Write it at the front :
- Can not use python2, Try not to use !!!
- however , Real work, if really needed , Still need to know some common pits !!!
utf8-bin It's case sensitive
utf8_general_ci Indicates case insensitive ( This pattern is generally used )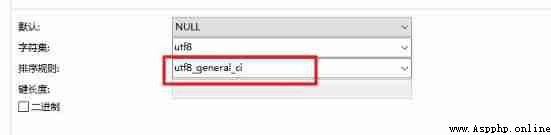
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
name = " Hello , Alien"
name2 = " Hello Alien"
print name2, name
print (name2, name)
print name2
Hello Alien Hello , Alien
('\xe4\xbd\xa0\xe5\xa5\xbdAlien', '\xe4\xbd\xa0\xe5\xa5\xbd, Alien') # most NB Yes. , Print with brackets , It's garbled
Hello Alien
There are many roads at night , There are always demons and ghosts , No matter how hard you try !
b'{"m_strategy_execution_price": 6.066980440315375, "m_strategy_state": 3, "m_strategy_asset": 0.0, "m_strategy_ordered_asset": 1022656.29, "m_strategy_market_price": 0.0, "m_strategy_type": 4818, "m_client_strategy_id": 110900033, "m_strategy_price_diff": -1518.302897856544, "m_strategy_asset_diff": -557891.2899999999, "m_strategy_qty": 1540000, "m_strategy_execution_qty": 168561, "m_strategy_execution_asset": 1022656.29, "m_xtp_strategy_id": 1744072474645, "error_id": 0, "m_strategy_ordered_qty": 168561, "error_msg": "600863\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b600777\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b601015\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b600956\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc", "m_strategy_cancelled_qty": 24539, "m_strategy_unclosed_qty": -168561}'
init_str = b'{"m_strategy_execution_price": 6.066980440315375, "m_strategy_state": 3, "m_strategy_asset": 0.0, "m_strategy_ordered_asset": 1022656.29, "m_strategy_market_price": 0.0, "m_strategy_type": 4818, "m_client_strategy_id": 110900033, "m_strategy_price_diff": -1518.302897856544, "m_strategy_asset_diff": -557891.2899999999, "m_strategy_qty": 1540000, "m_strategy_execution_qty": 168561, "m_strategy_execution_asset": 1022656.29, "m_xtp_strategy_id": 1744072474645, "error_id": 0, "m_strategy_ordered_qty": 168561, "error_msg": "600863\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b600777\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b601015\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc\x9b600956\xe6\x89\xa7\xe8\xa1\x8cT0\xe4\xba\xa4\xe6\x98\x9377000\xe8\x82\xa1\xef\xbc", "m_strategy_cancelled_qty": 24539, "m_strategy_unclosed_qty": -168561}'
# tried N After the failure , You probably don't know how to decode it
str_001 = init_str.decode("utf8")
print(str_001)
str_002 = init_str.decode("gbk")
print(str_002)
str_003 = init_str.decode("gb2312")
print(str_003)
str_004 = bytes.decode(init_str)
print(str_004)
...
...
# Omit here N Methods
# Add one ignore, Characters that cannot be decoded are ignored
str_666 = init_str.decode("utf8", "ignore")
print(str_666)
{
"m_strategy_execution_price": 6.066980440315375, "m_strategy_state": 3, "m_strategy_asset": 0.0, "m_strategy_ordered_asset": 1022656.29, "m_strategy_market_price": 0.0, "m_strategy_type": 4818, "m_client_strategy_id": 110900033, "m_strategy_price_diff": -1518.302897856544, "m_strategy_asset_diff": -557891.2899999999, "m_strategy_qty": 1540000, "m_strategy_execution_qty": 168561, "m_strategy_execution_asset": 1022656.29, "m_xtp_strategy_id": 1744072474645, "error_id": 0, "m_strategy_ordered_qty": 168561, "error_msg": "600863 perform T0 transaction 77000 stocks ;600777 perform T0 transaction 77000 stocks ;601015 perform T0 transaction 77000 stocks ;600956 perform T0 transaction 77000 stocks ", "m_strategy_cancelled_qty": 24539, "m_strategy_unclosed_qty": -168561}
my_list = ["alien", " The world is uncertain , You and I are black horses !","hello,world!"]
print my_list
# The display effect is as follows
['alien', '\xe4\xb9\xbe\xe5\x9d\xa4\xe6\x9c\xaa\xe5\xae\x9a\xef\xbc\x8c\xe4\xbd\xa0\xe6\x88\x91\xe7\x9a\x86\xe9\xbb\x91\xe9\xa9\xac\xef\xbc\x81', 'hello,world!']
my_dict = {
"name": "alien", "slogan": " The world is uncertain , You and I are black horses !", "project": "hello,world!"}
print my_dict
# The display effect is as follows
{
'project': 'hello,world!', 'slogan': '\xe4\xb9\xbe\xe5\x9d\xa4\xe6\x9c\xaa\xe5\xae\x9a\xef\xbc\x8c\xe4\xbd\xa0\xe6\x88\x91\xe7\x9a\x86\xe9\xbb\x91\xe9\xa9\xac\xef\xbc\x81', 'name': 'alien'}
my_list = ["alien", " The world is uncertain , You and I are black horses !","hello,world!"]
my_dict = {
"name": "alien", "slogan": " The world is uncertain , You and I are black horses !", "project": "hello,world!"}
print "{}".format(my_dict).decode("string-escape")
print str(my_dict).decode("string-escape")
print("\n")
print "{}".format(my_list).decode("string-escape")
print str(my_list).decode("string-escape")
{
'project': 'hello,world!', 'slogan': ' The world is uncertain , You and I are black horses !', 'name': 'alien'}
{
'project': 'hello,world!', 'slogan': ' The world is uncertain , You and I are black horses !', 'name': 'alien'}
['alien', ' The world is uncertain , You and I are black horses !', 'hello,world!']
['alien', ' The world is uncertain , You and I are black horses !', 'hello,world!']
re_dict = {
'error_msg': '510110.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510060.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510090.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510120.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510130.S\xcd\x04I\x93]\xda',
'm_xtp_strategy_id': 1155673948691L, 'm_strategy_state': 8, 'error_id': -1, 'm_strategy_type': 5001,
'm_client_strategy_id': 111500189}
str_ok = json.dumps(re_dict) # Report errors
str_ok = json.dumps(re_dict, ensure_ascii=False) # Normal serialization
str_dict = '{"m_strategy_type": 5001, "m_client_strategy_id": 111500189, "m_strategy_state": 8, "m_xtp_strategy_id": 1155673948691, "error_id": -1, "error_msg": "510110.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510060.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510090.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510120.SH\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 510130.S\xcd\\u0004I\x93]\xda"}'
dict_ok = json.loads(str_dict) # Report errors
dict_decode = str_dict.decode("utf8", "ignore") # You need to decode , Ignore exception symbols
dict_ok = json.loads(dict_decode) # Finally, the dictionary can be parsed
error_msg = "510120\u6682\u4e0d\u652f\u6301T0\u4ea4\u6613"
print error_msg.encode('utf-8').decode('unicode_escape')
# Print the results :
# 510120 Temporary does not support T0 transaction
error_msg = "159919.SZ\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 159976.S\xb1\[email protected]\xffR\xf6"
print error_msg.decode('string_escape')
# Print the results
# 159919.SZ I won't support it , Skipped 159976.S��@�R�
Although the printing here is normal , But there's a mess , It's a big hidden danger !!!
If the original string is garbled , If you don't deal with , It is easy to have various coding problems when data is processed in the middle .
for example :
- UnicodeDecodeError
- ‘ascii’ codec can’t decode byte
- ‘utf8’ codec can’t decode byte
error_msg = '159919.SZ\xe4\xb8\x8d\xe6\x94\xaf\xe6\x8c\x81,\xe5\xb7\xb2\xe8\xb7\xb3\xe8\xbf\x87 159976.S\xb1\[email protected]\xffR\xf6'
text = unicode(error_msg, encoding="utf8", errors="replace")
error_msg_result = ''
for single_str in text:
num = ord(single_str)
print type(single_str), single_str, num
if num not in [65533, 64, 82]:
error_msg_result += single_str
print error_msg_result
<type 'unicode'> 1 49
<type 'unicode'> 5 53
<type 'unicode'> 9 57
<type 'unicode'> 9 57
<type 'unicode'> 1 49
<type 'unicode'> 9 57
<type 'unicode'> . 46
<type 'unicode'> S 83
<type 'unicode'> Z 90
<type 'unicode'> No 19981
<type 'unicode'> the 25903
<type 'unicode'> a 25345
<type 'unicode'> , 44
<type 'unicode'> has 24050
<type 'unicode'> jump 36339
<type 'unicode'> too 36807
<type 'unicode'> 32
<type 'unicode'> 1 49
<type 'unicode'> 5 53
<type 'unicode'> 9 57
<type 'unicode'> 9 57
<type 'unicode'> 7 55
<type 'unicode'> 6 54
<type 'unicode'> . 46
<type 'unicode'> S 83
<type 'unicode'> � 65533
<type 'unicode'> � 65533
<type 'unicode'> @ 64
<type 'unicode'> � 65533
<type 'unicode'> R 82
<type 'unicode'> � 65533
# Need content , Special characters are filtered out
159919.SZ I won't support it , Skipped 159976.S