During model training , Usually people will focus on model acceleration and improvement GPU Usage rate , But sometimes our time-consuming bottleneck is reading data ,gpu Processing too fast , Instead, cpu Hey, the data can't keep up . Of course, the framework will also provide some data reading acceleration schemes , such as tensorflow Of tf.data.TFRecordDataset,pytorch Of DataLoader Use num_workers Multi thread scheme is adopted in the parameter , There is also some code that makes all the data into a binary file and reads it into memory , Then quickly read data from memory , However, this scheme cannot handle big data projects .
tensorflow Of record Mr. Cheng is also needed record File format and then read ,pytorch Of DataLoader Set up num_workers Especially when windows Some versions of are set to non 0 There will be some problems , This article introduces the use of python A scheme of multithreading to process data , Then combine pytorch Of Dataset and DataLoader get data , For your reference .
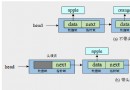
Create a buffer class , Two locks are required to read and write data
import threading
import random
class Buffer:
def __init__(self, size):
self.size = size
self.buffer = []
self.lock = threading.Lock()
self.has_data = threading.Condition(self.lock)
self.has_pos = threading.Condition(self.lock)
def get_size(self):
return self.size
def get(self):
with self.has_data:
while len(self.buffer) == 0:
self.has_data.wait()
result = self.buffer[0]
# print("get buffer size", len(self.buffer))
del self.buffer[0]
self.has_pos.notify_all()
return result
def put(self, data):
with self.has_pos:
while len(self.buffer) >= self.size:
self.has_pos.wait()
self.buffer.append(data)
self.has_data.notify_all()
# test
def get():
while True:
get_data = buffer.get()
# test
def put():
while True:
data = random.randint(0, 9)
buffer.put(a)buffer Class reference :https://cloud.tencent.com/developer/article/1724559
Generate a DataReader Create multithreaded write data , And single thread data reading . The following is the key code of multithreading
class DataReader: def __init__(self, max_buffer_size=5000): self.audio_files = files_to_list(training_files) random.shuffle(self.audio_files) self.buffer = Buffer(max_buffer_size) # Consumption data def comsume(self): while True: result = self.buffer.get() # The production data def produce(self): while True: global index index += 1 if index >= len(self.audio_files)-1: index = 0 start = time.time() file = self.audio_files[index] audio = load_wav(file) end = time.time() self.buffer.put(audio) def run_produce(self, thread_num=16): # Multithreaded production for _ in range(thread_num): th = threading.Thread(target=self.produce) th.start() def get_item(self, index): result = self.buffer.get() return result
Let's use a Dataset To use DataReader get data
class AudioDataset(torch.utils.data.Dataset):
def __init__(self):
self.data_reader = DataReader()
self.data_reader.run_produce()
def __getitem__(self, index):
# from buffer Get a data from
start = time.time()
audio = self.data_reader.get_item(index)
# Data processing
...
audio = torch.from_numpy(audio).float()
end = time.time()
# print("get item time cost", (end - start) * 1000, audio.shape)
return audio.unsqueeze(0)
def __len__(self):
return len(self.audio_files)In the end, it can be passed DataLoader from DataSet In the loop to get batch Data input to the model for training
dataset = AudioDataset() dataloader = torch.utils.data.DataLoader( dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=pin_memory, )