# coding:utf-8
# Regular expression quantifiers
# Symbols in regular expressions
# Symbol describe
# re1 | re2 Match regular expression re1 perhaps re2 ;re1 And re2 Represents two matching string information
# ^ Match the beginning of the string
# $ Match the end of the string ( That's the end )
# * matching 0 Regular expressions that appear before one or more times
# + matching 1 Regular expressions that appear before one or more times
# {N} matching N The previous regular expression
# {M, N} matching M - N The previous regular expression
# […] Matches any single character from the character set
# […x-y…] matching x-y Any single character in the range
# [^…] Does not match any of the characters present in this character set , Include a range of characters ( If... Appears in this character set )
# \ Invalidate special characters
# () Get the specified data in the matching rule
# \b Matches a word boundary , That is, the position between the word and the space . for example , 'er\b' Can match "never" Medium 'er', But can't match "verb" Medium 'er'.
# \1...\9 Matching first n Grouped content .
# \10 Matching first n Grouped content , If it's matched . Otherwise, it refers to the expression of octal character code .
import re
# def check_url(url):
url1 = "https://www.csdn.net/"
url2 = "ftp://110.110.110.110:8080"
url3 = "https://huskypower.blog.csdn.net/article/details/124222979"
email1 = '[email protected]'
email2 = '[email protected]'
# Defined function check_url Judge url Whether it is a normal address
def check_url(url):
res = re.findall('[a-zA-Z]{4,5}://\w*\.*\w+\.\w+', url)
print(res)
# Defined function get_url obtain url Domain name of
def get_url(url):
res = re.findall('[a-zA-Z]{4,5}://([\w+\.*]*)', url)
print(res[0])
# Defined function check_emial Determine the email format
def get_email(email):
# result = re.findall('[0-9a-zA-Z][email protected][0-9a-zA-Z]+\.[a-zA-Z]+', email) # It's complicated to write like this , You can use wildcards
result = re.findall('[email protected]+\.[a-zA-Z]*', email)
# return result
print(result)
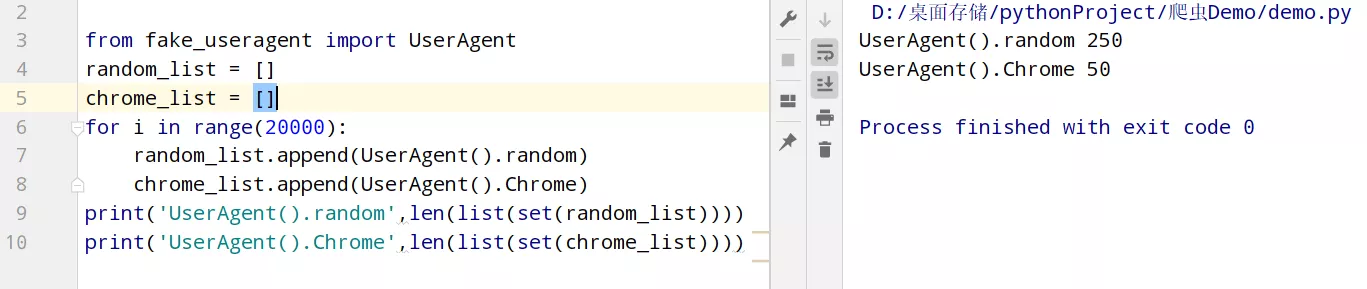
check_url(url3)
get_url(url3)
get_email(email1)
get_email(email2)