Regular expressions (RegEx) It's a special sequence of characters , It uses a search pattern to find a string or group of strings . It can detect the existence of text by matching the text with a specific pattern , You can also split a schema into one or more sub schemas .Python Provides a re modular , Support in Python Using regular expressions . Its main function is to provide search , It uses regular expressions and strings . ad locum , It either returns the first match , Either no match is returned .
Example :
import re
s = 'GeeksforGeeks: A computer science portal for geeks'
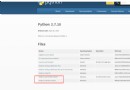
match = re.search(r'portal', s)
print('Start Index position :', match.start())
print('End Index position :', match.end())
Output
The above code gives the start index and end index of the string portal .
Be careful : there r character (r’portal’) Represents the original , Not regular expressions . The original string is slightly different from the regular string , It will not \ Characters are interpreted as escape characters . This is because the regular expression engine uses \ Character to achieve its own escape purpose .
At the beginning of use Python Before the regular expression module , Let's see how to actually write regular expressions using metacharacters or special sequences .
Regular expressions are made up of ordinary characters ( Such as character a To z) And special characters ( be called " Metacharacters ") The composition of the text pattern . Pattern describes one or more strings to match when searching for text . Regular expression as a template , Match a character pattern to the string being searched .
Normal characters include all printable and nonprintable characters that are not explicitly specified as metacharacters . This includes all uppercase and lowercase letters 、 All figures 、 All punctuation and some other symbols .
In order to understand RE Method , Metacharacters are very useful , Important , And will be used in modules re The function of . The following is a list of metacharacters .
Let's discuss each of these metacharacters in detail
The backslash \ Ensure that characters are not handled in a special way . This can be thought of as a way to escape metacharacters . for example , If you want to search in a string dot(.), Then you will find dot(.) Will be treated as a special character , Just like one of the metacharacters ( As shown in the table above ). therefore , In this case , We will be in dot(.) Use backslash before (\), So that it will lose its character . See the following example for a better understanding of .
example :
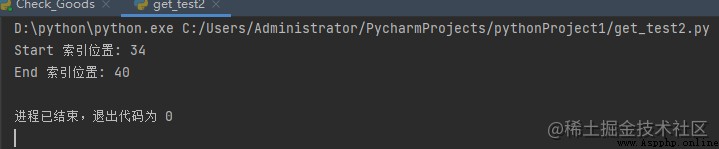
import re
s = 'geeks.forgeeks'
# without using \
match = re.search(r'.', s)
print(match)
# using \
match = re.search(r'.', s)
print(match)
Output :
[] square brackets square brackets [] Represents a character class consisting of a set of characters that we want to match . for example , Character class [abc] Will match any single a、b or c.
We can also use the... In square brackets – Specify the character range . for example
[0, 3] As a sample [a-c] And [abc] identical We can also use caret ^ Reverse character class . for example
[^0-3] Express Division 0、1、2 or 3 Any number other than [^a-c] Express Division a、b or c Any character other than Insertion mark ^ The symbol matches the beginning of the string , That is, check whether the string starts with the given character . for example ——
^g The string will be checked to see if it starts with g start , for example geeks, globe, girl, getc etc. .^ge The string will be checked to see if it starts with ge start , for example geeks、geeksforgeeks etc. .Dollar$ The symbol matches the end of the string , That is, check whether the string ends with the given character . for example ——
s$ Will check to geeks、ends、s And so on .ks$ Will check to ks a null-terminated string , for example geeks、geeksforgeeks、ks etc. . spot . The symbol matches only the division newline character \n A single character other than . for example ——
a.b A string containing any characters at the point will be checked , for example acb,acbd,abbb etc. .. Will check if the string contains at least 2 Characters | Symbol as or Operator , This means that it checks the string for the presence of or Patterns before or after symbols . for example ——
a|b Will match any containing a or b String , Such as acd、bcd、abcd etc. . question mark ? Check whether the string before the question mark in the regular expression appears at least once or does not appear at all . for example ——
ab?c Will match the string ac、acb、dabc, But it doesn't match abbc, Because there are two b. Again , It will not be with abdc matching , because b There is no c. asterisk * Symbols match * Zero or more matches of the regular expression preceding the symbol . for example ——
ab*c Will match the string ac、abc、abbbc、dabc etc. , But it doesn't match abdc, because b There is no c. plus + matching + One or more matches of the regular expression preceding the symbol . for example ——
ab+c Will match the string abc、abbc、dabc, But it doesn't match ac,abdc because ac There is no b, and abdc There is no c.{} Match any repetition before regular expression , from m To n( Include m and n). for example ——
a{2, 4} Will match the string aaab、baaaac、gaad, But it doesn't match abc、bc Etc , Because in both cases there is only one a Or not a.Group symbols are used to group sub patterns . for example ——
(a|b)cd Will match acd、abcd、gacd Etc .The special sequence does not match the actual characters in the string , Instead, it tells the search string where a match must occur . It makes it easier to write common patterns .
Python There is one named re Module , be used for Python Regular expressions in . We can use import Statement to import this module .
example : stay Python Import re modular
importre
Let's look at the various functions provided by this module , In order to be in Python Using regular expressions .
Returns all non overlapping matches of patterns in a string as a string list . Scan string from left to right , And return the matching items in the order they are found .
example : Find all matches of the pattern
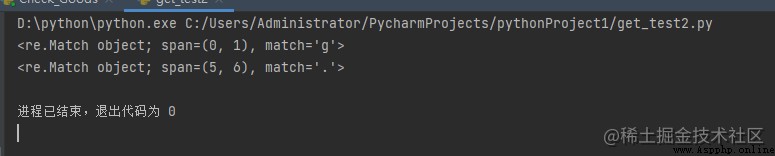
# findall()
import re
# Sample text string , Where regular expressions
# Searched .
string = """Hello my Number is 123456789 and my friend's number is 987654321"""
# Example regular expressions for finding numbers .
regex = '\d+'
match = re.findall(regex, string)
print(match)
Output
Regular expressions are compiled into pattern objects , These objects have methods for various operations , For example, search for pattern matching or perform string replacement .
Example 1:
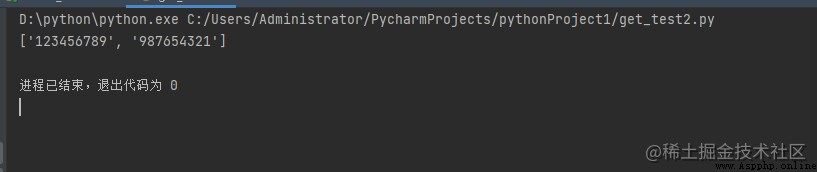
import re
# compile() Create regular expression
# Character class 【a-e】,
# This is equivalent to [abcde].
# class [abcde] Will match the string
# 'a', 'b', 'c', 'd', 'e'.
p = re.compile('[a-e]')
# findall() Search for regular expressions
# And return to the list after finding
print(p.findall("Aye, said Mr. Gibenson Stark"))
Output :

Understand the output :
Splits a string by the number of occurrences of a character or pattern , When the pattern is found , The remaining characters in the string will be returned as part of the result list .
grammar :
re.split(pattern, string, maxsplit=0, flags=0)
The first parameter ,pattern Represents a regular expression ,string Is the given string , Where the pattern is searched and split , If not provided maxsplit, Think maxsplit zero “0”, If any non-zero value is provided , Many splits occur at most . If maxsplit = 1, Then the string will be split only once , The resulting length is 2 A list of . The logo is very useful , Can help shorten code , They are not required parameters , for example :flags = re.IGNORECASE, In this split , Case write , That is, lowercase or uppercase will be ignored .
Example 1:
from re import split
# '\W+' Represents non alphanumeric characters
# Or the character group when searching ','
# Or blank ' ', split(), Split the string starting at this point
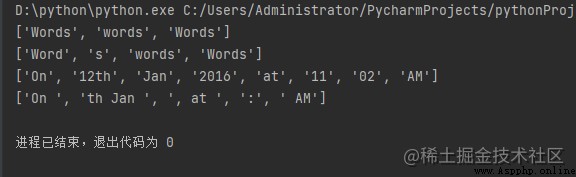
print(split('\W+', 'Words, words , Words'))
print(split('\W+', "Word's words Words"))
# here ':', ' ' ,',' So it's not alphanumeric ,
# The point where the split occurs
print(split('\W+', 'On 12th Jan 2016, at 11:02 AM'))
# '\d+' Represents a numeric character or group of
# Character splitting occurs at “12”, '2016',
# '11', '02' only
print(split('\d+', 'On 12th Jan 2016, at 11:02 AM'))
Output :
Example 2:
import re
# Splitting will only occur in “12” Occurs once at , The length of the returned list is 2
#
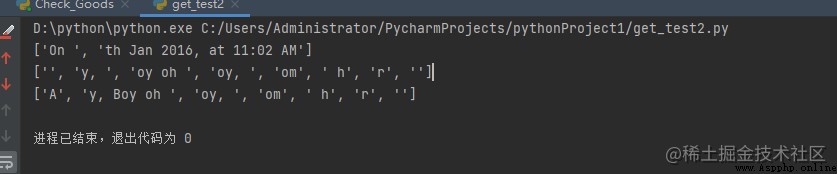
print(re.split('\d+', 'On 12th Jan 2016, at 11:02 AM', 1))
# 'Boy' and 'boy' When flags = re.IGNORECASE when , Will be considered the same . Ignore the case
print(re.split('[a-f]+', 'Aey, Boy oh boy, come here', flags=re.IGNORECASE))
print(re.split('[a-f]+', 'Aey, Boy oh boy, come here'))
Output :
Function “sub” representative SubString, In a given string ( The first 3 Parameters ) Search for a regular expression pattern in , And the substring pattern is found to be repl( The first 2 Parameters ) After replacement , Count and check the number of times this happens .
grammar :
re.sub(pattern, repl, string, count=0, flags=0)
Example 1:
import re
# Regular expression patterns “ub” matching “Subject” and “Uber” String at . As the case may be
# Has been ignored , Use the tag “ub” Should match the string twice when matching ,
# “Subject” Medium “ub” Replace with “~*”, and “Uber” Medium “ub” Replace with “ub”.
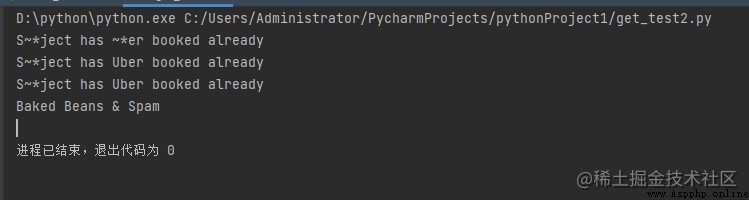
print(re.sub('ub', '~*', 'Subject has Uber booked already', flags=re.IGNORECASE))
# Consider case sensitivity ,“Uber” Medium “Ub” Will not be replaced .
print(re.sub('ub', '~*', 'Subject has Uber booked already'))
# because count The value of is 1, Therefore, the maximum number of replacements is 1
print(re.sub('ub', '~*', 'Subject has Uber booked already',
count=1, flags=re.IGNORECASE))
# Before the mode “r” Express RE,\s Represents the beginning and end of a string .
print(re.sub(r'\sAND\s', ' & ', 'Baked Beans And Spam',
flags=re.IGNORECASE))
Output
subn() In all respects with sub() be similar , In addition to the way the output is provided . It returns a tuple , It contains the total number of replacement and new strings , Not just strings .
grammar :
re.subn(pattern, repl, string, count=0, flags=0)
example :
import re
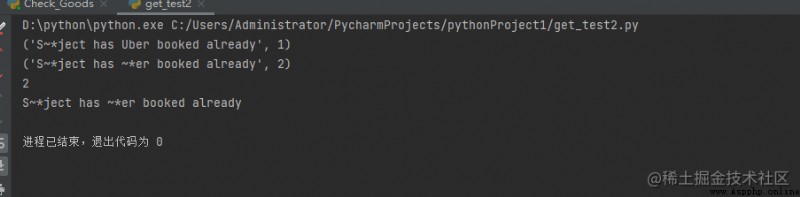
print(re.subn('ub', '~*', 'Subject has Uber booked already'))
t = re.subn('ub', '~*', 'Subject has Uber booked already',
flags=re.IGNORECASE)
print(t)
print(len(t))
# This will provide with sub() Same output
print(t[0])
Output
Returns a string of all non alphanumeric backslashes , If you want to match any text string that may contain regular expression metacharacters , This will be very useful .
grammar :
re.escape(string)
example :
import re
# escape() Returns a backslash before each non alphanumeric character “\” String
# In the first case only “”, In the second case, it is non alphanumeric “”, Insert symbol “^”、“-”、“[]”、“\”
# It's not alphanumeric
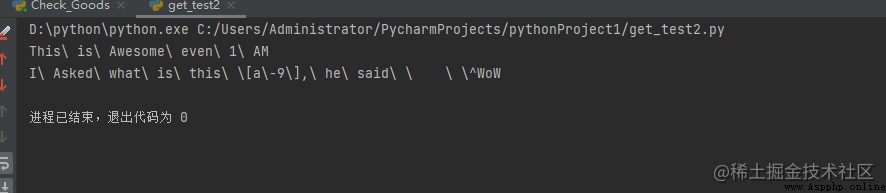
print(re.escape("This is Awesome even 1 AM"))
print(re.escape("I Asked what is this [a-9], he said \t ^WoW"))
Output
This method returns None( If the patterns don't match ), Or return re. The matching object contains information about the matching part of the string . This method stops after the first match , So this is best for testing regular expressions rather than extracting data .
example : The number of occurrences of the search pattern
import re
# Let's use regular expressions to match date strings , The format is month name followed by days
regex = r"([a-zA-Z]+) (\d+)"
match = re.search(regex, "I was born on June 24")
if match != None:
# When the expression “([a-zA-Z]+)(\d+) When matching the date string , We got here .
# This will print [14,21], Because it's indexing 14 There's a match , stay 21 At the end of .
print("Match at index %s, %s" % (match.start(), match.end()))
# We use group() Method to get all matches
# Captured groups . These groups contain matching values .
# especially :
# matching .group(0) Always return an exact matching string
# matching .group(1) matching .group(2)... Return capture
# Group in the input string from left to right
# matching .group() Equivalent to match. Group (0)
# So this will print “6 month 24 Japan ”
print("Full match: %s" % (match.group(0)))
# So this will print “June”
print("Month: %s" % (match.group(1)))
# So this will print "24"
print("Day: %s" % (match.group(2)))
else:
print("The regex pattern does not match.")
Output
Match Object contains all the information about the search and results , If no match is found , Will return to None. Let's take a look match Some common methods and properties of objects .
match.re Property returns the passed regular expression ,match.string Property returns the passed string .
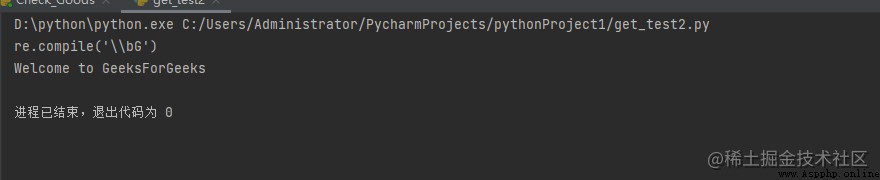
example : Get the string and regular expression of the matching object
import re
s = "Welcome to GeeksForGeeks"
# here x It's a match
res = re.search(r"\bG", s)
print(res.re)
print(res.string)
Output
example : Get the index of the matching object
import re
s = "Welcome to GeeksForGeeks"
# here x It's a match
res = re.search(r"\bGee", s)
print(res.start())
print(res.end())
print(res.span())
Output

group() Method returns the string portion of the pattern match . See the following example for a better understanding of .
example : Get the matching substring
import re
s = "Welcome to GeeksForGeeks"
# here x It's a match
res = re.search(r"\D{2} t", s)
print(res.group())
Output

https://docs.python.org/2/library/re.html