This article summarizes my long-term script writing , The knowledge points covered are python The basis of , However, it is easy for us to neglect , I hope it will be helpful to everyone .
In practice , We often encounter after writing code , The test found that the results were inconsistent with their own expectations , So we began to work layer by layer debug, Spend a lot of time , Finally, it is found that the problem is only caused by the change of data structure in the process of parameter transfer .
This is one of the most commonly used methods , namely b=a. It's easy to understand , as long as a Changed ,b It also changes .
Shallow copy creates new objects , Its content is not the original object itself , But the reference of the first layer object in the original object . There are three ways to implement shallow copies : section (b=a[:])、 Factory function (b=set(a))、copy Module copy function (b=copy.copy(a)).
Since a shallow copy is a reference to a copy object , The target object will record : Container type 、 Container size and references to each object in the container . So when changing the container type of the source object 、 Container size 、 The reference address of the object in the container , Will not cause changes to the target object . But sometimes when we manipulate source objects , Will directly change the objects in the container , At this time, the target object will also change .
# Source object a
a = [1, (1, 2), [1, 2]]
# Shallow copy b, Two other ways :b=list(a),b=copy.copy(a)
b = a[:]
# tuple immutable , In fact, it points to a new tuple object , change a Internal references , therefore b It won't change
a[1] += (3, 4)
# Change the size of the container , Will not cause b The change of
a.append(90)
# list variable , What changes is the object itself , therefore b It's going to change
a[2].append(10)
# Change container type , Will not cause b The change of
a = tuple(a)
print(a)
print(b)
----------------------------------
(1, (1, 2, 3, 4), [1, 2, 10], 90)
[1, (1, 2), [1, 2, 10]]Deep copy is to copy the source object , Re create it , It should be noted that it costs a lot of time and space . How to implement deep copy :copy Module deepcopy function (b=copy.deepcopy(a)).
An important feature of deep copy , The source object is completely isolated from the target object , Manipulating the source object does not have any effect on the target object .
python Parameter passing between functions , It doesn't have the concept of formal and actual parameters like other languages , It is passed by assignment , It can be simply understood as the delivery mode of shallow copy ( Not exactly, of course ).
In practice , Many functions are likely to contain some common code blocks , The logic code of the actual function has little to do with this part of the code block , Write this code directly inside the function , Makes the code redundant and unreadable . Take a classic test scenario : An error may occur during interface call due to environmental reasons , We should introduce a delayed retry mechanism , Avoid the failure of test script execution due to environmental reasons . A common example is log printing , But the log printing has a sealed decorator , No need to self encapsulate .
Learn decorators , You have to know , stay python Middle function is also an object , We can take some important knowledge points about functions :
Here are a few code examples for parsing
def get_message(message):
return message
def call(func, message):
print(func(message))
call(get_message, "hello world")
----------------------------------
hello worldThe classic application of this knowledge point is threading Call to ,target The parameters give the objective function .
def outer_func():
# When nesting is used , Variables outside the inner function are recorded , The next time you call , Changes will be made on this basis ; And is isolated when called multiple times
loc_list = []
def inner_func(func):
loc_list.append(len(loc_list) + 1)
print(f'{func} loc_list = {loc_list}')
return inner_func
clo_func_0 = outer_func()
clo_func_0('clo_func_0')
clo_func_0('clo_func_0')
clo_func_0('clo_func_0')
clo_func_1 = outer_func()
clo_func_1('clo_func_1')
clo_func_0('clo_func_0')
clo_func_1('clo_func_1')
----------------------------------
clo_func_0 loc_list = [1]
clo_func_0 loc_list = [1, 2]
clo_func_0 loc_list = [1, 2, 3]
clo_func_1 loc_list = [1]
clo_func_0 loc_list = [1, 2, 3, 4]
clo_func_1 loc_list = [1, 2]The reference free variable in the closure is only related to the specific closure , Each instance of the closure refers to free variables that do not interfere with each other .
Changes to its free variables by a closure instance are passed on to the next call to the closure instance .
def retry(retry_cnt=retry_cnt):
def _decorator(func):
# When you package the decorator yourself , This cannot be missing , This is the function that will add the decorator and keep the original attribute , If not , The original function will be changed , Unable to call
@functools.wraps(func)
def wrapper(*args, **kwargs):
for cnt in range(retry_cnt + 1):
result = func(*args, **kwargs)
# Determine whether to retry according to the actual situation
if result['status']:
return result
elif cnt == retry_cnt:
return result
else:
time.sleep(sleep)
return wrapper
return _decorator
@retry() # Decorator with parameters , Must be added ()
def run_func():
... # ... and pass Consistent function Decorator is a knowledge point that must be known and learned , For streamlining scripts and increasing readability , It has a vital role .
In practice , Some interfaces are asynchronous , Not in real time , When checking , We can't keep the main process waiting , This waste of time and space is not allowed . This is the time , You can start a listening thread , Polling monitor , When a successful or failed result is received , Resynchronize to the main thread to verify the results .
Using threads , We usually use threading library , Here are some common functions of this package .
# The function of the sub thread is func,args Is the parameter of the function
thread = threading.Thread(target=func,args=(arg1,arg2))
# Listen to the main thread , Because it's a script , So the probability of active stop is very high
thread.setDaemon(True)
# The child thread starts running
thread.start()threading Package does not support directly obtaining the result of the calling function , Of course we are threading When starting a child thread , In general , It doesn't pay attention to the return value of the calling function . If you need to get the return value :1. Consider using global variables , After all, the main and sub threads are interlocked through global variables , I usually do it this way ;2. I will threading Extend the , However, the main thread still needs to wait for the execution of the child thread , Generally not recommended ;3. Use process pool , But use concurrent.futures Scene and use of threading The scene is actually different , The scenario of using process pool is the following code CPU heavy, Reduce pressure and speed up execution through multi-core ; and threading The usage scenarios are mostly sub threads and monitoring threads , Wait for an execution result , stay I/O Recommended for many times .
In practice , Will find , A lot of code is actually playing list, Of course, when writing interface use cases ,json Also very much , but json Just according to the corresponding key Get the corresponding value, It doesn't involve a lot of operations ; and list We need a lot of processing operations . Actually python Built in many list Related functions , You don't need to do it yourself , So understand the functions of these built-in functions , It is very important to improve the efficiency of code writing .

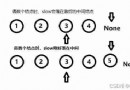
This is a picture about JS in map/filter/reduce Analytic graph of function , But for python Is also very appropriate
Anonymous functions , Only use it once or the logic is simple , You can use this function .
Yes sequence Medium item Execute sequentially function(item), The execution result is output as list.
filter
Yes sequence Medium item Execute sequentially function(item), The result of execution is True(!=0) Of item Form a List/String/Tuple( Depending on sequence The type of ) return ,False The exit (0), To filter .
reduce
Yes sequence Medium item Sequential iteration call function, The function must have 2 Parameters . If there is a 3 Parameters , Indicates the initial value , You can continue to call the initial value , Returns a value .
from functools import reduce
# Each element Cube
print(list(map(lambda x: x ** 3, [1, 2, 3, 4, 5])))
# Filter odd
print(list(filter(lambda x: x % 2 == 1, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])))
# Multiply all elements ,reduce stay functools In the library
print(reduce(lambda x, y: x * y, [1, 2, 3, 4, 5]))Function is used to traverse a data object ( As listing 、 Tuples or strings ) Combined into an index sequence , List both data and data index , Provide start As the starting index ( The general index is 0 Start , But it can go through start From definition ).
list1 = ["a", "b", "c", "d"]
for index, value in enumerate(list1,1):
print({index: value})
----------------------------------
{1: 'a'}
{2: 'b'}
{3: 'c'}
{4: 'd'}Yes List、Dict Built in functions for sorting , It can sort multiple fields together .
# Through the first a Corresponding value Sort , And then through b Corresponding value In reverse order
a = [{"a": 1, "b": 1, "c": "abc", "d": "a"}, {"a": 2, "b": 1, "c": "gbt", "d": "b"}, {"a": 1, "b": 2, "c": "abt", "d": "a"}, {"a": 2, "b": 2, "c": "erg", "d": "b"}]
print(sorted(a, key=lambda x: (int(x['a']), -int(x['b']))))
----------------------------------
[{'a': 1, 'b': 2, 'c': 'abt', 'd': 'a'}, {'a': 1, 'b': 1, 'c': 'abc', 'd': 'a'}, {'a': 2, 'b': 2, 'c': 'erg', 'd': 'b'}, {'a': 2, 'b': 1, 'c': 'gbt', 'd': 'b'}]python Of course, there are many built-in functions , The above are commonly used , But it is easy to ignore , Knowing this can greatly improve the efficiency of writing code . among map/filter/erduce These three functions need attention , What they finally returned was a iteration, Is not list, So you need to turn around , Or use this directly iteration It's fine too .
Limited to ability and space , Just sum up the above knowledge points . But in view of my work experience , The above knowledge points are more important , And it is easy to ignore , Master and use these flexibly , It is important to improve work efficiency , I hope it can help you , thank you ~~~