1. character string , list , Yuan Zu , Dictionaries , aggregate 、 Documents, etc. , Are all iteratable objects , Both have iterative properties .
2. Iterative , Does not mean that it is an iteratable object
1. contain __getitem__ Magic methods : Iterative
from collections import Iterable
# 1、 Only achieve __getitem__
class A:
def __init__(self):
self.data = [1, 2, 3]
def __getitem__(self, index):
return self.data[index]
a = A()
print(isinstance(a, Iterable)) # Determine whether it is an iterative object
for i in a:
print(i)
# result :
False
1
2
3
2. contain __getitem__ Magic methods & __iter__ Magic methods : Iteratable object
from collections import Iterable
class A:
def __init__(self):
self.data = [1, 2, 3]
self.data1 = [4, 5, 6]
def __iter__(self):
return iter(self.data1)
def __getitem__(self, index):
return self.data[index]
a = A()
print(isinstance(a, Iterable)) # Determine whether it is an iterative object
for i in a:
print(i)
# The result is :
True
4
5
6
- character string , list , Yuan Zu , Dictionaries , aggregate 、 Documents, etc. , Are all iteratable objects
- Realized __iter__ Methods are called iteratable objects ,_iter__ Method can return an iterator object , And then through next() Method to get elements one by one .
- Intuitive understanding is , It works for The iterated object is the iteratable object .
【 The following figure is very important 、 Very important 、 Very important !!!】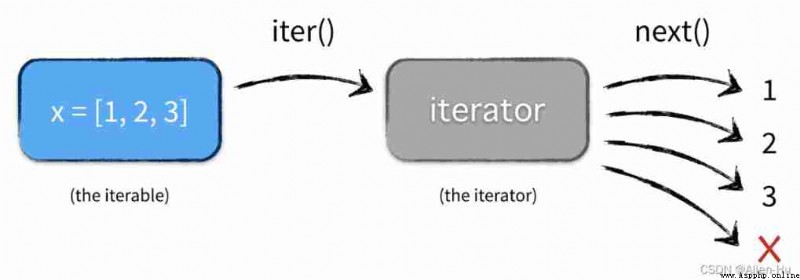
understand :
- for example X List objects , Can pass iter() Method to get the iterator , Through iterators next() Method to get the object element , shows X List objects are iteratable objects
- There is a new concept — iterator , This follow-up explanation …
my_list = ["hello", "alien", "world"]
# The following two methods have the same effect , Is to get the iterator
list_type_iterator = my_list.__iter__() # In this way , View the source code of the iteratable object
# list_type_iterator = iter(my_list)
print(list_type_iterator)
item = list_type_iterator.next() # In this way , Check the iterator source code
print(item)
item = list_type_iterator.next()
print(item)
item = list_type_iterator.next()
print(item)
<listiterator object at 0x10a8fa3d0>
hello
alien
world
# Through the above code , adopt __iter__() Function into the source code (Ctrl + B), Let's find out
list_type_iterator = my_list.__iter__()
Enter into __builtin__.py In file , This document defines python3 Data types commonly used in .
We search this file for __iter__ Method , Find the following code :
class list(object):
""" list() -> new empty list list(iterable) -> new list initialized from iterable's items """
def append(self, p_object): # real signature unknown; restored from __doc__
""" L.append(object) -- append object to end """
pass
def __iter__(self): # real signature unknown; restored from __doc__
""" x.__iter__() <==> iter(x) """
pass
class dict(object):
""" dict() -> new empty dictionary dict(mapping) -> new dictionary initialized from a mapping object's (key, value) pairs dict(iterable) -> new dictionary initialized as if via: d = {} for k, v in iterable: d[k] = v dict(**kwargs) -> new dictionary initialized with the name=value pairs in the keyword argument list. For example: dict(one=1, two=2) """
def clear(self): # real signature unknown; restored from __doc__
""" D.clear() -> None. Remove all items from D. """
pass
def __iter__(self): # real signature unknown; restored from __doc__
""" x.__iter__() <==> iter(x) """
pass
class file(object):
""" file(name[, mode[, buffering]]) -> file object Open a file. The mode can be 'r', 'w' or 'a' for reading (default), writing or appending. The file will be created if it doesn't exist when opened for writing or appending; it will be truncated when opened for writing. Add a 'b' to the mode for binary files. Add a '+' to the mode to allow simultaneous reading and writing. If the buffering argument is given, 0 means unbuffered, 1 means line buffered, and larger numbers specify the buffer size. The preferred way to open a file is with the builtin open() function. Add a 'U' to mode to open the file for input with universal newline support. Any line ending in the input file will be seen as a '\n' in Python. Also, a file so opened gains the attribute 'newlines'; the value for this attribute is one of None (no newline read yet), '\r', '\n', '\r\n' or a tuple containing all the newline types seen. 'U' cannot be combined with 'w' or '+' mode. """
def readline(self, size=None): # real signature unknown; restored from __doc__
""" readline([size]) -> next line from the file, as a string. Retain newline. A non-negative size argument limits the maximum number of bytes to return (an incomplete line may be returned then). Return an empty string at EOF. """
pass
def close(self): # real signature unknown; restored from __doc__
""" close() -> None or (perhaps) an integer. Close the file. Sets data attribute .closed to True. A closed file cannot be used for further I/O operations. close() may be called more than once without error. Some kinds of file objects (for example, opened by popen()) may return an exit status upon closing. """
pass
def __iter__(self): # real signature unknown; restored from __doc__
""" x.__iter__() <==> iter(x) """
pass
# Through the beginning of the article next() Method , You can go to the source code of the iterator to see what happened
item = list_type_iterator.next()
item It is an element in the iteratable object
@runtime_checkable
class Iterable(Protocol[_T_co]):
@abstractmethod
def __iter__(self) -> Iterator[_T_co]: ...
# explain : Iteratable objects pass __iter__() Method to get the iterator
@runtime_checkable
class Iterator(Iterable[_T_co], Protocol[_T_co]):
@abstractmethod
def next(self) -> _T_co: ...
# explain : The iterator passes through next() Method to get an element
def __iter__(self) -> Iterator[_T_co]: ...
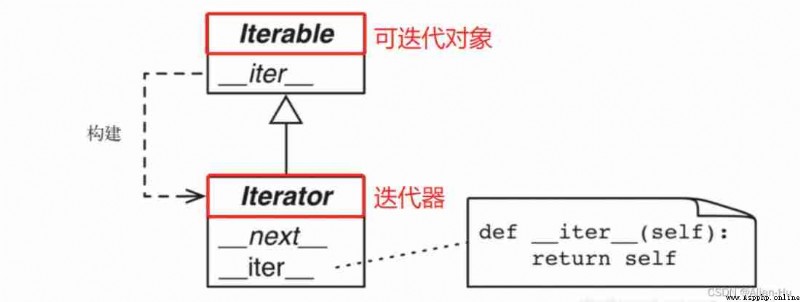
Through the above code 、 Source code we conclude :
- Every iteratable object has a __iter__ function
- Iteratable objects pass __iter__ Get the iterator , Iterator re pass next() Method , You can get the elements
- Every time next() after , The iterator records the progress of the current execution , The next time to perform next() When , Continue to execute at the last position . So the elements are continuous at each iteration .
class Fib():
def __init__(self, max):
self.n = 0
self.prev = 0
self.curr = 1
self.max = max
def __iter__(self):
return self
def __next__(self):
if self.n < self.max:
value = self.curr
self.curr += self.prev
self.prev = value
self.n += 1
return value
else:
raise StopIteration
fb = Fib(5)
print(fb.__next__())
print(fb.__next__())
print(fb.__next__())
print(fb.__next__())
print(fb.__next__())
print(fb.__next__())
1
1
2
3
5
Traceback (most recent call last):
File "/Volumes/Develop/iterator_generator.py", line 43, in <module>
print(fb.__next__())
File "/Volumes/Develop/iterator_generator.py", line 34, in __next__
raise StopIteration
StopIteration
Be careful :
1. When the iterator has no data , If you call next() Method , Will throw out StopIteration error
1. Why use iterators ?
for example , You want to create one with 100000000 Fibonacci series of data . If it is used after all the data are generated , It will definitely consume a lot of memory resources . If you use iterators to handle , You can basically ignore the occupation of memory and the cost of computing time .
2. The principle of iterator is used to read the file
【 Common read method 】
# readlines() The method is actually to read all the contents of the file and form a list, No line is one of the elements
for line in open("test.txt").readlines():
print line
# 1. Read all the contents of the file at once and load them into memory , Then print line by line .
# 2. When the file is large , The memory cost of this method is very large , If the file is larger than the memory , The program will collapse
【 Iterator mode reads 】
for line in open("test.txt"): #use file iterators
print line
# This is the simplest and fastest way to write , He didn't read the file explicitly , Instead, use the iterator to read the next line at a time .
- Generator is a special kind of iterator , Have the properties of iterators , But this iterator is more elegant .
- It doesn't need to be written like the class above __iter__() and __next__() The method , Just one yiled keyword .
- The generator must be an iterator ( Otherwise, it doesn't work ), So any generator also generates values in a lazy load mode .
1. Just put a list into a generative [ ] Change to ( )
L = [x * 2 for x in range(5)]
print(type(L))
G = (x * 2 for x in range(5))
print(G)
# give the result as follows :
<type 'list'>
<generator object <genexpr> at 0x10fa48730>
#=================================
# Get the element in the generator
G = (x * 2 for x in range(5))
print(next(G))
print(next(G))
print(next(G))
# give the result as follows
0
2
4
2. Create a generator with a function
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
a = fib(10)
print(next(a))
print(next(a))
print(next(a))
# result :
1
1
2
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print("yield--------start")
yield b # Every time you execute next() Method , It's all here , And return an element
a, b = b, a + b # yield The following section , The next time next Method to execute
n = n + 1
print("yield--------end")
fb = fib(5)
print(next(fb))
print("\n")
print(next(fb))
print("\n")
print(next(fb))
# result :
yield--------start
1
yield--------end
yield--------start
1
yield--------end
yield--------start
2
- Generators are like iterators , When all element iterations are complete , If we do it again next() function , Will report a mistake . To optimize this problem , have access to return solve
- return It can be done in iterations , Return to a specific 【 error message 】, And then through try Capture StopIteration error , You can receive this 【 error message 】
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'iter num finish'
1. Mode one :
def iter_list(iterator):
try:
x = next(iterator)
print("----->", x)
except StopIteration as ret:
stop_reason = ret.value
print(stop_reason)
iter_list(fb)
iter_list(fb)
iter_list(fb)
iter_list(fb)
iter_list(fb)
iter_list(fb)
# result :
-----> 1
-----> 1
-----> 2
-----> 3
-----> 5
iter num finish
1. Mode two :
fb = fib(5)
def iter_list(iterator):
while True:
try:
x = next(iterator)
print("----->", x)
except StopIteration as ret:
stop_reason = ret.value
print(stop_reason)
break
iter_list(fb)
# result :
-----> 1
-----> 1
-----> 2
-----> 3
-----> 5
iter num finish
1.next() To wake up and continue
2.send() To wake up and continue , At the same time, send a message to the generator , Need a variable receive
def fib(max):
n, a, b = 0, 0, 1
while n < max:
temp = yield b
print("\n temp------>", temp)
a, b = b, a + b
n = n + 1
a = fib(10)
print(next(a))
abc = a.send("hello")
print(abc)
abc = a.send("alien")
print(abc)
# result :
1
temp------> hello
1
temp------> alien
2
- Through the above send() Use of functions , explain send once , It's equivalent to next() once , It also passes a value to temp Variable reception , Explain that at the same time 2 thing .
- a.send(“hello”) Result , Equivalent to next(a) Result
- send Execution of a function , First pass the passed value , Assign a value to temp, And then execute next The function of
def producter(num):
print("produce %s product" % num)
while num > 0:
consume_num = yield num
if consume_num:
print("consume %s product" % consume_num)
num -= consume_num
else:
print("consume 1 time")
num -= 1
else:
return "consume finish"
p = producter(20)
print("start----->", next(p), "\n")
abc = p.send(2)
print("the rest num---->", abc, "\n")
print("the rest num---->", next(p), "\n")
# result :
produce 20 product
start-----> 20
consume 2 product
the rest num----> 18
consume 1 time
the rest num----> 17
The main features of the collaborative process :
def task1(times):
for i in range(times):
print('task_1 done the :{} time'.format(i + 1))
yield
def task2(times):
for i in range(times):
print('task_2 done the :{} time'.format(i + 1))
yield
gene1 = task1(5)
gene2 = task2(5)
for i in range(10):
next(gene1)
next(gene2)
# result :
task_1 done the :1 time
task_2 done the :1 time
task_1 done the :2 time
task_2 done the :2 time
task_1 done the :3 time
task_2 done the :3 time
task_1 done the :4 time
task_2 done the :4 time
task_1 done the :5 time
task_2 done the :5 time
Use the generator's hang and rerun feature , We can achieve on-demand , Each time a file of a specified size is read , Avoid reading files because , Because too much content is read at one time , Cause problems such as memory overflow
def read_file(fpath):
BLOCK_SIZE = 1024
with open(fpath, 'rb') as f:
while True:
block = f.read(BLOCK_SIZE)
if block:
yield block
else:
return
 Python tutorial 95 -- Summary of Python knowledge points of Excel operation
Python tutorial 95 -- Summary of Python knowledge points of Excel operation
One 、 demand :1、Excel Preproce
 使用python中optimize.curve_fit函數對曲線擬合的時候,出現Residuals are not finite in the initial point報錯,請問該怎麼處理啊?
使用python中optimize.curve_fit函數對曲線擬合的時候,出現Residuals are not finite in the initial point報錯,請問該怎麼處理啊?
問題遇到的現象和發生背景使用python中optimize.