諸神緘默不語-個人CSDN博文目錄
本文將介紹jieba、HanLP、LAC、THULAC、NLPIR、spacy等多種常用的Python中文分詞工具的簡單使用方法。
官方GitHub項目:fxsjy/jieba: 結巴中文分詞
安裝方式:pip install jieba
精確模式:jieba.cut(text)返回一個迭代器,每個元素是一個詞語。(lcut()直接返回list)
import jieba
print(' '.join(jieba.cut('行動才是果實,言辭不過是枝葉。')))
輸出:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.455 seconds.
Prefix dict has been built successfully.
行動 才 是 果實 , 言辭 不過 是 枝葉 。
cut()函數的參數:
HMM:發現新詞功能,自動計算的詞頻(下文自定義詞典部分)可能無效。use_paddle:paddle模式:使用後無法自定義詞典,據我猜測應該跟LAC包一樣,所以不如直接用LAC包。使用jieba.enable_parallel()可以開啟並行分詞模式(按行分隔文本),不支持Windows。入參是並行進程數,如無入參默認為CPU個數。jieba.disable_parallel() 關閉並行分詞模式
①添加自定義詞典:jieba.load_userdict(file_name) file_name 為文件類對象或自定義詞典的路徑。
詞典格式和 https://github.com/fxsjy/jieba/blob/master/jieba/dict.txt 一樣,一個詞占一行;每一行分三部分:詞語、詞頻(可省略)、詞性(可省略),用空格隔開,順序不可顛倒。file_name 若為路徑或二進制方式打開的文件,則文件必須為 UTF-8 編碼。
詞頻省略時使用自動計算的能保證分出該詞的詞頻。
②調整詞典:add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中動態修改詞典。
使用 suggest_freq(segment, tune=True) 可調節單個詞語的詞頻,使其能(或不能)被分出來。
使用自定義詞典的示例:https://github.com/fxsjy/jieba/blob/master/test/test_userdict.py
使用jieba.posseg替換jieba,還能返回詞性標注。
使用jieba.tokenize()還能返回詞語在原文中的起止位置,入參只接受Unicode。
如果只有用戶文件夾的權限而沒有/tmp的權限,則會報警告信息,可以改變分詞器(默認為jieb.dt)的tmp_dir和cache_file屬性來解決這一問題。
官方GitHub項目:hankcs/HanLP: 中文分詞 詞性標注 命名實體識別 依存句法分析 成分句法分析 語義依存分析 語義角色標注 指代消解 風格轉換 語義相似度 新詞發現 關鍵詞短語提取 自動摘要 文本分類聚類 拼音簡繁轉換 自然語言處理
官網:HanLP在線演示 多語種自然語言處理
需要申請密鑰,因此還沒用過,待補。
官方GitHub項目:baidu/lac: 百度NLP:分詞,詞性標注,命名實體識別,詞重要性
論文引用:
@article{jiao2018LAC,
title={Chinese Lexical Analysis with Deep Bi-GRU-CRF Network},
author={Jiao, Zhenyu and Sun, Shuqi and Sun, Ke},
journal={arXiv preprint arXiv:1807.01882},
year={2018},
url={https://arxiv.org/abs/1807.01882}
}
安裝方式 :pip install lac 或 pip install lac -i https://mirror.baidu.com/pypi/simple
extracted_sentences="隨著企業持續產生的商品銷量,其數據對於自身營銷規劃、市場分析、物流規劃都有重要意義。但是銷量預測的影響因素繁多,傳統的基於統計的計量模型,比如時間序列模型等由於對現實的假設情況過多,導致預測結果較差。因此需要更加優秀的智能AI算法,以提高預測的准確性,從而助力企業降低庫存成本、縮短交貨周期、提高企業抗風險能力。"
from LAC import LAC
lac=LAC(mode='seg') #默認值mode='lac'會附帶詞性標注功能,對應的標簽見後文
seg_result=lac.run(extracted_sentences) #以Unicode字符串為入參
print(seg_result)
seg_result=lac.run(extracted_sentences.split(',')) #以字符串列表為入參,平均速率會更快
print(seg_result)
輸出:
W0625 20:03:29.850801 32781 init.cc:157] AVX is available, Please re-compile on local machine
W0625 20:03:29.868482 32781 analysis_predictor.cc:518] - GLOG's LOG(INFO) is disabled.
W0625 20:03:29.868522 32781 init.cc:157] AVX is available, Please re-compile on local machine
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [fc_lstm_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
['隨著', '企業', '持續', '產生', '的', '商品', '銷量', ',', '其', '數據', '對於', '自身', '營銷', '規劃', '、', '市場分析', '、', '物流', '規劃', '都', '有', '重要', '意義', '。', '但是', '銷量', '預測', '的', '影響', '因素', '繁多', ',', '傳統', '的', '基於', '統計', '的', '計量', '模型', ',', '比如', '時間', '序列', '模型', '等', '由於', '對', '現實', '的', '假設', '情況', '過多', ',', '導致', '預測', '結果', '較差', '。', '因此', '需要', '更加', '優秀', '的', '智能', 'AI', '算法', ',', '以', '提高', '預測', '的', '准確性', ',', '從而', '助力', '企業', '降低', '庫存', '成本', '、', '縮短', '交貨', '周期', '、', '提高', '企業', '抗', '風險', '能力', '。']
[['隨著', '企業', '持續', '產生', '的', '商品', '銷量'], ['其', '數據', '對於', '自身', '營銷', '規劃', '、', '市場分析', '、', '物流', '規劃', '都', '有', '重要', '意義', '。', '但是', '銷量', '預測', '的', '影響', '因素', '繁多'], ['傳統', '的', '基於', '統計', '的', '計量', '模型'], ['比如', '時間', '序列', '模型', '等', '由於', '對', '現實', '的', '假設', '情況', '過多'], ['導致', '預測', '結果', '較差', '。', '因此', '需要', '更加', '優秀', '的', '智能', 'AI', '算法'], ['以', '提高', '預測', '的', '准確性'], ['從而', '助力', '企業', '降低', '庫存', '成本', '、', '縮短', '交貨', '周期', '、', '提高', '企業', '抗', '風險', '能力', '。']]
詞性標注功能的標簽: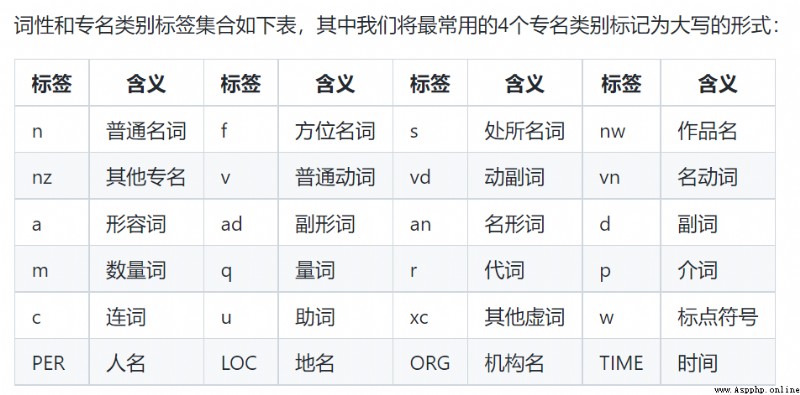
使用自定義詞典:item將不會被分割。
詞典文件每行表示一個定制化的item,由一個單詞或多個連續的單詞組成,每個單詞後使用’/‘表示標簽,如果沒有’/'標簽則會使用模型默認的標簽。每個item單詞數越多,干預效果會越精准。
詞典文件示例:
春天/SEASON
花/n 開/v
秋天的風
落 陽
在run()之前就使用代碼:
# 裝載干預詞典, sep參數表示詞典文件采用的分隔符,為None時默認使用空格或制表符'\t'
lac.load_customization('custom.txt', sep=None)
官網:THULAC:一個高效的中文詞法分析工具包
在線演示網址:THULAC:一個高效的中文詞法分析工具包
我看到說模型下載需要申請,因此還沒使用過,待補。
官方GitHub項目:NLPIR-team/NLPIR
官網:NLPIR自然語言處理與信息檢索共享平台 – NLPIR Natural Language Processing & Information Retrieval Sharing Platform 自然語言處理、大數據實驗室、智能語義平台 漢語分詞、中文語義分析、中文信息處理、語義分析系統、中文知識圖譜、大數據分析工具
NLPIR漢語分詞系統官網:NLPIR-ICTCLAS漢語分詞系統-首頁
看了一下這個還需要下載軟件,感覺用起來不方便,如果以後真的需要了再補吧。
spacy模型官網:Trained Models & Pipelines · spaCy Models Documentation
extracted_sentences="隨著企業持續產生的商品銷量,其數據對於自身營銷規劃、市場分析、物流規劃都有重要意義。但是銷量預測的影響因素繁多,傳統的基於統計的計量模型,比如時間序列模型等由於對現實的假設情況過多,導致預測結果較差。因此需要更加優秀的智能AI算法,以提高預測的准確性,從而助力企業降低庫存成本、縮短交貨周期、提高企業抗風險能力。"
import zh_core_web_sm
nlp = zh_core_web_sm.load()
doc = nlp(extracted_sentences)
print([(w.text, w.pos_) for w in doc])
輸出:[('隨著', 'ADP'), ('企業', 'NOUN'), ('持續', 'ADV'), ('產生', 'VERB'), ('的', 'PART'), ('商品', 'NOUN'), ('銷量', 'NOUN'), (',', 'PUNCT'), ('其', 'PRON'), ('數據', 'NOUN'), ('對於', 'ADP'), ('自身', 'PRON'), ('營銷', 'NOUN'), ('規劃', 'NOUN'), ('、', 'PUNCT'), ('市場', 'NOUN'), ('分析', 'NOUN'), ('、', 'PUNCT'), ('物流', 'NOUN'), ('規劃', 'NOUN'), ('都', 'ADV'), ('有', 'VERB'), ('重要', 'ADJ'), ('意義', 'NOUN'), ('。', 'PUNCT'), ('但是', 'ADV'), ('銷量', 'VERB'), ('預測', 'NOUN'), ('的', 'PART'), ('影響', 'NOUN'), ('因素', 'NOUN'), ('繁多', 'VERB'), (',', 'PUNCT'), ('傳統', 'ADJ'), ('的', 'PART'), ('基於', 'ADP'), ('統計', 'NOUN'), ('的', 'PART'), ('計量', 'NOUN'), ('模型', 'NOUN'), (',', 'PUNCT'), ('比如', 'ADV'), ('時間', 'NOUN'), ('序列', 'NOUN'), ('模型', 'NOUN'), ('等', 'PART'), ('由於', 'ADP'), ('對', 'ADP'), ('現實', 'NOUN'), ('的', 'PART'), ('假設', 'NOUN'), ('情況', 'NOUN'), ('過', 'ADV'), ('多', 'VERB'), (',', 'PUNCT'), ('導致', 'VERB'), ('預測', 'NOUN'), ('結果', 'NOUN'), ('較', 'ADV'), ('差', 'VERB'), ('。', 'PUNCT'), ('因此', 'ADV'), ('需要', 'VERB'), ('更加', 'ADV'), ('優秀', 'VERB'), ('的', 'PART'), ('智能', 'NOUN'), ('AI算法', 'NOUN'), (',', 'PUNCT'), ('以', 'PART'), ('提高', 'VERB'), ('預測', 'NOUN'), ('的', 'PART'), ('准確性', 'NOUN'), (',', 'PUNCT'), ('從而', 'ADV'), ('助力', 'NOUN'), ('企業', 'NOUN'), ('降低', 'VERB'), ('庫存', 'NOUN'), ('成本', 'NOUN'), ('、', 'PUNCT'), ('縮短', 'VERB'), ('交貨', 'VERB'), ('周期', 'NOUN'), ('、', 'PUNCT'), ('提高', 'VERB'), ('企業', 'NOUN'), ('抗', 'NOUN'), ('風險', 'NOUN'), ('能力', 'NOUN'), ('。', 'PUNCT')]
詞性標注的標簽可參考:Universal POS tags
官網:The Stanford Natural Language Processing Group
這個也需要下載軟件,還需要Java1.8+才能運行,對我來說有些麻煩。待補。