之前爬取的網頁都是采用“GET”方法,這次爬取“拉勾網”是采取了“POST”的方法。其中,"GET"和“POST”之間最大的區別就是:"GET"請求時,數據會直接顯示在地址欄;“POST”請求時,數據在數據包(封裝在請求體中,通常是js中),爬取難度相對大點。“拉勾網”恰好是需要“POST”請求才能獲取信息。於是,就寫了這次的程序:
首先,還是從抓包開始,在拉勾網中輸入python,再選中深圳,在network中找到position.Ajax的文件,裡面包含當前頁面的崗位詳細信息、崗位總數等。
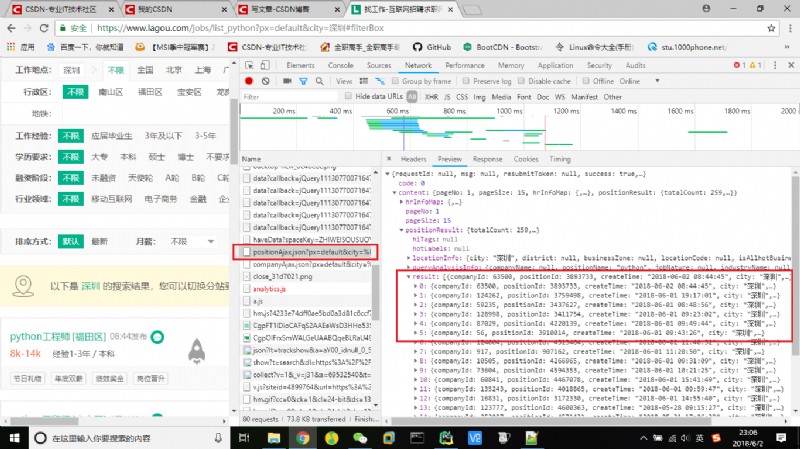
因此,就以這個作為請求網址(URL),再從headers中找到相關請求頭參數以及data數據,接下來就可以發起請求了,采用requests的post方法。
#請求內容(請求網址、請求頭和請求數據)
url = r'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3423.2 Safari/537.36",
"Accept":"application/json, text/javascript, */*; q=0.01",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Host":"www.lagou.com",
"Origin":"https://www.lagou.com",
"Referer":"https://www.lagou.com/jobs/list_python?px=default&city=%E5%B9%BF%E5%B7%9E",
"Cookie":"JSESSIONID=ABAAABAABEEAAJAED90BA4E80FADBE9F613E7A3EC91067E; _ga=GA1.2.1013282376.1527477899; user_trace_token=20180528112458-b2b32f84-6226-11e8-ad57-525400f775ce; LGUID=20180528112458-b2b3338b-6226-11e8-ad57-525400f775ce; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527346927,1527406449,1527423846,1527477899; _gid=GA1.2.1184022975.1527477899; index_location_city=%E5%85%A8%E5%9B%BD; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527487349; LGSID=20180528140228-b38fe5f2-623c-11e8-ad79-525400f775ce; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2FPython%2F%3FlabelWords%3Dlabel; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_Python%3Fpx%3Ddefault%26city%3D%25E5%25B9%25BF%25E5%25B7%259E; TG-TRACK-CODE=index_search; _gat=1; LGRID=20180528141611-9e278316-623e-11e8-ad7c-525400f775ce; SEARCH_ID=42c704951afa48b5944a3dd0f820373d"
}
data = {
"first":True,
"pn":1,
"kd":"python"
}#json數據爬取
def dataJson(url,headers,data):
#發起請求(POST)
req = requests.post(url, data = data, headers = headers)
#返回並解析請求結果(字符串格式)
response = req.text
#轉換成json格式
htmlJson = json.loads(response)
#返回json格式數據
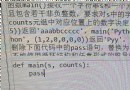
return htmlJson返回的數據轉換成json格式,方便後面的數據篩選,通過分析發現,崗位詳細信息在json數據中顯示,通過篩選出來再返回總的崗位數量以及崗位頁數
#崗位數量和頁數篩選
def positonCount(htmlJson):
# 篩選崗位數量和頁數
totalCount = htmlJson["content"]["positionResult"]["totalCount"]
#每頁顯示15個崗位(向上取整)
page = math.ceil((totalCount)/15)
# 拉勾網最多顯示30頁結果
if page > 30:
return 30
else:
return (totalCount,page)#崗位詳細信息篩選
def selectData(htmlJson):
#篩選出崗位詳細信息
jobList = htmlJson["content"]["positionResult"]["result"]
#創建工作信息列表(外表)
jobinfoList = []
#遍歷,找出數據
for jobDict in jobList:
#創建工作信息列表(內表)
jobinfo = []
# 崗位名稱
jobinfo.append(jobDict['positionName'])
#公司名稱
jobinfo.append(jobDict['companyFullName'])
#公司性質
jobinfo.append(jobDict['financeStage'])
#公司規模
jobinfo.append(jobDict['companySize'])
#行業領域
jobinfo.append(jobDict['industryField'])
# 辦公地點(所處地區)
jobinfo.append(jobDict['district'])
#崗位標簽
positionLables = jobDict['positionLables']
ret1 = ""
for positionLable in positionLables:
ret1 += positionLable + ";"
jobinfo.append(ret1)
#學歷要求
jobinfo.append(jobDict['education'])
#工作經驗
jobinfo.append(jobDict['workYear'])
#工資
jobinfo.append(jobDict['salary'])
#待遇
jobinfo.append(jobDict['positionAdvantage'])
#公司福利
companyLabelList = jobDict['companyLabelList']
ret2 = ""
for companyLabel in companyLabelList:
ret2 += companyLabel + ";"
jobinfo.append(ret2)
#崗位類型
jobinfo.append(jobDict['firstType'])
#發布時間
jobinfo.append(jobDict['createTime'])
#添加都崗位信息列表
jobinfoList.append(jobinfo)
#間隔時間為30s,防止訪問過於頻繁
time.sleep(30)
return jobinfoList
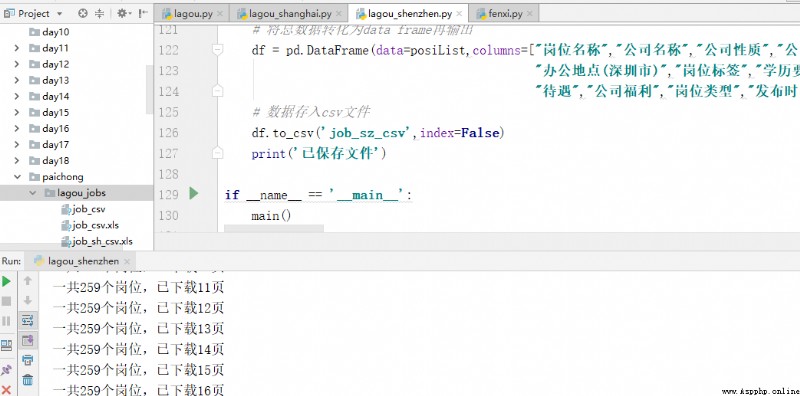
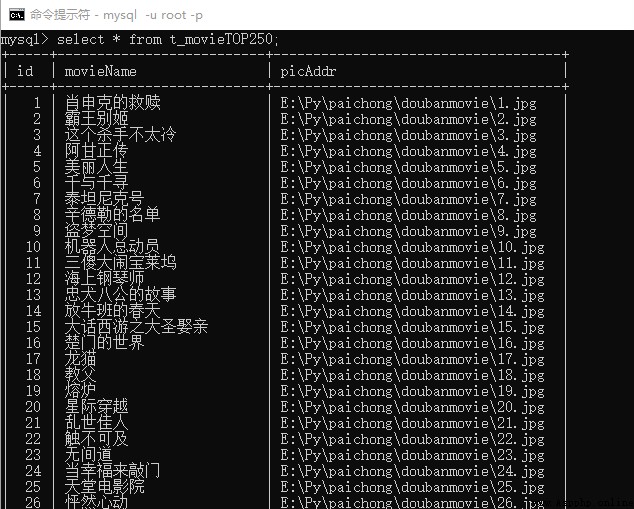
結果如下:
以上就是我的分享,如果有什麼不足之處請指出,多交流,謝謝!
想獲取更多數據或定制爬蟲的請私信我