print(sum(range(1,101)))
5050
a=10
def func():
a=20
print(a)
func()
print(a)
執行結果:20,10
a=10
def func():
global a
a=20
print(a)
func()
print(a)
執行結果:20,20
import os
import sys
import time
import datetime
import random
import re
刪除鍵
方法一:使用pop()
方法二:使用del
dic = {
'a': 1, 'b': 2}
dic1 = {
'c': 3, 'd': 4}
dic.pop('b')
print(dic)
del dic1['c']
print(dic1)
合並字典
update:可以實現字典之間的合並
dic = {
'a': 1, 'b': 2}
dic1 = {
'c': 3, 'd': 4}
dic.update(dic1)
print(dic)
執行結果:{‘a’: 1, ‘b’: 2, ‘c’: 3, ‘d’: 4}
進程中多線程執行任務是共享進程中的數據的,在單個cpu時間范圍內,如果某個線程沒有執行完畢,並且沒有連續的cpu時間片段,此時後面的線程也開始執行任務,會出現數據混亂的現象,即線程不安全。解決方法:加鎖,保證某一時間只有一個線程在執行任務。
li=[2,3,4,5,6]
li1=[4,5,6,7,8]
li.extend(li1)
ll=list(set(li))
print(ll)
*args,**kwargs)中的*args,**kwargs是什麼意思*args:接收實際參數中所有沒有匹配到的位置參數**kwargs:接收實際參數中所有沒有匹配到的關鍵字參數
可以將函數作為參數進行傳參的
str
int
float
bool
list
tuple
dict
set
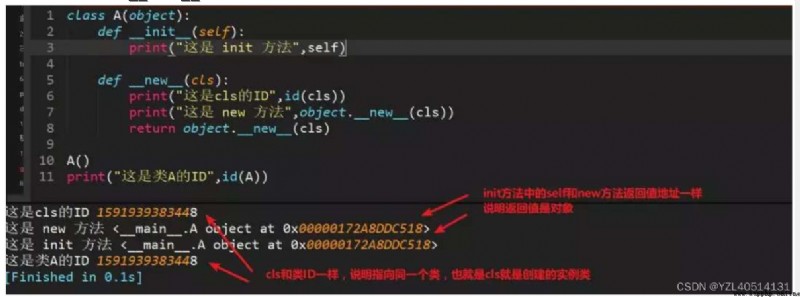
__new__和__init__區別__new__:
a、用於創建對象,將創建的對象給__init__方法
b、至少傳遞一個參數cls,代表當前類
c、必須要有返回值,返回實例化出來的實例
__init__:
a、用於初始化對象,前提必須創建對象完成,對象創建完成後就立刻被默認調用了,可以接收參數。
b、第一個參數位self,就是這個__new__返回的實例;__init__在__new__的基礎上可以完成一些其他初始化的動作
c、__init__不需要返回值
d、如果__new__創建的是當前類的實例,會自動調用__init__函數,通過return語句裡面調用的__new__函數的第一個參數cls來保證是當前類實例;如果是其他類的類名,那麼實際創建返回的是就是其他類的實例,其實就不會調用當前類的__init__函數,也不會調用其他類的__init__函數。
如果使用常規的f.open()寫法,我們需要try、except、finally,做異常判斷,並且文件最終不管遇到什麼情況,都要執行finally f.close()關閉文件。
f=open('./1.txt','w')
try:
f.write("hello")
except:
pass
finally:
f.close()
使用with方法
with open('a.txt') as f:
print(f.read())
執行with這個結構之後。f會自動關閉。相當於自帶了一個finally。
但是with本身並沒有異常捕獲的功能,但是如果發生了運行時異常,它照樣可以關閉文件釋放資源。
方法一:
a=[1,2,3,4,5]
def func1(x):
return x**2
aa=map(func1,a)
new_aa=[i for i in aa if i>10]
print(new_aa)
方法二:
l=[1,2,3,4,5]
ll=list(map(lambda x:x*x,l))
lll=[i for i in ll if i>10]
print(lll)
random.random():隨機生成0到1之間的小數
:.3f:保留3位有效數字
import random
num=random.randint(1,6)
num1=random.random()
print(num)
print(num1)
print('{:.3f}'.format(num1))
a=3
assert(a>1)
print(a) #3
a=3
assert(a>6)
print(a)
斷言失敗
Traceback (most recent call last):
File "D:\log\ceshi_log\face_1.py", line 64, in <module>
assert(a>6)
AssertionError
歷史博文有詳細解答,按值賦值和引用賦值
集合可以對字符串進行去重
s = 'ajldjlajfdljfddd'
s1=list(set(s))
s1.sort()
s2=''.join(s1)
print(s2)
特別注意:不能使用split()方法
s1=s.split()
print(s1)
['ajldjlajfdljfddd']
sum=lambda a,b:a*b
print(sum(3,4))
12
dict1.items():獲取字典中的鍵值,並且鍵和值組合在一起成一個元組
dict1={
"name":"zs","city":"beijing","tel":1243124}
print(dict1.items())
dd=sorted(dict1.items(),key=lambda x:x[0])
print(dd)
new_dict={
}
for item in dd:
new_dict[item[0]]=item[1]
print(new_dict)
統計字符串每個單詞出現的次數:
from collections import Counter
res=Counter(a)
from collections import Counter
a="werwerwegdfgerwewed;wer;wer;6"
from collections import Counter
res=Counter(a)
print(res)
執行結果:
Counter({‘e’: 8, ‘w’: 7, ‘r’: 5, ‘;’: 3, ‘g’: 2, ‘d’: 2, ‘f’: 1, ‘6’: 1})
a=[1,2,3,4,5,6,7,8,9,10]
def func(x):
return x%2==1
newlist=filter(func,a)
newlist=[i for i in newlist]
print(newlist)
執行結果:
[1, 3, 5, 7, 9]
a=[1,2,3,4,5,6,7,8,9,10]
aa=[i for i in a if i%2==1]
print(aa)
執行結果:
[1, 3, 5, 7, 9]
a=(1,)
b=(1)
c=('1')
print(type(a))
print(type(b))
print(type(c))
執行結果:
<class ‘tuple’>
<class ‘int’>
<class ‘str’>
列表相加:合並列表
extend
a=[1,3,4,5,6]
b=[1,3,56,7,7,5]
c=a+b
a.extend(b)
a.sort()
print(c)
print(a)
l=[[1,2],[3,4],[5,6]]
new_list=[]
for item in l:
for i in item:
new_list.append(i)
print(newlist)
執行結果:
[1, 3, 5, 7, 9]
join():括號裡面的是可迭代對象,x插入可迭代對象中間,形成字符串,結果一致
x = "abc"
y = "def"
z = ["d", "e", "f"]
x_1=x.join(y)
print(x_1)
x_2=x.join(z)
print(x_2)
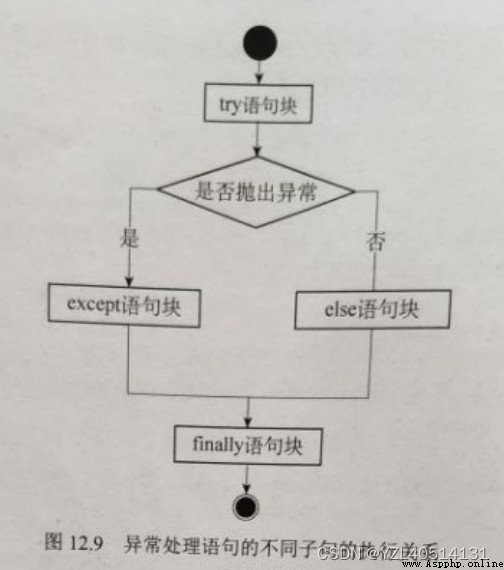
try except else 沒有捕獲到異常,執行else語句
try except finally 不管是否捕獲到異常,都執行finally語句
a=12
b=23
a,b=b,a
print(a)
print(b)
a、zip()函數在運算時,會以一個或多個序列(可迭代對象)作為參數,返回一個元組的列表,同時將這些序列中並排的元素配對。
b、zip()函數可以接收任何類型的序列,同時也可以有2個以上的參數;當傳入的參數不同時,zip能自動以最短序列為准進行截取,獲取元組。
a=[1,2,3]
b=[5,6,7]
res=list(zip(a,b))
print(res)
a=(1,2,3)
b=(5,6,7)
res1=list(zip(a,b))
print(res1)
a=(1,2)
b=(5,6,7)
res2=list(zip(a,b))
print(res2)
執行結果:
[(1, 5), (2, 6), (3, 7)]
[(1, 5), (2, 6), (3, 7)]
[(1, 5), (2, 6)]
print([1,2,3]+[4,5,6])
print([1,2,3]+[3,4,5,6])
[1, 2, 3, 4, 5, 6]
[1, 2, 3, 3, 4, 5, 6]
1、采用生成器,不使用列表和列表推導式,節省大量內存
2、多個if elif else 條件語句,把最有可能發生的條件寫在最前面,這樣可以減少程序判斷的次數,提高效率。
3、循環代碼優化,避免過多重復代碼的執行
4、多進程、多線程、協程
redis:內存型非關系數據庫,數據保存在內存中,速度快
mysql:關系型數據庫,數據保存在磁盤中,檢索的話,會有一定的IO操作,訪問速度相對慢
list1=[2,3,5,4,9,6]
def list_str(list):
num=len(list)
for i in range(num-1):
for j in range(num-1-i):
if list[j]>list[j+1]:
list[j],list[j+1]=list[j+1],list[j]
print(list)
list_str(list1)
[2, 3, 4, 5, 6, 9]
class Create_Object:
obj=None
def __new__(cls, *args, **kwargs):
if obj is None:
cls.obj=super().__new__(cls)
return cls.obj
object=Create_Object
object1=Create_Object
print(id(object))
print(id(object1))
2944204723184
2944204723184
round(3.1415926,2):2表示保留小數點後2位
num='{:.2f}'.format(3.4564564)
print(num)
num1=round(3.4564564,3)
print(num1)
3.46
3.456
fn(“one”,1):直接將鍵值傳給字典
fn(“two”,2):因為字典是可變數據類型,所以指向同一個內存地址,傳入新的參數後,相當於給字典增加值
fn(“three”,3,{}):傳入了一個新字典,所以不再是原先默認的字典
def fn(k,v,div={
}):
div[k]=v
print(div)
fn("one",1)
fn("two",2)
fn("three",3,{
})
{‘one’: 1}
{‘one’: 1, ‘two’: 2}
{‘three’: 3}
a=[("a",1),("b",2),("c",3),("d",4),("e",5)]
A=zip(("a","b","c","d","e"),(1,2,3,4,5))
print(dict(A))
B=dict([["name","zs"],["age",18]])
C=dict([("name","ls"),("age",20)])
print(B)
print(C)
歷史博文詳細講解
__init__:初始化對象__new__:創建對象__str__:返回對實例對象的描述__dict__:如果是類去調用,表示統計類中所有的類屬性和方法;如果是對象去調用,統計的是實例屬性__del__:刪除對象執行的方法__next__:生成器對象去調用,不斷的返回生成器中的數據
d=" sdf fg "
e=d.strip(' ')
print(e)
sort:對原列表進行排序,只能對列表進行排序
f=[1,4,6,3,2,4]
f.sort()
print(f)
[1, 2, 3, 4, 4, 6]
f1=(1,4,6,3,2,4)
f1.sort()
print(f1)
對元組排序報錯
Traceback (most recent call last):
File “D:\log\ceshi_log\face_1.py”, line 249, in
f1.sort()
AttributeError: ‘tuple’ object has no attribute ‘sort’
sorted:對可迭代對象進行排序,排序後產生新的可迭代對象(列表)
f1=(1,4,6,3,2,4)
g=sorted(f1)
print(g,id(g))
print(f1,id(f1))
執行結果
[1, 2, 3, 4, 4, 6] 1646645367488
(1, 4, 6, 3, 2, 4) 1646643170272
f=[1,2,4,6,3,-6,5,7,-1]
f1=sorted(f,key=lambda x:x)
print(f1)
不使用lambda函數對數據進行從小到大的排序
f=[1,2,4,6,3,-6,5,7,-1]
f1=sorted(f)
print(f1)
不使用lambda函數對數據進行從大到小的排序
f=[1,2,4,6,3,-6,5,7,-1]
f1=sorted(f,reverse=True)
print(f1)
foo=[-5,8,0,4,9,-4,-20,-2,8,2,-4]
foo1=sorted(foo,key=lambda x:(x<0,abs(x)))
print(foo1)
[0, 2, 4, 8, 8, 9, -2, -4, -4, -5, -20]
foo=[{
'name':'zs','age':18},
{
'name':'li','age':24},
{
'name':'ww','age':25},]
按照姓名排序
foo1=sorted(foo,key=lambda x:x['name'])
print(foo1)
按照年領排序
foo2=sorted(foo,key=lambda x:x['age'],reverse=True)
print(foo2)
[{‘name’: ‘li’, ‘age’: 24}, {‘name’: ‘ww’, ‘age’: 25}, {‘name’: ‘zs’, ‘age’: 18}]
[{‘name’: ‘ww’, ‘age’: 25}, {‘name’: ‘li’, ‘age’: 24}, {‘name’: ‘zs’, ‘age’: 18}]
foo1=[('zs',19),('ls',18),('ww',20)]
foo2=sorted(foo1,key=lambda x:x[0])
print(foo2)
foo3=sorted(foo1,key=lambda x:x[1])
print(foo3)
[(‘ls’, 18), (‘ww’, 20), (‘zs’, 19)]
[(‘ls’, 18), (‘zs’, 19), (‘ww’, 20)]
foo2=[['zs',19],['ls',18],['ww',20]]
a=sorted(foo2,key=lambda x:x[0])
b=sorted(foo2,key=lambda x:(x[1],x[0])) #數字相同按照字母排
print(a)
print(b)
[[‘ls’, 18], [‘ww’, 20], [‘zs’, 19]]
[[‘ls’, 18], [‘zs’, 19], [‘ww’, 20]]
方法一:
dict1={
"name":"zs","city":"beijing","tel":1243124}
dict1_1=sorted(dict1.items(),key=lambda x:x)
print(dict1_1) # [('city', 'beijing'), ('name', 'zs'), ('tel', 1243124)]
new_dict={
}
for i in dict1_1:
new_dict[i[0]]=i[1]
print(new_dict)
{‘city’: ‘beijing’, ‘name’: ‘zs’, ‘tel’: 1243124}
方法二:
dict1={
"name":"zs","city":"beijing","tel":1243124}
dict1_1=list(zip(dict1.keys(),dict1.values()))
print(dict1_1)
dict1_2=sorted(dict1_1,key=lambda x:x[0])
new_dict={
i[0]:i[1] for i in dict1_2}
print(new_dict)
dt=["name1","zs","city","beijing","tel"]
dt1=sorted(dt,key=lambda x:len(x))
print(dt1)
[‘zs’, ‘tel’, ‘city’, ‘name1’, ‘beijing’]
dt=["name1","zs","city","beijing","tel"]
dt1=sorted(dt,key=lambda x:len(x))
print(dt1)
def func_sum(number):
if number>=1:
sum=number+func_sum(number-1)
else:
sum=0
return sum
print(func_sum(6))
21
def func_sum(number):
if number==1:
return 1
else:
sum=number*func_sum(number-1)
return sum
print(func_sum(7))
5040
方法1:
st=" re rt ty"
st1=st.replace(' ','')
print(st1)
方法2:
st2=st.split(' ')
print(st2) #['', 're', 'rt', 'ty']
st3=''.join(st2)
print(st3)
rertty
rertty