均值若a = [5, 6, 16, 9], 則np.mean(a)=9.0np.average(list_a)計算列表list_a的均值若a = [5, 6, 16, 9], 則np.average(a)=9.0np.average(list_a, weights = [1, 2, 1, 1])計算列表list_a的加權平均數若a = [5, 6, 16, 9], 則np.average(a, weights = [1, 2, 1, 1])=8.4np.var(list_a)計算列表list_a的總體方差若a = [5, 6, 16, 9],則np.var(a) =18.5np.var(list_a, ddof = 1)計算列表list_a的樣本方差若a = [5, 6, 16, 9],則np.var(a, ddof = 1) =24.67np.std(list_a)計算列表list_a的總體標准差若a = [5, 6, 16, 9],則np.std(a) =4.3np.std(list_a, ddof = 1)計算列表list_a的樣本標准差若a = [5, 6, 16, 9],則np.std(a, ddof = 1) =4.96np.median(list_a)計算列表list_a的中位數若a = [5, 6, 16, 9], 則np.median(a)=7.5np.mode(list_a)計算列表list_a的眾數若a = [5, 6, 16, 9], 則np.mode(a)=7.5np.percentile(list_a, (25))計算列表list_a的第1四分位數若a = [1,2,3,4,5,6,7,8,9,10,11,12] ,則np.mode(a)=3.75np.percentile(list_a, (50))計算列表list_a的第2四分位數若a = [1,2,3,4,5,6,7,8,9,10,11,12] ,則np.mode(a)=6.5np.percentile(list_a, (75))計算列表list_a的第3四分位數若a = [1,2,3,4,5,6,7,8,9,10,11,12] ,則np.mode(a)=9.25np.percentile(list_a, (25)) - np.percentile(list_a, (75))計算列表list_a的四分位差np.max(list_a) - np.min(list_a))計算列表list_a的極差np.std(list_a)/np.mean(list_a))計算列表list_a的離散系數參考鏈接:數據的離散程度度量:極差、四分位差、平均差、方差、標准差、異眾比率、離散系數
均值:
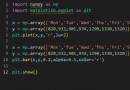
mean方法求得 :import numpy as np
a = [5, 6, 16, 9]
np.mean(a)
>>>
9.0
average 方法也能求得簡單平均數。此外,它也可以求出 加權平均數 。(average 裡面可以跟一個 weights 參數,裡面是一個權數的數組)例如:import numpy as np
a = [5, 6, 16, 9]
np.average(a)
>>>
9.0
# 加權平均數計算:average 裡面可以跟一個 weights 參數,裡面是一個權數的數組
np.average(a, weights = [1, 2, 1, 1])
>>>
8.4
方差:
var 函數,默認參數置空即可;var 函數,但需要跟參數 ddof= 1。典型實例:
示例1(一維):
import pnumpy as np
a = [5, 6, 16, 9]
# 計算總體方差
np.var(a)
>>>
18.5
# 計算樣本方差
np.var(a, ddof = 1)
24.666666666666668
示例2(多維):
b = [[4, 5], [6, 7]]
print(b)
>>>
[[4, 5], [6, 7]]
# 計算矩陣所有元素的方差
np.var(b)
>>>
1.25
# 計算矩陣每一列的方差
np.var(b, axis = 0)
>>>
array([1., 1.])
# 計算矩陣每一行的方差
np.var(b, axis = 1)
>>>
array([0.25, 0.25])
標准差:
std 函數,默認參數置空即可;std 函數,但需要跟參數 ddof= 1。典型實例:
示例1(一維):
import numpy as np
a = [5, 6, 16, 9]
# 計算總體標准差
np.std(a)
>>>
4.301162633521313
# 計算樣本標准差
np.std(a, ddof = 1 )
>>>
4.96655480858378
示例2(多維):
b = [[4, 5], [6, 7]]
# 計算矩陣所有元素的標准差
np.std(b)
>>>
1.118033988749895
# 計算矩陣每一列的標准差
np.std(b, axis = 0)
>>>
array([1., 1.])
# 計算矩陣每一列的標准差
np.std(b, axis = 1)
>>>
array([0.5, 0.5])
對於 pandas ,也可以用裡面的 mean 函數可以求得所有行或所有列的平均數,例如:
import pandas as pd
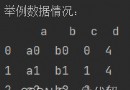
df = pd.DataFrame(np.array([[85, 68, 90], [82, 63, 88], [84, 90, 78]]), columns=['統計學', '高數', '英語'], index=['張三', '李四', '王五'])
df
>>>
統計學 高數 英語
張三 85 68 90
李四 82 63 88
王五 84 90 78
df.mean() # 顯示每一列的平均數
>>>
統計學 83.666667
高數 73.666667
英語 85.333333
dtype: float64
df.mean(axis = 1) # 顯示每一行的平均數
>>>
張三 81.000000
李四 77.666667
王五 84.000000
dtype: float64
若計算 某一行或某一列的平均值,則可以使用 df.iloc 選取該行或該列數據,後面跟 mean 函數就能得到,例如:
df
>>>
統計學 高數 英語
張三 85 68 90
李四 82 63 88
王五 84 90 78
df.iloc[0, :].mean() # 得到第 1 行的平均值
>>>
81.0
df.iloc[:, 2].mean() # 得到第 3 列的平均值
>>>
85.33333333333333
pandas 中的 var 函數可以計算 樣本方差(注意不是總體方差),std 函數可以得到 樣本標准差。
若要得到某一行或某一列的方差,則也可用 df.iloc 選取某行或某列,後面再跟 var 函數或 std 函數即可,例如:
df.var() # 顯示每一列的方差
>>>
統計學 2.333333
高數 206.333333
英語 41.333333
dtype: float64
df.var(axis = 1) # 顯示每一行的方差
>>>
張三 133.000000
李四 170.333333
王五 36.000000
dtype: float64
df.std() # 顯示每一列的標准差
>>>
統計學 1.527525
高數 14.364308
英語 6.429101
dtype: float64
df.std(axis = 1) # 顯示每一行的標准差
>>>
張三 11.532563
李四 13.051181
王五 6.000000
dtype: float64
df.iloc[0, :].std() # 顯示第 1 行的標准差
>>>
11.532562594670797
df.iloc[:, 2].std() # 顯示第 3 列的標准差
>>>
6.429100507328636