目錄
1.選題背景及意義 5
2.研究現狀分析 5
3.本文算法 6
3.1 算法概述 7
3.2 算法公式、文字描述 8
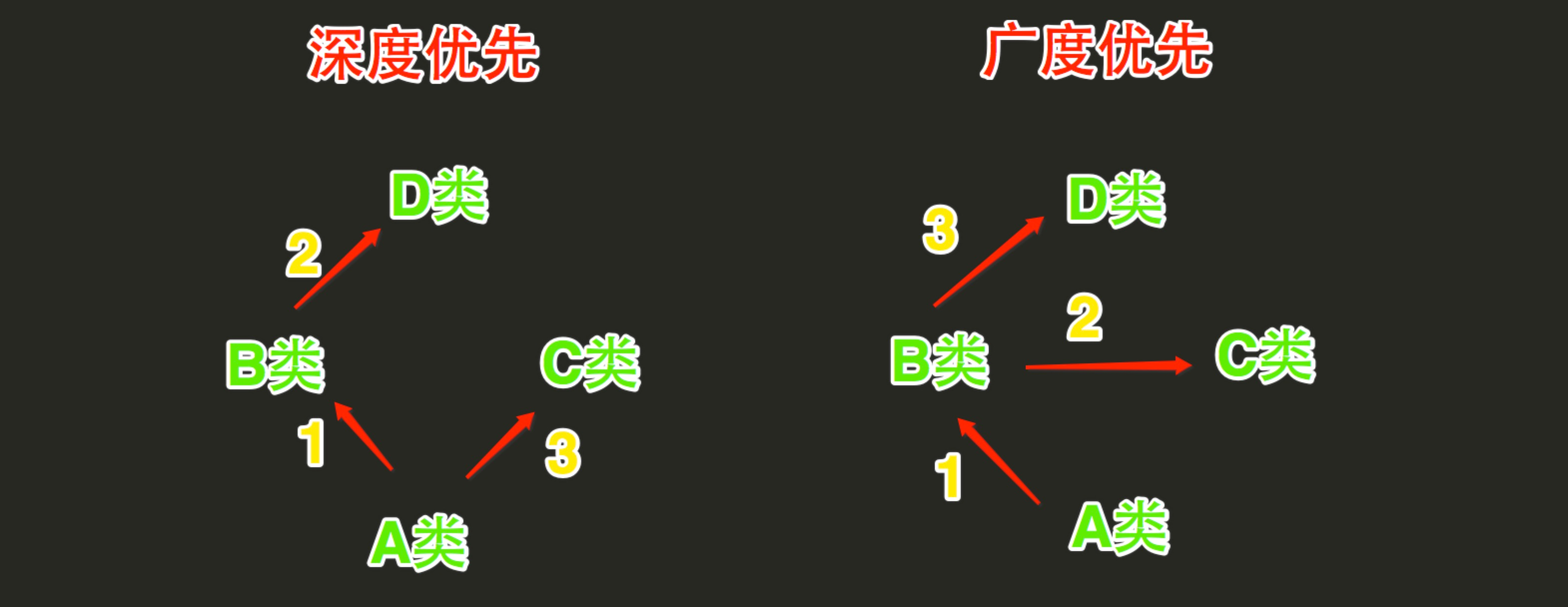
3.3 算法細節 12
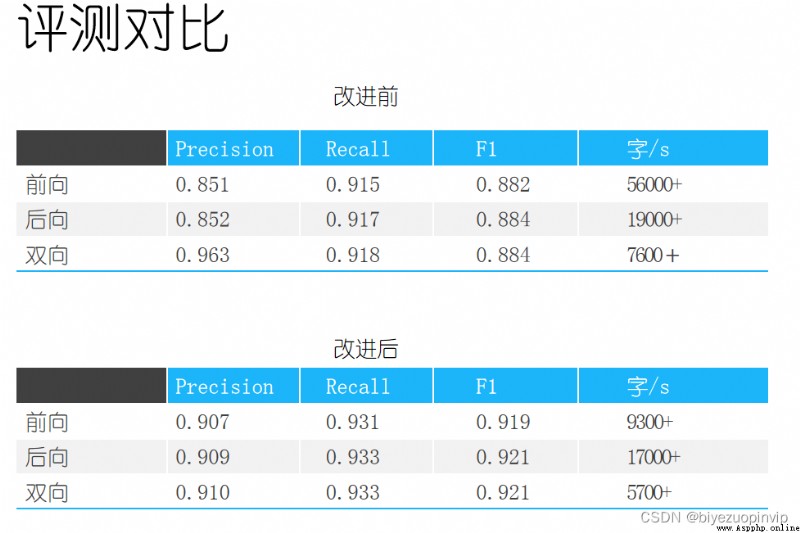
4.實驗結果 14
5.討論和分析 16
5.1結果展示和對比 16
5.2分析 16
6.結論 19
7.學習體會和建議 19
8.小組成員貢獻 19
中文摘要
隨著網絡信息的急劇增長給人們搜索信息帶來一定的困難,搜索引擎的出現及時地解決了這個問題,而在搜索引擎中,其最核心的部分之一便是中文分詞算法,中文分詞算法的分詞效率在一定程度上影響著檢索詞條的速度。在這個互聯網信息快速發展的時代,效率無疑是在商場上競爭的核心要素。
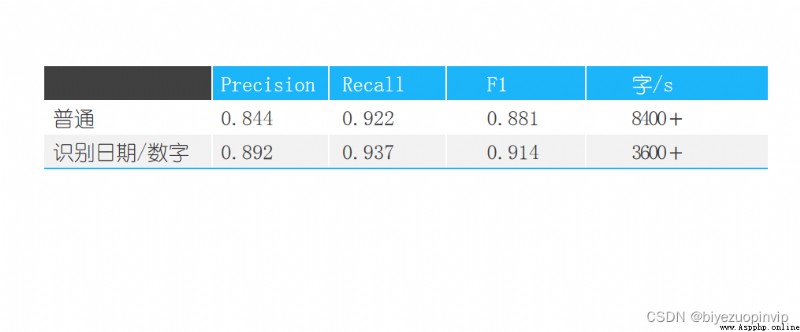
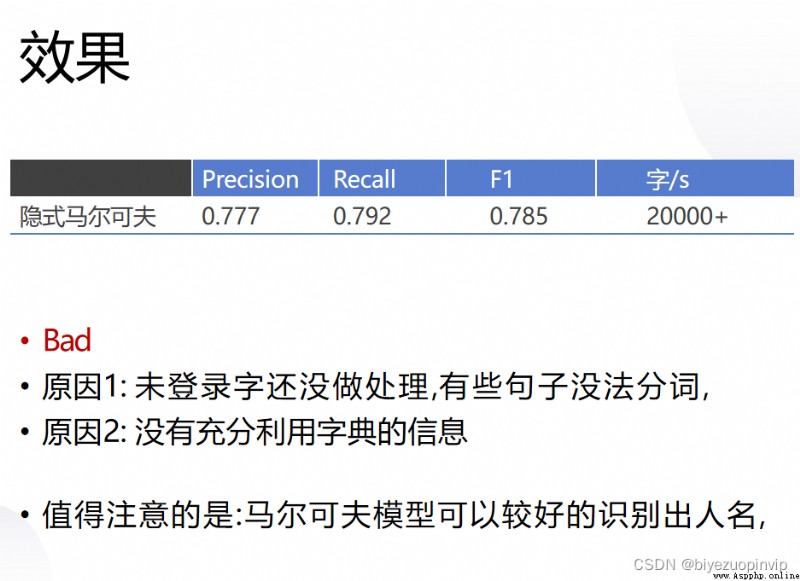
本學期,我們在自然語言處理課上學習了多種中文分詞算法,在本次大作業中,我們選擇了其中的三個算法:最大匹配的三種算法–正向、逆向、雙向;基於統計的Uni-Gram模型;隱馬爾可夫(HMM)統計模型。首先我們將會根據上課所學內容實現這三種模型的代碼,在PKU詞典的正確分詞級集、測試集和訓練集的基礎上,針對他們三種算法的召回率、F1 score、准確率這三項指標進行比較,最終將結果打印出來,選出一個最優的算法作為實驗結果。
關鍵詞:中文分詞算法、比較、准確率、召回率、F1 score
Abstract
With the rapid growth of network information, people have some difficulties in searching information. The emergence of search engine has solved this problem in time. In search engine, one of the most core parts is Chinese word segmentation algorithm. The efficiency of Chinese word segmentation algorithm affects the speed of retrieval entries to a certain extent. In this era of rapid development of Internet information, efficiency is undoubtedly the core element of competition in shopping malls.
This semester, we learned a variety of Chinese word segmentation algorithms in natural language processing class. In this assignment, we selected three of them: three algorithms of maximum matching: forward, backward and bidirectional; uni gram model based on statistics; hidden Markov model (HMM). First of all, we will implement the codes of the three models according to the content learned in class. On the basis of the correct word segmentation level set, test set and training set of PKU dictionary, we will compare the recall rate, F1 score and accuracy rate of the three algorithms. Finally, we will print out the results and select an optimal algorithm as the experimental result.
Key word:Chinese word segmentation algorithm, Comparison, Accuracy, Recall rate, F1 score
1.選題背景及意義
存在中文分詞技術,是由於中文在基本文法上有其特殊性,具體表現在:
1.與英文為代表的拉丁語系語言相比,英文以空格作為天然的分隔符,而中文由於繼承自古代漢語的傳統,詞語之間沒有分隔。古代漢語中除了連綿詞和人名地名等,詞通常就是單個漢字,所以當時沒有分詞書寫的必要。而現代漢語中雙字或多字詞居多,一個字不再等同於一個詞。
2.在中文裡,“詞”和“詞組”邊界模糊
現代漢語的基本表達單元雖然為“詞”,且以雙字或者多字詞居多,但由於人們認識水平的不同,對詞和短語的邊界很難去區分。
例如:“對隨地吐痰者給予處罰”,“隨地吐痰者”本身是一個詞還是一個短語,不同的人會有不同的標准,同樣的“海上”“酒廠”等等,即使是同一個人也可能做出不同判斷,如果漢語真的要分詞書寫,必然會出現混亂,難度很大。
中文分詞的方法其實不局限於中文應用,也被應用到英文處理,如手寫識別,單詞之間的空格就不很清楚,中文分詞方法可以幫助判別英文單詞的邊界。
隨著網絡信息的急劇增長給人們搜索信息帶來一定的困難,中文分詞到底對搜索引擎有多大影響?對於搜索引擎來說,最重要的並不是找到所有結果,因為在上百億的網頁中找到所有結果沒有太多的意義,沒有人能看得完,最重要的是把最相關的結果排在最前面,這也稱為相關度排序。中文分詞的准確與否,常常直接影響到對搜索結果的相關度排序。