With the popularity of wechat , More and more people are using wechat . Wechat has gradually changed from a simple social software to a lifestyle , People's daily communication needs wechat , Work communication also needs wechat . Every friend in wechat , All represent the different roles people play in society .
Today's article will be based on Python Data analysis of wechat friends , The dimensions selected here mainly include : Gender 、 Head portrait 、 Signature 、 Location , The results are mainly presented in the form of charts and word clouds , among , For text information, we will use word frequency analysis and emotion analysis . As the saying goes : A good workman does his work well , We must sharpen our tools first . Before officially starting this article , Briefly introduce the third-party module used in this article :
itchat: Wechat web page interface encapsulation Python edition , In this article, it is used to obtain wechat friend information .
jieba: Stuttering participle Python edition , In this paper, it is used to segment text information .
matplotlib:Python Chart drawing module in , In this paper, it is used to draw column chart and pie chart
snownlp: One Python Chinese word segmentation module in , In this paper, it is used to make emotional judgment on text information .
PIL:Python Image processing module in , In this paper, it is used to process pictures .
numpy:Python in Numerical calculation module , In this paper, we cooperate with wordcloud Module USES .
wordcloud:Python Word cloud module in , In this paper, it is used to draw word cloud pictures .
TencentYoutuyun: Provided by Tencent Youtu Python edition SDK , In this paper, it is used to recognize face and extract picture label information .
The above modules can be passed pip install , Detailed instructions on the use of each module , Please refer to your own documents .
01
Data analysis
The premise of analyzing wechat friend data is to obtain friend information , By using itchat This module , All this will become very simple , We can do this through the following two lines of code :
itchat.auto_login(hotReload = True)friends = itchat.get_friends(update = True)
It's the same as logging in to the web version of wechat , We can log in by scanning QR code with our mobile phone , Back here friends Object is a collection , The first element is the current user . therefore , In the following data analysis process , We always take friends[1:] As raw input data , Each element in the collection is a dictionary structure , Take myself for example , You can notice that there are Sex、City、Province、HeadImgUrl、Signature These four fields , The following analysis starts with these four fields :

02
Friend gender
Analyze friends' gender , We first need to get the gender information of all our friends , Here we will the information of each friend Sex Field extraction , Then count out Male、Female and Unkonw Number of , We assemble these three values into a list , You can use matplotlib The module draws a pie chart to , Its code implementation is as follows :
def analyseSex(firends):sexs = list(map(lambda x:x['Sex'],friends[1:]))counts = list(map(lambda x:x[1],Counter(sexs).items()))labels = ['Unknow','Male','Female']colors = ['red','yellowgreen','lightskyblue']plt.figure(figsize=(8,5), dpi=80)plt.axes(aspect=1)plt.pie(counts, # Gender statisticslabels=labels, # Gender display labelcolors=colors, # Pie chart area color matchinglabeldistance = 1.1, # The distance between the label and the dotautopct = '%3.1f%%', # Pie chart area text formatshadow = False, # Whether the pie chart shows shadowsstartangle = 90, # The starting angle of the pie chartpctdistance = 0.6 # The distance between the text in the pie chart area and the dot)plt.legend(loc='upper right',)plt.title(u'%s Gender composition of wechat friends ' % friends[0]['NickName'])plt.show()
Here is a brief explanation of this code , The values of wechat gender fields are Unkonw、Male and Female Three , The corresponding values are 0、1、2. adopt Collection Module Counter() These three different values are statistically analyzed , Its items() Method returns a collection of tuples .
The first dimensional element of the tuple represents the key , namely 0、1、2, The second element of the tuple represents the number , And the set of tuples is sorted , That is, press the key 0、1、2 The order of , So pass map() Method can get the number of these three different values , We pass it on to matplotlib Draw it , The percentages of these three different values are determined by matplotlib calculated . The picture below is matplotlib Draw the gender distribution map of friends :
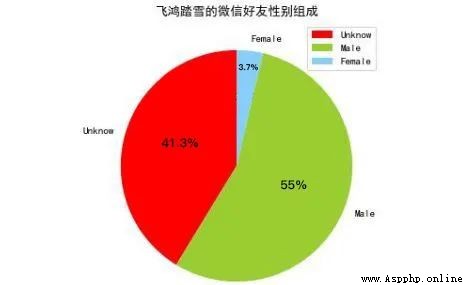
03
My friend's picture
Analyze friends' avatars , Analyze from two aspects , First of all , Among these friends' avatars , What is the proportion of friends who use facial avatars ; second , From these friends' avatars , What valuable keywords can be extracted .
It needs to be based on HeadImgUrl Field download avatar to local , Then through the face recognition related information provided by Tencent Youtu API Interface , Detect whether there are faces in the avatar picture and extract the labels in the picture . among , The former is a subtotal , We use pie charts to present the results ; The latter is to analyze the text , We use word clouds to present the results . The key code is as follows :
def analyseHeadImage(frineds):# Init PathbasePath = os.path.abspath('.')baseFolder = basePath + '\\HeadImages\\'if(os.path.exists(baseFolder) == False):os.makedirs(baseFolder)# Analyse ImagesfaceApi = FaceAPI()use_face = 0not_use_face = 0image_tags = ''for index in range(1,len(friends)):friend = friends[index]# Save HeadImagesimgFile = baseFolder + '\\Image%s.jpg' % str(index)imgData = itchat.get_head_img(userName = friend['UserName'])if(os.path.exists(imgFile) == False):with open(imgFile,'wb') as file:file.write(imgData)# Detect Facestime.sleep(1)result = faceApi.detectFace(imgFile)if result == True:use_face += 1else:not_use_face += 1# Extract Tagsresult = faceApi.extractTags(imgFile)image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))labels = [u' Use face faces ',u' Don't use face avatars ']counts = [use_face,not_use_face]colors = ['red','yellowgreen','lightskyblue']plt.figure(figsize=(8,5), dpi=80)plt.axes(aspect=1)plt.pie(counts, # Gender statisticslabels=labels, # Gender display labelcolors=colors, # Pie chart area color matchinglabeldistance = 1.1, # The distance between the label and the dotautopct = '%3.1f%%', # Pie chart area text formatshadow = False, # Whether the pie chart shows shadowsstartangle = 90, # The starting angle of the pie chartpctdistance = 0.6 # The distance between the text in the pie chart area and the dot)plt.legend(loc='upper right',)plt.title(u'%s Your wechat friends use facial avatars ' % friends[0]['NickName'])plt.show()image_tags = image_tags.encode('iso8859-1').decode('utf-8')back_coloring = np.array(Image.open('face.jpg'))wordcloud = WordCloud(font_path='simfang.ttf',background_color="white",max_words=1200,mask=back_coloring,max_font_size=75,random_state=45,width=800,height=480,margin=15)wordcloud.generate(image_tags)plt.imshow(wordcloud)plt.axis("off")plt.show()
Here we will create a new... In the current directory HeadImages Catalog , Used to store the avatars of all friends , Then we'll use a name here FaceApi class , This class is created by Tencent Youtu SDK Come in a package , Face detection and image label recognition are called here respectively API Interface , The former will count ” Use face faces ” and ” Don't use face avatars ” The number of your friends , The latter will accumulate the tags extracted from each avatar . The analysis results are shown in the figure below :
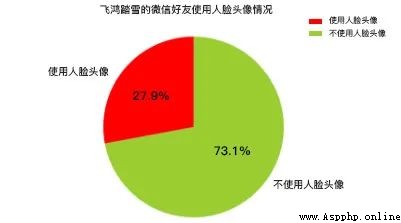
It can be noted that , Among all wechat friends , It's close to 1/4 Our wechat friends use facial avatars , And there is proximity 3/4 My wechat friends don't have faces , This shows that among all wechat friends ” Level of appearance “ Confident people , It only accounts for... Of the total number of friends 25%, Or say 75% Our wechat friends are mainly on the low side , I don't like making wechat avatars with face avatars .
secondly , Considering that Tencent Youtu can't really identify ” Face ”, Here we extract the tags in the friends' avatars again , To help us understand the keywords in the avatar of wechat friends , The analysis results are shown in the figure :

Through word cloud , We can find out : In the signature words of wechat friends , Keywords with relatively high frequency are : The girl 、 tree 、 House 、 Text 、 Screenshot 、 cartoon 、 A group photo 、 sky 、 The sea . This shows that among my wechat friends , Wechat avatars selected by friends mainly include daily 、 tourism 、 scenery 、 Screenshot four sources .
The style of wechat avatar selected by friends is mainly cartoon , The common elements in the wechat avatar selected by friends are sky 、 The sea 、 House 、 tree . By observing the avatars of all your friends , I found that among my wechat friends , Using personal photos as wechat avatars are 15 people , Using network pictures as wechat avatars are 53 people , Using animation pictures as wechat avatars are 25 people , Using group photos as wechat avatars are 3 people , Using children's photos as wechat avatars are 5 people , Some people who use landscape pictures as wechat avatars are 13 people , Some people who use girls' photos as wechat avatars are 18 people , It is basically consistent with the analysis results of image label extraction .
04
Friend signature
Analyze friends' signatures , Signature is the most abundant text information in friend information , According to the usual human ” Label ” Methodology of , Signature can analyze a person's state in a certain period of time , Just like people laugh when they are happy 、 Sad will cry , Cry and laugh , It shows that people are happy and sad .
Here we deal with signatures in two ways , The first is to use stuttering word segmentation to generate word cloud , The purpose is to understand the keywords in the friend signature , Which keyword appears relatively frequently ; The second is to use SnowNLP Analyze the emotional tendencies in friends' signatures , That is, friends' signatures are generally positive 、 Negative or neutral , What are their respective proportions . Extract here Signature Field can be , The core code is as follows :
def analyseSignature(friends):signatures = ''emotions = []pattern = re.compile("1f\d.+")for friend in friends:signature = friend['Signature']if(signature != None):signature = signature.strip().replace('span', '').replace('class', '').replace('emoji', '')signature = re.sub(r'1f(\d.+)','',signature)if(len(signature)>0):nlp = SnowNLP(signature)emotions.append(nlp.sentiments)signatures += ' '.join(jieba.analyse.extract_tags(signature,5))with open('signatures.txt','wt',encoding='utf-8') as file:file.write(signatures)# Sinature WordCloudback_coloring = np.array(Image.open('flower.jpg'))wordcloud = WordCloud(font_path='simfang.ttf',background_color="white",max_words=1200,mask=back_coloring,max_font_size=75,random_state=45,width=960,height=720,margin=15)wordcloud.generate(signatures)plt.imshow(wordcloud)plt.axis("off")plt.show()wordcloud.to_file('signatures.jpg')# Signature Emotional Judgmentcount_good = len(list(filter(lambda x:x>0.66,emotions)))count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions)))count_bad = len(list(filter(lambda x:x<0.33,emotions)))labels = [u' Negative negative ',u' Neutral ',u' Positive ']values = (count_bad,count_normal,count_good)plt.rcParams['font.sans-serif'] = ['simHei']plt.rcParams['axes.unicode_minus'] = Falseplt.xlabel(u' Emotional judgment ')plt.ylabel(u' frequency ')plt.xticks(range(3),labels)plt.legend(loc='upper right',)plt.bar(range(3), values, color = 'rgb')plt.title(u'%s Wechat friend signature information emotional analysis ' % friends[0]['NickName'])plt.show()
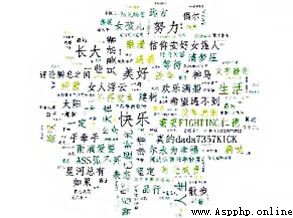
Through word cloud , We can find out : In the signature information of wechat friends , Keywords with relatively high frequency are : Strive 、 Grow up 、 happy 、 happy 、 life 、 Happiness 、 life 、 distance 、 time 、 take a walk .
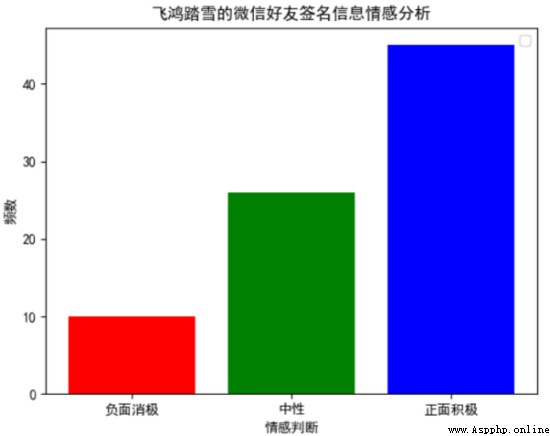
Through the following histogram , We can find out : In the signature information of wechat friends , Positive emotional judgment accounts for about 55.56%, Neutral emotional judgment accounts for about 32.10%, Negative emotional judgments account for about 12.35%. This result is basically consistent with the result we show through word cloud , This shows that in the signature information of wechat friends , There are about 87.66% Signature information for , It conveys a positive attitude .
05
Friend location
Analyze friend locations , Mainly by extracting Province and City These two fields .Python Map visualization in mainly through Basemap modular , This module needs to download map information from foreign websites , It's very inconvenient to use .
Baidu ECharts Used more at the front end , Although the community provides pyecharts project , But I noticed that because of the change of policy , at present Echarts The ability to export maps is no longer supported , Therefore, the customization of maps is still a problem , The mainstream technical scheme is to configure the equipment of provinces and cities all over the country JSON data .
What I'm using here is BDP Personal Edition , This is a zero programming scheme , We go through Python Export a CSV file , Then upload it to BDP in , You can create a visual map by simply dragging , It can't be simpler , Here we just show the generation CSV Part of the code :
def analyseLocation(friends):headers = ['NickName','Province','City']with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:writer = csv.DictWriter(csvFile, headers)writer.writeheader()for friend in friends[1:]:row = {}row['NickName'] = friend['NickName']row['Province'] = friend['Province']row['City'] = friend['City']writer.writerow(row)
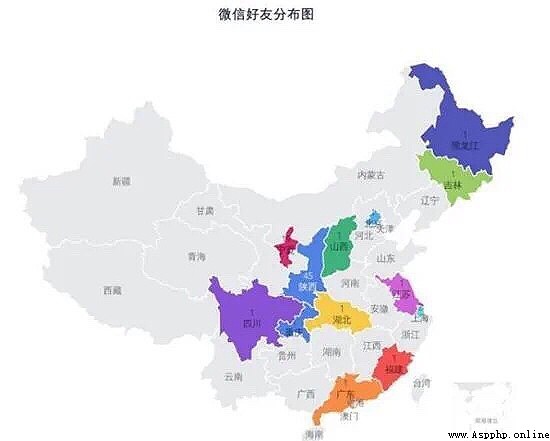
The picture below is BDP The geographical distribution map of wechat friends generated in , You can find : My wechat friends are mainly concentrated in Ningxia and Shaanxi .
06
This article is another attempt of my data analysis , Mainly from gender 、 Head portrait 、 Signature 、 Position has four dimensions , A simple data analysis of wechat friends , The results are mainly presented in the form of charts and word clouds . In a word ,” Data visualization is a means, not an end ”, The important thing is not that we made these pictures here , But the phenomenon reflected in these pictures , What essential enlightenment can we get , I hope this article can inspire you .
【python Study 】
learn Python The partners , Welcome to join the new exchange 【 Junyang 】:1020465983
Discuss programming knowledge together , Become a great God , There are also software installation packages in the group , Practical cases 、 Learning materials