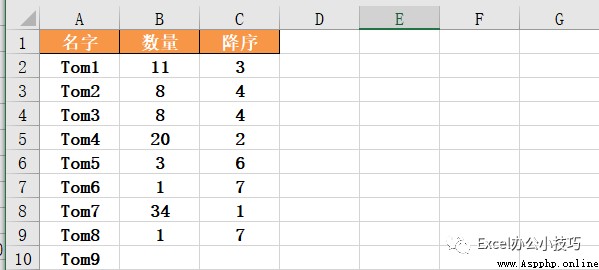
03 na_option:別把數據算丟了!
默認情況下,na_option='keep',空值未被考慮在內,那麼,如果數量表示客服投訴數量時,數量為空的應該是排名最好的。因此,當na_option='top',表示空值排最前,na_option='bottom',表示空值排最後。
data['top']=data['數量'].rank(method='min',na_option='top')
data['bottom']=data['數量'].rank(method='min',na_option='bottom')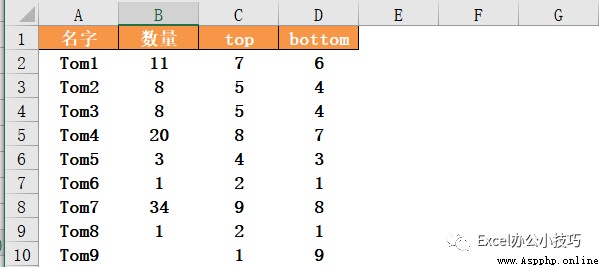
04 pct:算算分布?
pct默認=False,想輸出數值所占的分布情況時,pct=True即可。
data['pct']=data['數量'].rank(method='min',pct=True)結果如下:

備注:以上內容,僅用於學習筆記~
 Python learning 10 -- engineering structure (package, module) & namespace & import module and variable &_ init_. py&_ all_&_ name_
Python learning 10 -- engineering structure (package, module) & namespace & import module and variable &_ init_. py&_ all_&_ name_
1、 Engineering structure ( pac
 Recommended collection. You must master the 15 tips for using Python pip
Recommended collection. You must master the 15 tips for using Python pip
as everyone knows ,pip It can




