本篇前部分轉載自:
python是單線程的,多線程有意義麼
後半部分自己寫。
經常遇到小伙伴提到python是單線程的,寫代碼的時候用多線程沒有意義,今天與大家分享一下關於python的單線程與多線程、多進程相關理解。
首先 python是單線程的 這句話是不對的。
這裡要提到一個概念:Python的全局解釋器鎖(GIL)
需要明確的一點是GIL並不是Python的特性,它是在實現Python解析器(CPython)時所引入的一個概念。就好比C++是一套語言(語法)標准,但是可以用不同的編譯器來編譯成可執行代碼。有名的編譯器例如GCC,INTEL C++,Visual C++等。Python也一樣,同樣一段代碼可以通過CPython,PyPy,Psyco等不同的Python執行環境來執行。像其中的JPython就沒有GIL。然而因為CPython是大部分環境下默認的Python執行環境。所以在很多人的概念裡CPython就是Python,也就想當然的把GIL歸結為Python語言的缺陷。所以這裡要先明確一點:GIL並不是Python的特性,Python完全可以不依賴於GIL
import threading
import time
def test1():
for i in range(100000000):
a = 100 - i
def test2():
threads = []
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test1)
t3 = threading.Thread(target=test1)
t4 = threading.Thread(target=test1)
threads.append(t1)
threads.append(t2)
threads.append(t3)
threads.append(t4)
threads[0].start()
threads[1].start()
threads[2].start()
threads[3].start()
threads[0].join()
threads[1].join()
threads[2].join()
threads[3].join()
if __name__ == '__main__':
t1 = time.time()
print('進程一啟動時間:', time.time()) # 單線程一次:
test1()
print('單線程一次:', time.time() - t1) # 單線程一次: 3.872997760772705
test1()
print('單線程兩次:', time.time() - t1) # 單線程兩次: 7.738230466842651
test1()
print('單線程三次:', time.time() - t1) # 單線程三次: 11.609771013259888
test1()
print('單線程四次:', time.time() - t1) # 單線程四次: 15.493367433547974
t2 = time.time()
test2()
print('進程1多線程四次:', time.time() - t2) # 多線程四次: 15.55045747756958
print('進程一結束時間:', time.time()) # 進程結束:
這段代碼執行後會發現4個線程同時執行所消耗的時間與一個線程執行消耗的時間是幾乎一樣的,python多線程在提高效率這塊確實沒用。因為上邊說了,GIL的存在,與單線程處理效率是一樣的。
本質是這4個線程交替輪番執行,你執行一會兒,我執行一會兒,他執行一會兒…就是非常和諧的隨機在單核上執行
由於Python的GIL的限制,多線程更適合於I/O密集型應用(I/O釋放了GIL,可以允許更多的並發),而不是計算密集型應用。對於後一種情況而言,為了實現更好地並行性,你需要使用多進程,以便讓CPU的其他內核來執行。
怎麼開啟多進程,以及驗證多進程是否會自動分配到多個CPU上單獨執行呢?
我們改造上訴的代碼如下,並復制4份,分別命名為:
threadTest1.py,threadTest2.py,threadTest3.py,threadTest4.py。
代碼如下:
import threading
import time
def test1():
for i in range(100000000):
a = 100 - i
def test2():
threads = []
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test1)
t3 = threading.Thread(target=test1)
t4 = threading.Thread(target=test1)
threads.append(t1)
threads.append(t2)
threads.append(t3)
threads.append(t4)
threads[0].start()
threads[1].start()
threads[2].start()
threads[3].start()
threads[0].join()
threads[1].join()
threads[2].join()
threads[3].join()
if __name__ == '__main__':
t1 = time.time()
print('進程一啟動時間:', time.time()) # 單線程一次:
test2()
print('進程1多線程四次:', time.time() - t1) # 多線程四次: 15.55045747756958
print('進程一結束時間:', time.time()) # 進程結束:
然後分別快速啟動則4個程序,查看運行時間,可以看到,本人舊電腦cpu四核,當4個程序同時起來時,本人的電腦CPU四核全部被占滿,意思是4個進程分別自動分配到了4核上。所以已經實現並行了。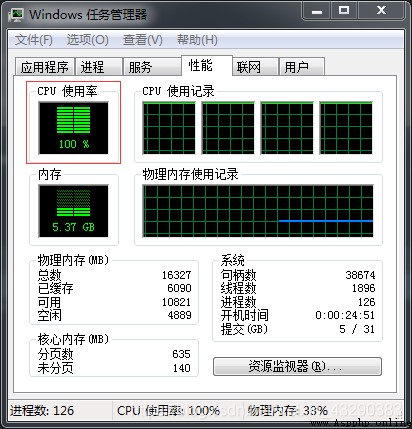
運行結果如下:單個程序運行32.36秒,全部4個程序運行完,71.65秒,除去手工啟動時間延遲6秒,可以近似認為4個程序幾乎同時運行了64秒。也就是說,4個程序的運行時間和單個程序的運行時間的2倍,但是不是4個程序依次執行的4倍。程序整體速度還是有提升的。為啥是兩倍呢?後續解釋。
進程一啟動時間: 1613957587.375495
進程1多線程四次: 64.36468148231506
進程一結束時間: 1613957651.7401764
進程四啟動時間: 1613957595.347951
進程4多線程四次: 63.67764210700989
進程四結束時間: 1613957659.025593
作為對比,我們讓單個程序for循環4次,看看CPU的使用情況。僅需要改動一點。
if __name__ == '__main__':
t1 = time.time()
print('進程一啟動時間:', time.time()) # 單線程一次:
for i in range(4):
test2()
print('進程1多線程運行四次:', time.time() - t1) # 多線程四次
print('進程一結束時間:', time.time()) # 進程結束:
運行CPU情況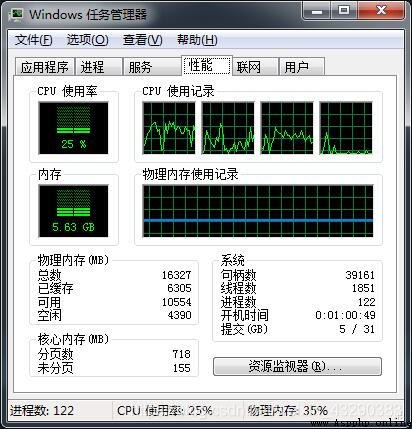
可以看到cpu只用了25%,因此只用了一個CPU核。驗證了我們4個程序相當於4個進程,自動分配到了4核,一個程序分配到一核。
運行結果:
進程一啟動時間: 1613959221.2839491
進程1多線程運行四次: 128.84336948394775
進程一結束時間: 1613959350.1273186
基本上是32秒的4倍。因為單獨運行一個test2(),需要32秒,如下:
進程一啟動時間: 1613959931.0745466
進程1多線程運行四次: 31.243787050247192
進程一結束時間: 1613959962.3183336
符合我們的預期。
所以結論:
對於多IO少密集計算的場景,用多線程沒有問題,對於計算密集的場景,用多進程一樣能充分利用CPU的多核特性並行處理,簡單的處理就是把數據合理隔離,復制成多個程序一起跑就行了。
另外CPU打滿了100%感覺性能反而會下降,我們只運行3個進程看看,單個進程需要多長時間。
進程二啟動時間: 1613960078.199962
進程2多線程四次: 50.52488970756531
進程二結束時間: 1613960128.7248516
cpu情況: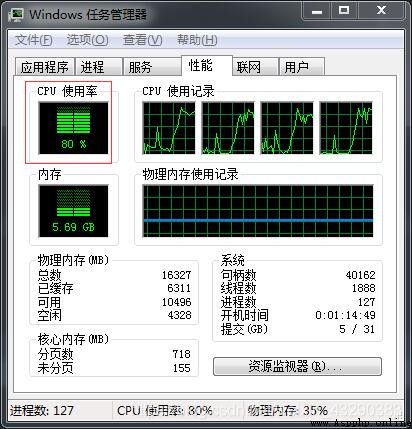
看,單個進程僅需要50.52488970756531,理論上應該還是存在一定的CPU資源的搶奪,因為我的CPU是2核物理核虛擬的4核,運行2個進程呢?
cpu情況: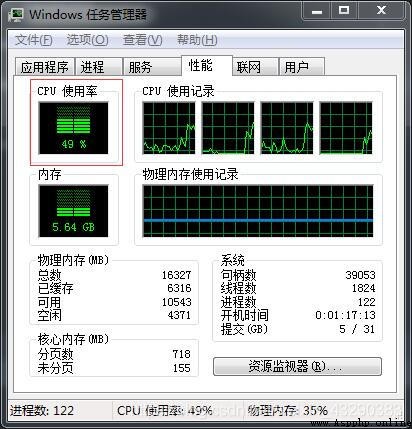
看看結果:
進程一啟動時間: 1613960226.8174622
進程1多線程運行四次: 40.730329751968384
進程一結束時間: 1613960267.547792
和單個進程32秒比較接近了,因此充分利用了2個物理核,CPU爭搶的情況下降。
所以結論:進程數盡量和CPU物理核的個數保持一致,進程的運行效率比較高。