The story background :
- One day I found myself in the code ,redis The efficiency of reading and writing is not as expected , So I decided to study
- The learning process is summarized as follows , It is convenient for everyone to understand and make common progress
Premise : Write content locally to remote redis On
# Decorator : Calculate the execution time of a function
def calculate_time(func):
def fun(*args, **kwargs):
t = time.perf_counter()
result = func(*args, **kwargs)
print(f'【{
func.__name__}】calculate time: 【{
time.perf_counter() - t:.8f} s】')
return result
return fun
HOST = 'xxx.xx.xx.xx'
PORT = 'xxx'
PASSWORD = 'XXXXX'
redis_connection = redis.Redis(host=HOST,
port=PORT,
password=PASSWORD,
decode_responses=True,
db=10)
# decode_responses=True, write in value In Chinese, it means str type , Otherwise, it is byte type
@calculate_time
def input_str_into_redis_2():
for i in range(1000):
key = "name_" + str(i)
value = "value_" + str(i)
redis_connection.set(key, value)
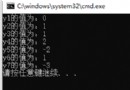
【input_str_into_redis_2】calculate time: 【5.26661710 s】
【input_str_into_redis_2】calculate time: 【0.10137470 s】
since , Each connection takes a long network delay . Can you reduce the number of reads and writes , Write more than one at a time ?! After trying , Find it feasible !
HOST = 'xxx.xx.xx.xx'
PORT = 'xxx'
PASSWORD = 'XXXXX'
redis_connection = redis.Redis(host=HOST,
port=PORT,
password=PASSWORD,
decode_responses=True,
db=10)
@calculate_time
def input_str_into_redis_2():
input_dict = dict()
for i in range(1000):
key = "name_" + str(i)
value = "value_" + str(i)
if i % 10 == 9: # Every time 10 Data , Insert once to redis in
redis_connection.mset(input_dict)
input_dict.clear()
else:
input_dict[key] = value
【input_str_into_redis_2】calculate time: 【0.57734180 s】
- From the initial 5.26661710 s, So far 0.57734180 s, Efficiency has also improved by nearly 10 times .
- In fact, it can be debugged many times , Set the number of data pieces inserted each time to other values , There should be more efficient cases
- From this it is found that , We should have solved a major contradiction of delay
summary : Insert multiple pieces of data at a time , Reduce redis Number of connections , Can greatly improve efficiency !!!
- Every time 、 Release the connected redis When , There will also be a certain cost .
- You can use the connection pool ( Establish multiple connections at once ) The way , Yes redis Read and write . In this way, the connection pool will manage all connections by itself , You can use any connection directly . There will be no program waiting to create a connection .
HOST = 'xxx.xx.xx.xx'
PORT = 'xxx'
PASSWORD = 'XXXXX'
pool = redis.ConnectionPool(host=HOST, port=PORT, password=PASSWORD, decode_responses=True, max_connections=10, db=10)
redis_connection = redis.Redis(connection_pool=pool)
# max_connections=10 , This is the maximum number of connections , You can debug the size according to the actual situation
@calculate_time
def input_str_into_redis():
input_dict = dict()
for i in range(1000):
key = "name_" + str(i)
value = "value_" + str(i)
if i % 10 == 9:
redis_connection.mset(input_dict)
input_dict.clear()
else:
input_dict[key] = value
By connecting the pool , It is found that the efficiency of the above method is improved . When estimating the complexity of the scene , The maximum utility of the connection pool can be brought into full play !
【input_str_into_redis】calculate time: 【0.51495970 s】
- There are a lot of database operations in an application , The behavior of connecting to a database against a database handle , Using singleton mode can avoid a lot of new operation . Because every time new Operation will consume system and memory resources .
- If more than one code is used redis The read , Using singleton mode is also easy to manage redis The connection of
import redis
class RedisPool:
__instance = None
def __init__(self):
self.pool = redis.ConnectionPool(host='localhost', port=6379, password="xxx", max_connections=10,
decode_responses=True, db=10)
def __getConnection(self):
conn = redis.Redis(connection_pool=self.pool)
return conn
@classmethod
def getConn(cls):
if RedisPool.__instance is None:
RedisPool.__instance = RedisPool()
return RedisPool.__instance.__getConnection()
redisConn = RedisPool.getConn()