截至本文發布,在金山文檔網頁版中,如果需要同時下載2個及以上的文件,則必須開通會員。很容易想到可以編寫爬蟲逐一下載文件以達到批量下載的目的。
通過抓包可以發現這並不復雜,任意選取一個文件並點擊下載,監聽XHR下的數據包,可以捕獲到如下的關鍵數據包:
圖1 單個文件加載數據包響應結果
上圖右側響應結果中的url字段即為文件下載地址,注意該下載地址並不需要處於登錄狀態,任意狀態下都可以訪問下載(但是存在有效期)。
那麼這個事情就很簡單,我們來看一看這個數據包的請求字段:
圖2 單個文件加載數據包請求字段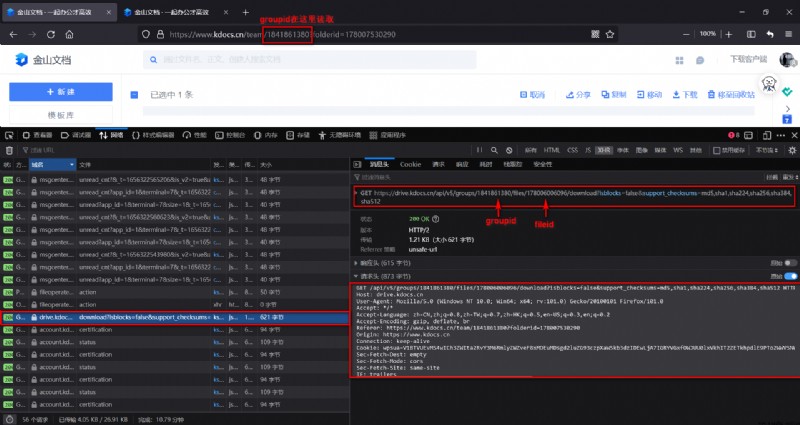
如圖中標注的那樣,上圖請求URL中只有兩個可變字段:groupid與fileid,groupid很容易直接從當前頁面的URL中就可以讀到。fileid則有很多方法可以讀取,事實上當前頁面源代碼中某個<script>標簽下就存儲了所有文件的fileid(存儲在變量window.__API_CACHED__中,直接在控制台中調取window.__API_CACHED__也可以):
圖3 頁面源代碼中的window.API_CACHED
這個window.__API_CACHED__很長,這裡將該<script>標簽下的完整內容取出:
圖4 window.__API_CACHED__完整數據結構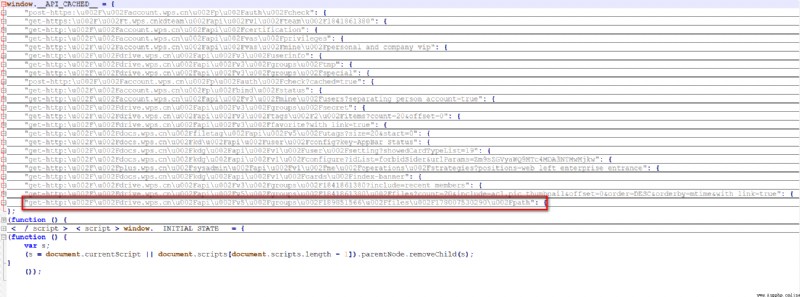 如上圖所示,所有文件的信息(包括
如上圖所示,所有文件的信息(包括fileid)都保存在紅框所在的字段值中(已收起)。
可能你會覺得讀取fileid太麻煩,因此也可以調用紅框中給到的這個API接口(抓包亦可得):
https://drive.kdocs.cn/api/v5/groups/{
group_id}/files?include=acl,pic_thumbnail&with_link=true&offset=0&count={
count}
其中{group_id}如上所述可得,{count}即需要獲取的文件數量,一般該文件夾下有多少文件就取多少,該接口的訪問當然需要登錄狀態,接口返回數據如下圖所示(文件名已遮擋,三個紅框分別框出了groupid,文件名,fileid):
圖5 接口返回的所有文件信息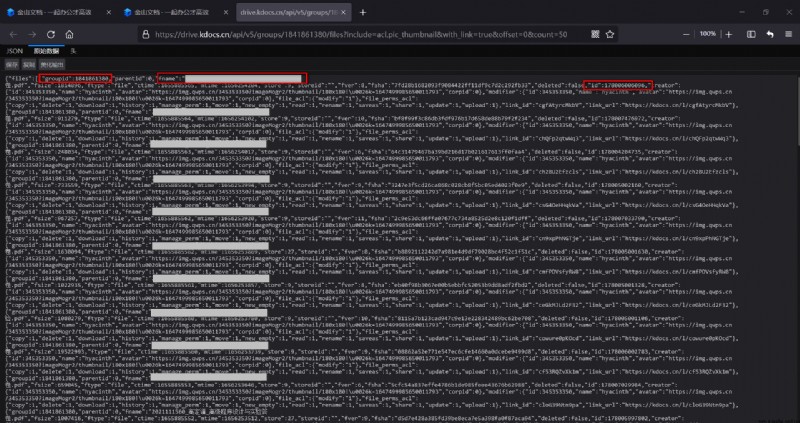
所有文件的groupid和fileid都可得,似乎問題已得解,但是既然可以寫成博客,就不會這麼簡單。
如序言部分所言,關鍵的請求如圖2所示:
圖2 單個文件加載數據包請求字段(copy)
根據以往的經驗,雖然該數據包的請求必然是需要登錄狀態的,但是理論上只要附加上右下框中的所有請求頭,應該就可以得到如圖1的響應結果(即文件的下載地址)。
雖然我在浏覽器中重發這個請求仍然可以得到圖1的結果,證明了該請求並非閱後即焚。但是如果簡單使用requests庫進行請求,並不能得到同樣的響應結果:
def cookie_to_string(cookies: list) -> str:
string = ''
for cookie in cookies:
string += '{}={}; '.format(cookie['name'], cookie['value'])
return string.strip()
# 將字符串形式的請求頭轉為字典形式的headers
def headers_to_dict(headers: str) -> dict:
lines = headers.splitlines()
headers_dict = {
}
for line in lines:
key, value = line.strip().split(':', 1)
headers_dict[key.strip()] = value.strip()
return headers_dict
url = f'https://drive.kdocs.cn/api/v5/groups/{
group_id}/files/{
file_id}/download?isblocks=false&support_checksums=md5,sha1,sha224,sha256,sha384,sha512'
cookies = driver.get_cookies()
headers_string = f"""Host: drive.kdocs.cn User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate, br Connection: keep-alive Cookie: {
cookie_to_string(cookies=cookies)} Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1"""
r = requests.get(url, headers=headers_to_dict(headers=headers_string)) # 無法得到響應結果
那這個事情就顯得很詭異,我嘗試了很長時間,也改用requests.Session測試,依然不得行。這說明金山文檔反爬確實到位,根據後面成功實現爬蟲的結果來看,Cookie中的確是已經包含了所有的登錄信息,那麼我猜想金山文檔應該是做了訪問流程上制定了一些中間件的限制,或者限制了跨域請求,這個的確對於爬蟲非常不友好。
但是總是要解決的,那麼只好轉向萬能的selenium了。
這部分將結合代碼進行解析,因為的確坑非常的多,不過確實也是對爬蟲技巧的提升:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: [email protected]
import re
import json
import time
import requests
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
def get_download_urls(group_id=1841861380, count=50):
# firefox_profile = webdriver.FirefoxProfile(r'C:\Users\caoyang\AppData\Roaming\Mozilla\Firefox\Profiles\sfwjk6ps.default-release')
# driver = webdriver.Firefox(firefox_profile=firefox_profile)
driver = webdriver.Firefox()
driver.get('https://account.wps.cn/') # 登錄頁面
WebDriverWait(driver, 30).until(lambda driver: driver.find_element_by_xpath('//*[contains(text(), "VIU")]').is_displayed())
driver.get('https://www.kdocs.cn/latest')
WebDriverWait(driver, 30).until(lambda driver: driver.find_element_by_xpath('//span[contains(text(), "共享")]').is_displayed())
def cookie_to_string(cookies: list) -> str:
string = ''
for cookie in cookies:
string += '{}={}; '.format(cookie['name'], cookie['value'])
return string.strip()
def headers_to_dict(headers: str) -> dict:
lines = headers.splitlines()
headers_dict = {
}
for line in lines:
key, value = line.strip().split(':', 1)
headers_dict[key.strip()] = value.strip()
return headers_dict
# driver.get(f'https://drive.kdocs.cn/api/v5/groups/{group_id}/files?include=acl,pic_thumbnail&with_link=true&offset=0&count={count}')
# time.sleep(3)
# html = driver.page_source
# windows = driver.window_handles
# print(html)
# print(len(windows))
# print(driver.current_url)
# https://drive.kdocs.cn/api/v5/groups/1841861380/files?include=acl,pic_thumbnail&with_link=true&offset=0&count=50
cookies = driver.get_cookies()
headers_string = f"""Host: drive.kdocs.cn User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate, br Connection: keep-alive Cookie: {
cookie_to_string(cookies=cookies)} Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1"""
r = requests.get(f'https://drive.kdocs.cn/api/v5/groups/{
group_id}/files?include=acl,pic_thumbnail&with_link=true&offset=0&count={
count}', headers=headers_to_dict(headers=headers_string))
html = r.text
json_response = json.loads(html)
files = json_response['files']
print(f'共計{
len(files)}個文件')
download_urls = []
filenames = []
for file_ in files:
group_id = file_['groupid']
file_id = file_['id']
filename = file_['fname']
print(filename, group_id, file_id)
url = f'https://drive.kdocs.cn/api/v5/groups/{
group_id}/files/{
file_id}/download?isblocks=false&support_checksums=md5,sha1,sha224,sha256,sha384,sha512'
# driver.get(url)
# time.sleep(3)
# html = driver.page_source
cookies = driver.get_cookies()
headers_string = f"""Host: drive.kdocs.cn User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate, br Connection: keep-alive Cookie: {
cookie_to_string(cookies=cookies)} Upgrade-Insecure-Requests: 1 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1"""
r = requests.get(url, headers=headers_to_dict(headers=headers_string))
html = r.text
# print(html)
json_response = json.loads(html)
download_url = json_response['url']
print(download_url)
download_urls.append(download_url)
filenames.append(filename)
with open('d:/download_urls.txt', 'w') as f:
for download_url, filename in zip(download_urls, filenames):
f.write(filename + '\t' + download_url + '\n')
driver.quit()
get_download_urls()
建議先把上面的代碼復制下來,接下來的闡述將按代碼的行數展開(不要刪除注釋掉的行,那些都是坑點所在)。
首先來看14-18行:
我一開始考慮是否只要導入用戶數據(關於用戶數據在爬蟲中的應用可以查閱我的博客)即可跳過金山文檔登錄。需要說明的是我沒有測試Chrome浏覽器的情況,但是Firefox確實是不管用,即便我先打開一個窗口登錄金山文檔(此時不管我再打開幾個窗口訪問金山文檔,都是處於登錄狀態),再啟動導入用戶數據的selenium,依然是卡在登錄頁面。因此不得已只能注釋掉14-15行。
然後17行訪問登錄頁面,18行是在延時等待登錄成功(此期間可以點擊微信登錄,然後掃碼確認)。
其實用過selenium的應該都知道,如果中途你time.sleep的時間過長,selenium就會崩潰,如果你手動在頁面上進行操作(比如點擊,滑動,輸入文字之類),selenium也會崩潰。我以前一直以為selenium啟動後是完全不能操作浏覽器,現在發現其實只要寫個WebDriverWait(其中xpath搜索的是用戶名,VIU是我的用戶名),然後你就可以隨便點擊掃碼登錄了,這倒是很方便。
接下來是20-21行:
這個特別坑,如果你登陸完後,直接訪問37行的接口(即圖5),它並不會顯示圖5的結果,只會告訴你用戶未登錄,因此只能先訪問金山文檔首頁。這個其實也就是我覺得可能是在流程上做了限制來進行反爬。
23-35行是兩個工具函數,cookie_to_string是將driver.get_cookies()返回的Cookie格式(形如[{'name': name, 'value': 'value'}, ...])轉為字符串的Cookie添加到請求頭中,headers_to_dict是將從浏覽器復制下來的字符串請求頭改寫為字典形式(用於requests.get的headers參數)
37-61行:
坑點來了,這時候我用37行訪問圖5的接口確實是可以看到圖5的數據,但是39行的driver.page_source返回的確是20行金山文檔首頁的HTML,這TM就很蛋疼。可以看到40行-43行做了若干測試,我證明了確實當前只有一個窗口(len(windows)為1),並且driver.current_url顯示當前的頁面URL的確也不是金山文檔首頁。
這個問題困擾了很長時間,我查了drivers的函數也沒有獲取頁面中JSON數據的方法。以前也沒注意到這種響應結果為JSON的頁面竟然是不能通過driver.page_source獲取頁面數據的,因此被迫改用requests庫去重寫這段邏輯(47-61行)。
有人可能說了,按照序言的說法,這個請求響應不是也不能用requests獲得嗎?確實如此,如果只是單用47-61行來訪問圖5的結果,的的確確依然返回的是用戶未登錄,但是這裡我用的是drivers.get_cookies()返回的Cookie信息來替換直接從浏覽器中復制下來的請求頭中的Cookie信息,竟然就奇跡般地就成了,實話說我也不是特別能理解這裡的原理,也不知道金山文檔後端代碼到底是怎麼判斷是不是爬蟲進行的請求。
63-66行:拿到圖5的文件信息數據。
68-99行:
這裡發生的事情跟37-61行一模一樣,我們想要得到圖1的響應結果(自然也是JSON格式的數據),如果還是用driver去訪問接口,得到的driver.page_source裡依然是金山文檔首頁的HTML,因此這裡用了同樣的方法(requests改寫),即可得到96行的文件下載地址。
同樣地,根據序言中的情況,如果直接用requests訪問圖2是不可行的,但是這裡在selenium完成登錄操作後的確就又可行了。
所有文件下載地址存儲在d:/download_urls.txt中,因為這個下載地址即便不處於登錄狀態也可以使用,收尾工作就顯得非常簡單了。
with open('d:/download_urls.txt', 'r') as f:
lines = f.read().splitlines()
for line in lines:
filename, url = line.split('\t')
r = requests.get(url)
with open(f'd:/{
filename}', 'wb') as f:
f.write(r.content)
這裡附加一個等價的JS代碼,理論上直接在控制台中運行即可下載,但是問題在於會發生跨域請求錯誤,所以好像還是不太行,不知道有沒有朋友能解決一下這個問題。
let groups = "1842648021";
let count = 54;
let res = await fetch(`https://drive.kdocs.cn/api/v5/groups/${
groups}/files?include=acl,pic_thumbnail&with_link=true&offset=0&count=${
count}&orderby=fname&order=ASC&filter=folder`);
let files = await res.json();
files = files.files;
let urls = []
let fid, info, url;
for (let f of files) {
fid = f.id;
res = await fetch(`https://drive.kdocs.cn/api/v5/groups/${
groups}/files/${
fid}/download?isblocks=false&support_checksums=md5,sha1,sha224,sha256,sha384,sha512`, {
"method": "GET",
"mode": "cors",
"credentials": "include"
});
info = await res.json();
url = info.url;
urls.push(url);
}
console.log("待下載文件數量:", urls.length);
for (let i = 0; i < urls.length; i++) {
let url = urls[i];
let fname = files[i].fname
fetch(url).then(res => res.blob().then(blob => {
let a = document.createElement('a');
let url = window.URL.createObjectURL(blob);
let filename = fname;
a.href = url;
a.download = filename;
a.click();
window.URL.revokeObjectURL(url);
}))
}
目前迫切需要解決的問題還是selenium訪問JSON頁面到底應該如何讀取數據,我想到的一種很扯淡的方法是用from selenium.webdriver.common.keys import Keys中直接Ctrl+A,Ctrl+C把頁面數據復制下來得到字符串,這個雖然笨,但是似乎是可行的。
另一個疑難就是到底有沒有辦法只用requests而無需依賴selenium完成金山文檔的批量下載,以及到底為什麼會出現序言中的問題,這個的確是很困擾的。
總之,混用requests和selenium的確是不太漂亮,我想應該會有人能拿出更漂亮的解決方案。