CDA Data Analyst Produce
author :CDALevel Ⅰ Certificate holder
Position : Data Analyst
industry : big data
background
The e-commerce industry has developed very rapidly in recent years , Many people who are employed in traditional industries but whose salary is not ideal are transferred to the online e-commerce industry . This trend has led more and more people to use products with e-commerce value , It goes without saying , Such as online shopping . let me put it another way , The result of a large number of online shopping is an increase in the amount of data . In the face of such big data , And sometimes unstructured data such as product reviews , How to deal with it ? How to extract useful information from it ? Naturallanguageprocessing technology gives the answer , From rule extraction to statistical modeling to today's very hot in-depth learning , Can extract useful business value from the text , Whether it's a merchant or a buyer . This article focuses on a certain e-commerce platform AirPods The sales of smart earphones and relevant product information are used for emotional analysis and rapid word cloud construction . Emotion analysis is also a direction in naturallanguageprocessing
In addition to mining text , This article also wants to build a web page APP.Python It is a popular programming language at present , utilize Python Build a web page APP What is commonly used is Python combination Flask perhaps Django Framework to run through the front and back to build web pages . Using this method generally requires some front-end experience , To modify the CSS、HTML、JAVASCRIPT These documents . For those without front-end experience coder, Readers here recommend a friendly full course based on Python The library of streamlit, That is, the library used in this article . utilize streamlit Can easily and quickly build a web page APP, Then add the text mining function . such , Just made a small product . below , Get to the point .
In this paper Anaconda Conduct Python compile , It mainly involves Python modular :
streamlit
pandas
cnsenti
stylecloud
time
This chapter is divided into three parts to explain :
1. Data exploratory analysis and product comment text extraction
2. Cloud picture visualization and emotion analysis of commodity reviews
3. Web page structure design and implementation
4. Function integration and effect presentation
01、 Data exploratory analysis and product comment text extraction
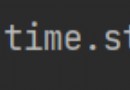
The data adopted in this paper is the commodity review data on a Ning e-commerce platform . The data field has a product title 、 Price 、 Evaluation content . among , The price is in the near future 4 Real time prices for the month . The evaluation content is presented from near to far in chronological order . Here are the first five lines :
It should be noted that , The top five lines show AirPods The first 2 Product information of the agent . The reason is that the data was originally divided into 3 A watch , The fields of each table are the same , in total 3 individual ,2 Dimension fields and 1 Measurement fields ( This is in CDA I Data structures will be mentioned in the course ). therefore , This data is 3 A table splices records through vertical consolidation . Last generated Index Is the primary key generated by the new table .
The data can then be subjected to appropriate exploratory analysis , First, habitually observe the data shape 、 Data type and missing values 、 outliers 、 duplicate value . Missing value utilization pandas Library isnull().sum() Function to view . Repeated value utilization duplicated().sum() that will do . And repetition because this article explores the product comment text and the amount of data is small , Therefore, this article ignores . Here are the results of each part
The data shape is (1020,3), That makes sense , Namely 1020 Record lines ,3 A field . Data type utilization info() Function , give the result as follows :

The above results are analyzed :Non-NULL Count Is the non empty value of each field and . You can see , The evaluation content dimension field has 2 A null value . On the right Dtype Indicates that all three fields are strings object type .memory usage For the occupied byte space of the product information table on this page , Yes 24kb. Here's an extra reminder , If a form has 5G above , That is to say Excel When the software is difficult to open , It can be implemented in another way , Use dask library , It is a kind of distributed data processing package.
From above info You can know from the information , In the blank space of this product information form is 2 individual , That is, the missing value is 2. The repeated value is calculated as 19 individual . The next step is to solve the missing values and duplicate values , Considering that repeated values will affect the results of subsequent word frequency statistics , In this paper, we consider eliminating duplicate values . The missing value will affect the following steps of word segmentation for the evaluation content , So here we choose to replace with spaces . The whole code is as follows , Just started switching to Python You can keep this code in mind , This is necessary for almost every data analysis .
import pandas as pd
df = pd.read_excel(‘ Suning e-buy _airpods series .xlsx’)
df.isnull().sum() # Missing values summary
df.duplicated().sum() # Summary of duplicate values
df.info() # Form information abstract
df.dtypes # data type
df[‘ Evaluation content ’] = df[‘ Evaluation content ’].fillna(’ ') # Fill in the blanks
df = df.drop_duplicates() # Eliminate duplicate values
stay 3 Of the fields , What needs to be extracted most is the evaluation content , Because the purpose of this paper is to build a commodity comment text information mining system , Functions include emotion analysis 、 Visualization of word cloud image . And every user ID The contents of the evaluation are inconsistent , therefore , You need to do aggregation . Integrate all evaluation content , Also remove the stop words , Finally form a sentence , Although this sentence is not smooth , But it has no effect on the following word frequency statistics .
The content of the integrated evaluation adopts Python Built in functions for split() complete , The first use of Pandas In the library tolist() The function changes the record of the evaluation content field into a list , Then convert the list to a string , I need to use split() Function completion . Use the space string as the connector , Connect every element in the list . The final effect is intercepted as follows :

Then it is to remove the stop words , Stop words no matter in Chinese NLP The task is still in English NLP Mission , All need to use this step . This step can not only remove most of the noise , At the same time, it can also save computing resources , More efficient . The algorithm for removing stop words is actually very simple , It is to traverse the text that needs statistical mining , If there is a word in the text that belongs to the specified stop word , Just remove it . obviously , Here we need to stop using thesaurus , There are many inactive vocabularies , There is Baidu's stoplist 、 There is a stoplist of Harbin Institute of technology 、 There are deactivation tables for the Machine Intelligence Laboratory of Sichuan University, etc . In this paper, we choose the stoplist of Harbin Institute of technology , Because this table has better words in the field of e-commerce than other tables . If the reader wants to do an ideal project , You can consider building your own stoplist in the field of e-commerce .
The specific codes and practices for removing stop words will be explained in the emotional analysis section .
02、 Cloud picture visualization and emotion analysis of commodity reviews
In the previous section, we extracted each item in the item information table ID The content of commodity evaluation , At the same time, we should integrate them to remove the stop words , Got a clean txt Data sets . Then we can do text mining . The first is the construction of the cloud picture of commodity reviews .
stay Python There are many libraries built by Chinese word cloud pictures , The common one is Wordcloud Standard word cloud visualization Library , also pyecharts Cloud picture of words API. The former is used to construct the word cloud map , Novice users often have a lot of problems , such as pip Installation failed 、 Coding errors 、 Wrong font use, etc , besides , In fact, it is very difficult to use . The latter is an interactive chart commonly used in browsers , It is based on code quantity , It is famous for its high encapsulation , It sounds more relevant to the topic of this article , But this article does not consider , The reason is that the web page development library used later streamlit To display an interactive chart, you usually don't have to pyecharts.
therefore , Here, this paper introduces a new word cloud visualization library stylecloud, This library is based on wordcloud Of . Use this library , Novices can draw various word clouds with the least amount of code , Support shape settings . Don't talk much , Go straight to the code :
start = time.time() # Record the initial time
stop_words = open(‘ Stoppage vocabulary of Harbin Institute of Technology .txt’,‘r’,encoding=‘utf8’).readlines() # Read stop words
stylecloud.gen_stylecloud(text=txt, collocations=True, # Whether to include the collocation of two words ( Two word group )
font_path=r’C:\Windows\Fonts\simkai.ttf’, # Specified font
icon_name=‘fab fa-jedi-order’,size=(2000,2000), # Specify the style
output_name=r’img\ Clouds of words .png’, # Specify the output image file path
custom_stopwords=stop_words) # Specify a stoplist
end = time.time() # Record the end time
spend = end-start # The total drawing time
Code parsing :
First introduce stylecloud library , And then use .gen_stylecloud() Object to initialize the drawing object ( class ).
text The parameter represents the target text , That is, the product reviews we have handled txt Text .
collocations It means whether to include the collocation of two words ( Two word group ), The default is True.
font_path It is the font of this machine , The default location is C:\Windows\Fonts\ This folder , Users can choose any font in this folder according to their preferences , You can also download additional .
icon_name This parameter can be said to be stylecloud The soul of the library , It can set the form of mask . Of course , This parameter cannot be scrawled . All friends who have created CI cloud pictures know , It is interesting to set the mask style by yourself, but the resolution will be very low . To solve this problem ,Font Awesome An excellent solution has been achieved , That is to construct a set of icon font library and CSS frame , For users to call . Users can not only call up high-definition icons , And you can customize CSS file , Add or modify to your liking . and stylecloud This library is the content used to call this website , Users can use the stylecloud\static Found in folder fontawesome.min.cssCSS file , This contains a lot of vector icons .
The reader will ask , How do you know these icons name? Here are two websites :
https://fontawesome.dashgame.com/. Here are the names of various vector icons , Users can use different types of icon styles , The gesture related styles are shown in the following figure :
size For picture size .
output_name The path and name of the output picture
custom_stopwords For reference to our custom stoplist , That is, to start with open The function code calls up the stop vocabulary of Harbin Institute of technology , Here is a part of the stoplist for display , You can see that it starts with the elimination of useless punctuation minus signs 
besides , This article also sets the time interval , Because it is said that it takes a long time to depict the cloud picture of well-known words , If the text is long , A minute is possible . So add the concept of time , It will also be friendly for users to transfer data .
such , We have built the word cloud map , Will be applied in the next part of the web side , Here we use Airpods Example of the second generation , First on the renderings

After the word cloud map is constructed, it is the turn of emotion analysis , It is very useful to do emotional analysis on clean product review information . For the business, it can clearly know the buyer's feeling and evaluation of using this product , In order to optimize the product later , It is more useful for those who want to buy this product . This article will AirPods Statistics of positive and negative emotion words in commodity reviews .
The library used is cnsenti, This library is a Chinese emotion analysis library . stay NLP In the task area , Most of the libraries and examples are in English , Therefore, this Chinese database is good news for those who often mine Chinese texts !
First of all, let's introduce the library ,cnsenti The module is divided into two parts , One is the object of emotional analysis used in this paper Sentiment, The other is not used for emotion analysis Emotion. The dictionary used in emotion analysis is HowNet Hownet, Support customization . Emotion analysis uses the emotion ontology database of Dalian University of technology , It can calculate the distribution of seven emotional words in the text . Because this article only uses the emotion analysis object class , Therefore, interested readers can learn emotion analysis by themselves .
Yes AirPods Emotional analysis of product review information , By default , Only 2 Sentence code . Yes , It's so convenient !
senti = Sentiment()
result = senti.sentiment_count(txt)
txt For our target text , First, you need to call the emotion analysis class Sentiment(), If no parameters are set , This means that the default condition is used to initialize . Then use sentiment_count() Function to calculate the statistics of positive and negative emotion words , With AirPods Example of the second generation , The results are as follows :

The above results show that : There are... Words in total 18128 individual , Sentences have 625 sentence . Positive emotional words are 2221, Negative emotional words are 322 individual .
In emotion analysis , except sentiment_count() function , also sentiment_calculate() function , What's the difference ? This can more accurately calculate the emotional information of the text . Compared with sentiment_count Only count the number of positive and negative emotional words in the text ,sentiment_calculate We also consider whether the intensity adverbs before and after the emotional words modify , Whether there is emotional semantic inversion of negative words before and after emotional words . The same to AirPods Product examples , Use this function , The result is zero

You can see , The positive words identified should be the use of weighted means to increase the frequency dimension to a numerical value .
03、 Web page structure design and implementation
The next step is web page structure design , The first step in making a web page is to construct a thought map , Determine what the function is , What controls are there , How the controls are placed . For functions , The topic of this paper is the text mining of commodity comment information , First, integrate the initial text of the product review into the de stop words . Then use stylecloud Library to build word cloud , Finally, emotional analysis . besides , The author also hopes to complete the following functions :
Various products (3 generation AirPods Smart headset ) Analyze separately , That is, different from the above steps , There is no need to merge records vertically through fields .
The original table structure type data can be displayed on the web page .
Add some by markdown Written profile
Through one dataframe The original table and text mining results are displayed separately
OK, that's all . Through the above functions , This article can determine which controls are written :
Text control , Used to store profiles 、 Positive and negative emotional word value ratio 、 It takes time to build the word cloud second.
Images (graph) Control , Used to store locally stored word cloud pictures , In the web End show .
dataframe Control , Used to display the original table structure type data
sidebar Sidebar controls , It is equivalent to the sidebar directory we usually see on major websites , However, the sidebar function of this article is different .
Text controls under the sidebar .
selectbox Single drop-down selection box control , Storage AirPods Various models , It is equivalent to completing the function of type analysis
radio Radio button controls , Store display types : The original table structure data type or text mining results are displayed .
Build according to the regular web page , The spatial arrangement of control position must be designed . But for the novice , The next step is super web app Building streamlit There is no need to consider .
streamlit The official (https://streamlit.io/) The introduction is as follows :
The fastest way to build on sharing data app, Display data in a sharable web app On , With python Programming language implementation , No front-end experience .Streamlit Is the first application development framework for machine learning and data science teams , It's the fastest way to develop custom machine learning tools , It can help machine learning engineers develop user interaction tools quickly . And it is based on tornado frame , Encapsulates a large number of interactive components , It also supports a large number of tables 、 Chart 、 Rendering of objects such as data tables , And support grid responsive layout .Streamlit The default rendering language for is markdown; in addition to ,Streamlit Also support html Rendering of text , This means that you can also put any html The code is embedded in streamlit In the application .
Readers may wonder about making websites , Think the front and back ends are used Python+streamlit It's a common thing . It's not , stay streamlit Before it was built ,web creator with python Generally, the front end is used html、css、JavaScript, The back-end using python、Flask、Django. If not Python, Both front and rear ends are used D3.
therefore , Used in this article Python+streamlit Front and rear end penetrations are created web app How friendly to novices !
next , First show streamlit A quick way to use :
First pip install streamlit Install this library , Then type... On the command line streamlit hello. A window will pop up , This is the built-in help document for opening , There are various examples , Here are some screenshots :
First of all , A page that records help information , There are various connections stored inside

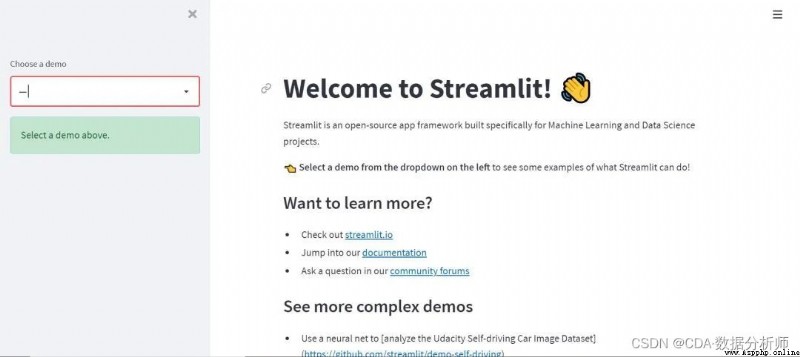
Then select... From the drop-down box plotting demo, Click to display the following :
This is a drawing program loaded with a record bar , It can be interactive .
Sum up , You can find , function streamlit Not in anaconda etc. python The compiler runs , But in the command box cmd Input in streamlit run .py File to run the program .
If you are interested, you can take a dip streamlit Its official website , You can learn a lot .
04、 Function integration and effect presentation
The last part is the web app Construction and function integration part . On the first code
import streamlit as st
import pandas as pd
from cnsenti import Sentiment
import stylecloud
import time
st.title(‘AirPods Smart headset product review and analysis system ’)
st.markdown(‘ This data analysis system will mine three kinds of Apple products under an e-commerce company in a visual form AirPods Product review information for models ’)
st.markdown(‘Apple AirPods It's an apple branded wireless headset . At present, the mainstream of sales in the market is 3 Middle model :AirPods2 generation 、Airpods pro、AirPods The three generation . The main features of this headset are : The built-in infrared sensor of the earphone can automatically identify whether the earphone plays automatically in the middle of the ear , You can control by double clicking Siri control . Bring earphones to play music automatically , The beam microphone works better , Double click the headset to turn it on Siri, The charging box supports long-term endurance , The connection is very simple , Just open it to let iPhone Automatic identification .’)
st.sidebar.title(‘ Data analysis system control ’)
st.sidebar.markdown(‘ Choose a model / Visualization type :’)
DATA_URL=(‘ Suning e-buy _airpods series .xlsx’)
def load_data():
data=pd.read_excel(DATA_URL)
return data
df = load_data()
df[‘ Evaluation content ’] = df[‘ Evaluation content ’].fillna(’ ') # Fill in missing values
select = st.sidebar.selectbox(‘ Choose a model ’,df[‘ Commodity title ’].unique())
state_data = df[df[‘ Commodity title ’] == select]
select_status = st.sidebar.radio(“ Visualization type ”, (‘ Table structure data ’,‘ Text mining ’))
if select_status == ‘ Table structure data ’:
st.text(‘ Relevant data about the products sold by the e-commerce company in the near future ( Display in table structure )’)
st.dataframe(state_data)
if select_status == ‘ Comment Visualization ’:
# Judge the positive and negative emotional value of goods
txt_list = state_data[' Evaluation content '].tolist()
txt = ' '.join(txt_list)
senti = Sentiment()
result = senti.sentiment_count(txt)
start = time.time()
# First draw the word cloud inside and save it to image Folder
stop_words = open(' Stoppage vocabulary of Harbin Institute of Technology .txt','r',encoding='utf8').readlines()
stylecloud.gen_stylecloud(text=txt, collocations=True,
font_path=r'C:\Windows\Fonts\simkai.ttf',
icon_name='fab fa-jedi-order',size=(2000,2000),
output_name=r'img\ Clouds of words .png',
custom_stopwords=stop_words)
end = time.time()
spend = end-start
# Show the positive and negative values of emotion on the web page
if result['pos'] > result['neg']:
st.markdown("#### The positive / negative emotional value ratio of the product is {}:{}, Positive signals ".format(result['pos'],result['neg']))
if result['pos'] < result['neg']:
st.markdown("#### The positive / negative emotional value ratio of the product is {}:{}, A negative signal ".format(result['pos'],result['neg']))
# Show word cloud
st.image(r'img\ Clouds of words .png',caption = ' Clouds of words ')
st.text(' Run time :{} s'.format(spend))
Code parsing :
First introduce the first five lines after the package , Is to set this web app The title of the , by AirPods Smart headset product review and analysis system . Then the following is the subtitle for recording the brief information of the program . Store some at the same time AirPods The introduction of this apple smartphone and its unique features . besides ,st.sidebar() This function moves the target from the main page to the sidebar , Fill in the sidebar with the information you need to fill in .
Then comes the loading data explained in the first part 、 Data exploratory analysis , Remove duplicate values , Fill in missing values and other operations .
select = st.sidebar.selectbox(‘ Choose a model ’,df[‘ Commodity title ’].unique()) This sentence is to remove the duplicate product title in the product information table , namely AirPods The third generation models are used as the values for radio selection in the drop-down box . After selecting this value , You can use it pandas Filter by conditions , Last use st.dataframe() Function to display the table structure type .
select_status = st.sidebar.radio(“ Visualization type ”, (‘ Table structure data ’,‘ Text mining ’)) Represents setting the value of the radio selection button , Which page is displayed on the main page , Is table type data , Or text mining results : Word cloud picture and emotion analysis results .
if The statement is set as follows : according to state_data result , The extracted data is AirPods One of the three generations , Then note that the table data type or emotion analysis displayed on the home page is based on the relevant product information of this generation of models . next if A statement is a decision select_status Is it table structured data or text mining , Because in the initial setup of this article , Only two kinds of visualizations are displayed on the main page .
The second one if Statement to text mining , It is also used for emotion analysis . In the second part, we talk about , This paper calculates the proportion of positive and negative emotional words . If positive emotional words ( Positive emotional vocabulary ), Then run st.markdown(“#### The positive / negative emotional value ratio of the product is {}:{}, Positive signals ”.format(result[‘pos’],result[‘neg’])), Show positive signals . conversely , Is a negative signal .
Here's one time Module reference , This reference is used to calculate the construction time of the word cloud graph , Around the 30s about . This kind of performance test and evaluation is often used in the work , Because the data in the work is not as big as that in the examples in this article .
The code of word cloud construction is also mentioned in the second part , It can be directly embedded here . Simultaneous utilization st.image Function to read and display local pictures .
besides ,streamlit Another friendly point is , Can support writing markdown Code , Most of the above text controls use markdown To write , Regular use markdown Our readers can study a wave of .