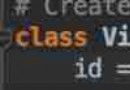
import scrapyclass ThreedmSpider(scrapy.Spider): name = 'threedm' # allowed_domains = ['www.3xxxdm.com'] start_urls = ['https://www.3dmgame.com/bagua_62_1/'] # # 生成一個通用URL模板 # url = "https://www.3dmgame.com/bagua_62_%d/" # page_num = 2 def parse(self, response): li_list = response.xpath("/html/body/div[3]/div[2]/div[2]/ul") for li in li_list: text = li.xpath("./li/a/div[2]/text()").extract_first() print(text) detail_url = li.xpath("./li/a/@href").extract_first() # for detail in detail_url: yield scrapy.Request(url=detail_url, callback=self.parse_detail) # pass # if self.page_num <= 2: # new_url = format(self.url%self.page_num) # self.page_num += 1 # # 手動請求發送,callback回調函數專門用於數據解析 # yield scrapy.Request(url=new_url, callback=self.parse) def parse_detail(self, response): detail = response.xpath("/html/body/div[2]/div[2]/div[3]//text()").extract() detail = ''.join(detail).strip() print(detail)(venv) PS C:\Users\Administrator\Desktop\douban\threedmPro> scrapy crawl threedm
周星馳《食神》取景地珍寶海鮮舫 正式告別香港
周星馳電影《食神》取景地——珍寶海鮮舫,正式告別香港,轉移至東南亞。