1、django和scrapy如何結合
2、通過django啟動scrapy爬蟲
此文僅介紹Django和scrapy的簡單實現,適合想要快速上手的朋友。
Django項目可以用命令創建,也可以用pycharm手動創建。此文用pycharm手動創建。
1、使用pycharm創建Django項目:菜單欄File-->New project-->Django-->填寫項目名稱pro,app名稱為app01-->create.
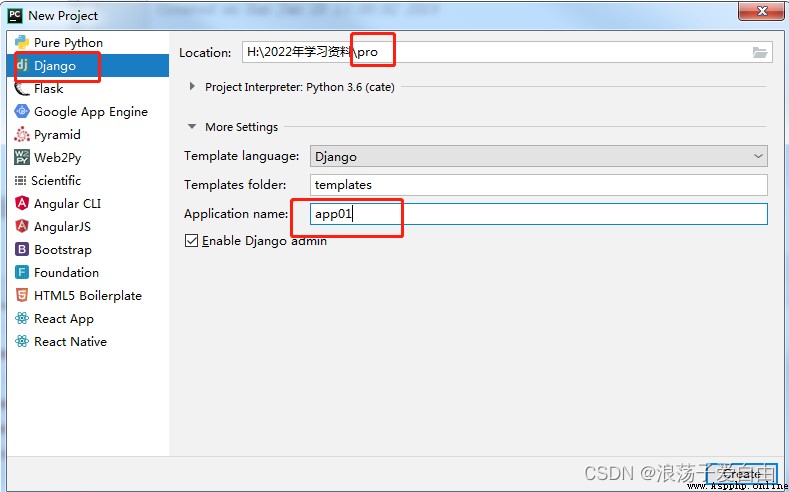
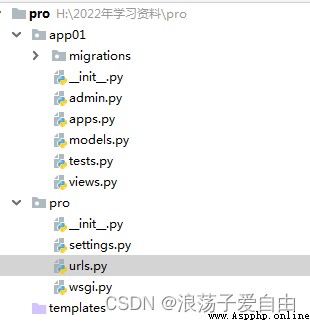
此時項目的目錄結構為如下,app01為項目pro的子應用。
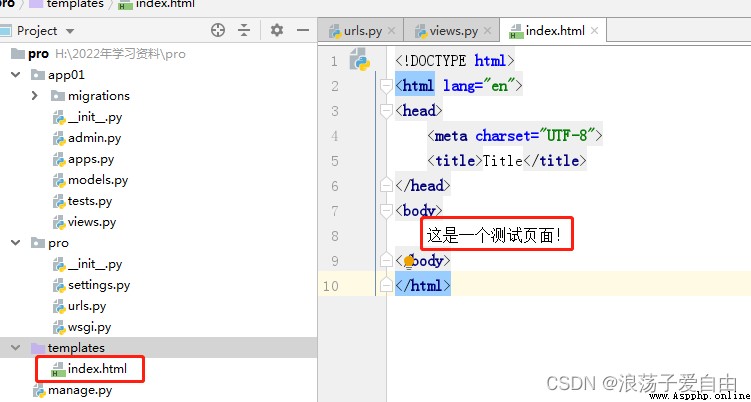
2、創建首頁,首頁內容為"這是一個測試頁面"。
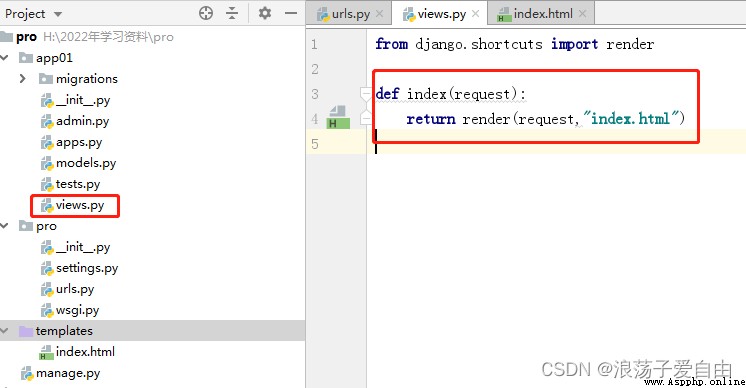
3、運行程序,在浏覽器中輸入http://127.0.0.1:8000/index/。出現【這是一個測試頁面!】則成功。
demo下載:單獨使用django框架創建web項目-Webpack文檔類資源-CSDN下載單獨使用django框架創建web項目更多下載資源、學習資料請訪問CSDN下載頻道. https://download.csdn.net/download/weixin_56516468/85745510
https://download.csdn.net/download/weixin_56516468/85745510
一、准備工作
scrapy安裝:確保已經安裝了scrapy,如未安裝,則打開cmd,輸入pip install scrapy.

常用命令:
scrapy startproject 項目名 # 創建scrapy項目
scrapy genspider 爬蟲名 域名
scrapy crawl 爬蟲名任務描述:
1、爬取鳳凰網,網址是:http://app.finance.ifeng.com/list/stock.php?t=ha,爬取此網頁中滬市A股的代碼、名稱、最新價等信息。
2、將文件保存在H:\2022年學習資料中。
3、項目名為ifengNews
二、實現步驟
1、使用cmd進入要創建項目的目錄【2022學習資料】,使用命令【scrapy startproject ifengNews】創建scrapy項目。
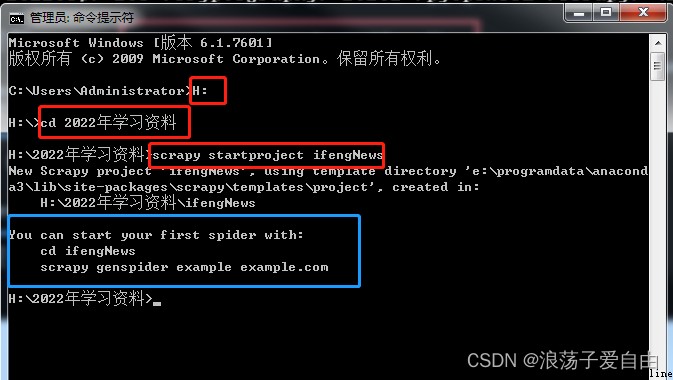
效果:出現【藍框】內容,【ifengNews】項目已經創建成功。
2、使用pycharm打開文件夾【ifengNews】。文件目錄如下:
items.py:定義爬蟲程序的數據模型
middlewares.py:定義數據模型中的中間件
pipelines.py:管道文件,負責對爬蟲返回數據的處理
settings.py:爬蟲程序設置,主要是一些優先級設置(將ROBOTSTXT_OBEY=True 改為 False,這行代碼表示是否遵循爬蟲協議,如果是Ture的可能有些內容無法爬取)
scrapy.cfg:內容為scrapy的基礎配置
spiders目錄:放置spider代碼的目錄
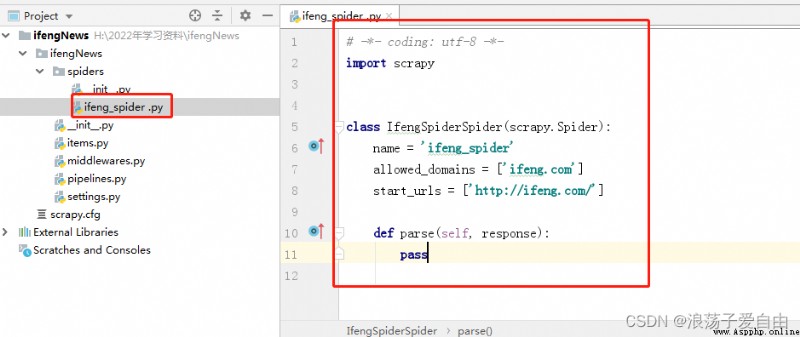
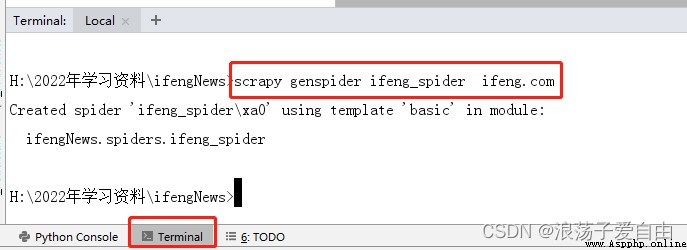
3、在pycharm終端中輸入【scrapy genspider ifeng_spider ifeng.com】 其中:ifeng_spider 是文件名,可以自定義,但是不能與項目名一樣;ifeng.com為域名。
效果:spiders文件夾下創建一個ifeng_spider.py文件,爬蟲代碼都寫在此文件的def parse中。
3.1此步驟也可在cmd中完成。

4、修改setting
第一個是不遵循機器人協議
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # 是否遵循機器人協議,默認是true,需要改為false,否則很多東西爬不了第二個是請求頭,添加一個User-Agent
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie':'adb_isBlock=0; userid=1652710683278_ihrfq92084; prov=cn0731; city=0732; weather_city=hn_xt; region_ip=110.53.149.x; region_ver=1.2; wxIsclose=false; ifengRotator_iis3=6; ifengWindowCookieName_919=1'
# 默認是注釋的,這個東西非常重要,如果不寫很容易被判斷為電腦,簡單點洗一個Mozilla/5.0即可
}第三個是打開一個管道
# ITEM_PIPELINES:項目管道,300為優先級,越低越爬取的優先度越高
ITEM_PIPELINES = {
'ifengNews.pipelines.IfengnewsPipeline': 300,
# 'subeiNews.pipelines.SubeinewsMysqlPipeline': 200, # 存數據的管道
}5、頁面爬取。首先在ifeng_spider.py中寫自己的爬蟲文件:
import scrapy
from ifengNews.items import IfengnewsItem
class IfengSpiderSpider(scrapy.Spider):
name = 'ifeng_spider'
allowed_domains = ['ifeng.com']
start_urls = ['http://app.finance.ifeng.com/list/stock.php?t=ha'] # 爬取地址
def parse(self, response):
# 爬取股票具體的信息
for con in response.xpath('//*[@class="tab01"]/table/tr'):
items = IfengnewsItem()
flag = con.xpath('./td[3]//text()').get() # 最新價
if flag:
items['title'] = response.xpath('//div[@class="block"]/h1/text()').get()
items['code'] = con.xpath('./td[1]//text()').get() # 代碼
items['name'] = con.xpath('./td[2]//text()').get() # 名稱
items['latest_price'] = con.xpath('./td[3]//text()').get() # 最新價
items['quote_change'] = con.xpath('./td[4]//text()').get() # 漲跌幅
items['quote_num'] = con.xpath('./td[5]//text()').get() # 漲跌額
items['volume'] = con.xpath('./td[6]//text()').get() # 成交量
items['turnover'] = con.xpath('./td[7]//text()').get() # 成交額
items['open_today'] = con.xpath('./td[8]//text()').get() # 今開盤
items['closed_yesterday'] = con.xpath('./td[9]//text()').get() # 昨收盤
items['lowest_price'] = con.xpath('./td[10]//text()').get() # 最低價
items['highest_price'] = con.xpath('./td[11]//text()').get() # 最高價
print(items['title'], items['name'])
yield items
打開items.py,更改items.py用於存儲數據:
import scrapy
class IfengnewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
latest_price = scrapy.Field()
quote_change = scrapy.Field()
quote_num = scrapy.Field()
volume = scrapy.Field()
turnover = scrapy.Field()
open_today = scrapy.Field()
closed_yesterday = scrapy.Field()
lowest_price = scrapy.Field()
highest_price = scrapy.Field()
如要實現二級頁面、翻頁等操作,需自行學習。
6、運行爬蟲:在終端中輸入【scrapy crawl ifeng_spider】.
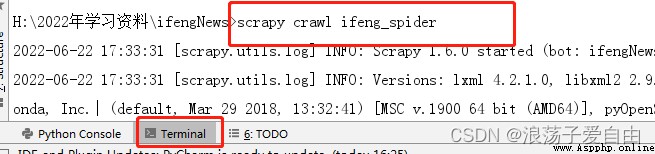
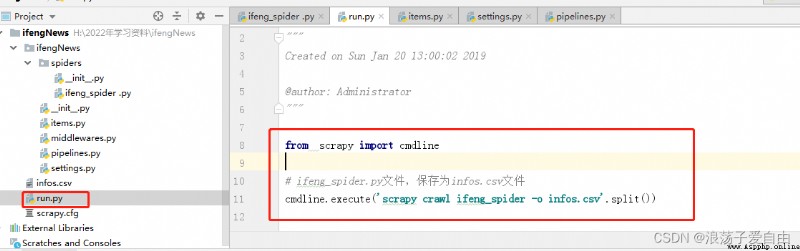
6.1 也可以寫一個run.py文件來運行程序,將數據存儲在infos.csv中。
demo下載:單獨使用scrapy實現簡單爬蟲-Python文檔類資源-CSDN下載單獨使用scrapy實現簡單爬蟲更多下載資源、學習資料請訪問CSDN下載頻道.https://download.csdn.net/download/weixin_56516468/85745577
任務描述:將Django和scrapy結合,實現通過Django控制scrapy的運行,並將爬取的數據存入數據庫。
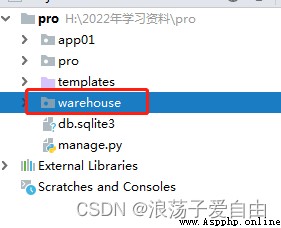
1、在Django項目的根目錄中創建一個子應用warehouse,單獨存放scrapy的數據庫等信息。使用命令行創建app,在終端輸入執行命令:python manage.py startapp warehouse.

此時的目錄結構:
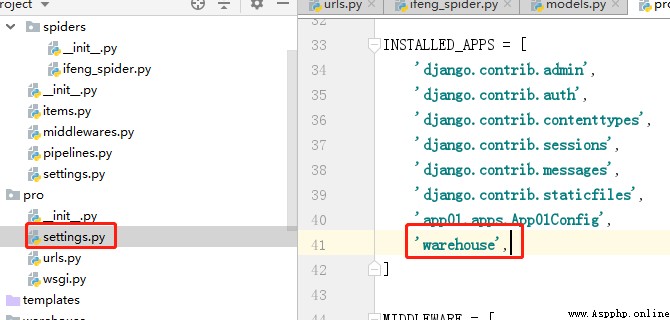
並在pro-settings.py中注冊warehouse這個應用,如下圖。
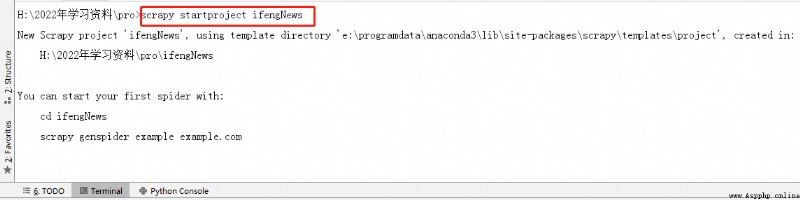
2、在Django項目中創建scrapy項目,並修改項目的setting.py,與任務二中的步驟4一致.

並調整目錄結構,與下圖一致:
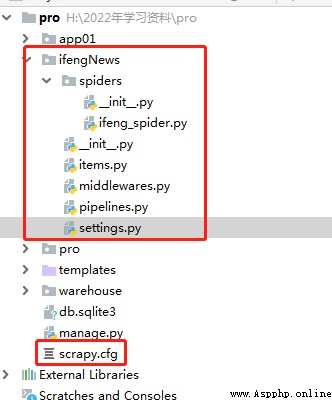
3、在scrapy的setting.py中加入以下代碼:
import os
import sys
import django
sys.path.append(os.path.dirname(os.path.abspath('.')))
os.environ['DJANGO_SETTINGS_MODULE'] = 'pro.settings' # 項目名.settings
django.setup()4、warehouse下的model.py中創建數據庫,用來存儲爬到的數據。並在終端執行命令python manage.py makemigrations和 python manage.py migrate,生成數據庫表。
from django.db import models
class StockInfo(models.Model):
"""
股票信息
"""
title = models.TextField(verbose_name="股票類型" )
code = models.TextField(verbose_name="代碼" )
name = models.TextField(verbose_name="名稱" )
latest_price = models.TextField(verbose_name="最新價" )
quote_change = models.TextField(verbose_name="漲跌幅" )
quote_num = models.TextField(verbose_name="漲跌額" )
volume = models.TextField(verbose_name="成交量" )
turnover = models.TextField(verbose_name="成交額" )
open_today = models.TextField(verbose_name="今開盤" )
closed_yesterday = models.TextField(verbose_name="昨收盤" )
lowest_price = models.TextField(verbose_name="最低價" )
highest_price = models.TextField(verbose_name="最高價" )
5、修改pipelines.py 、 items.py 、 ifeng_spider.py。
ifeng_spider.py:
import scrapy
from ifengNews.items import IfengnewsItem
class IfengSpiderSpider(scrapy.Spider):
name = 'ifeng_spider'
allowed_domains = ['ifeng.com']
start_urls = ['http://app.finance.ifeng.com/list/stock.php?t=ha']
def parse(self, response):
# 爬取股票具體的信息
for con in response.xpath('//*[@class="tab01"]/table/tr'):
items = IfengnewsItem()
flag = con.xpath('./td[3]//text()').get() # 最新價
if flag:
items['title'] = response.xpath('//div[@class="block"]/h1/text()').get()
items['code'] = con.xpath('./td[1]//text()').get() # 代碼
items['name'] = con.xpath('./td[2]//text()').get() # 名稱
items['latest_price'] = con.xpath('./td[3]//text()').get() # 最新價
items['quote_change'] = con.xpath('./td[4]//text()').get() # 漲跌幅
items['quote_num'] = con.xpath('./td[5]//text()').get() # 漲跌額
items['volume'] = con.xpath('./td[6]//text()').get() # 成交量
items['turnover'] = con.xpath('./td[7]//text()').get() # 成交額
items['open_today'] = con.xpath('./td[8]//text()').get() # 今開盤
items['closed_yesterday'] = con.xpath('./td[9]//text()').get() # 昨收盤
items['lowest_price'] = con.xpath('./td[10]//text()').get() # 最低價
items['highest_price'] = con.xpath('./td[11]//text()').get() # 最高價
print(items['title'], items['name'])
yield itemspipelines.py:
class IfengnewsPipeline(object):
def process_item(self, item, spider):
print('打開了數據庫')
item.save()
print('關閉了數據庫')
return itemitems.py中, 導入DjangoItem,與數據庫進行連接。
from warehouse.models import StockInfo
from scrapy_djangoitem import DjangoItem
class IfengnewsItem(DjangoItem):
django_model = StockInfo如下圖安裝scrapy_djangoitem: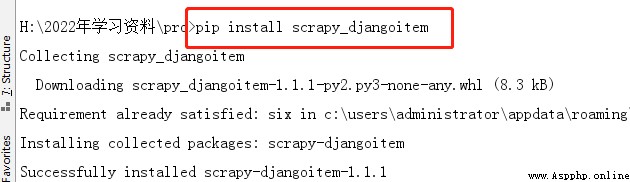 5、
5、
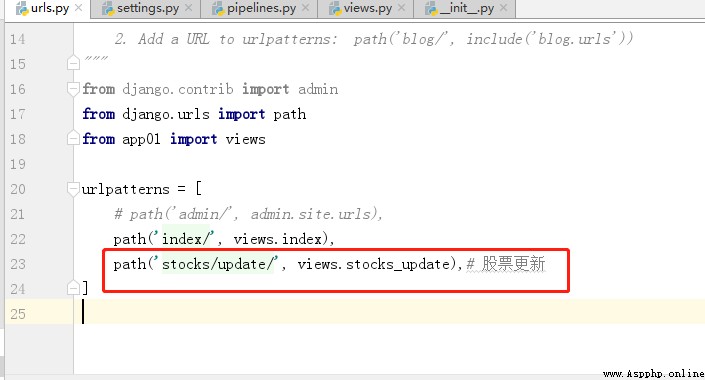
6、修改url.py 、views.py
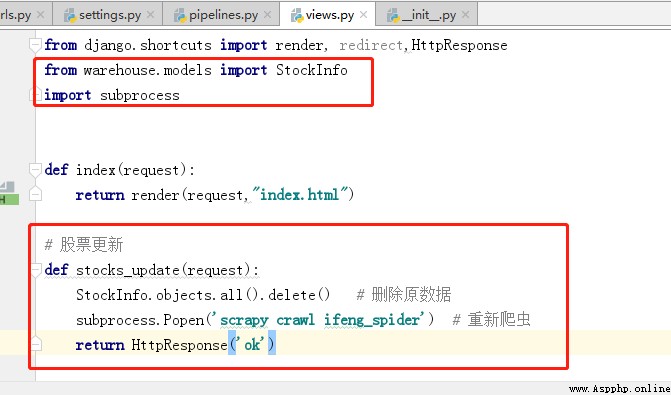
7、 運行程序,在浏覽器中輸入http://127.0.0.1:8000/stocks/update/.頁面返回ok,則可以在數據庫中查看到爬取的數據。
demo下載:
django+scrapy結合-Python文檔類資源-CSDN下載將Django和scrapy結合,實現通過Django控制scrapy的運行,並將爬取的數據存入數據更多下載資源、學習資料請訪問CSDN下載頻道.https://download.csdn.net/download/weixin_56516468/85750917