分享一些用Python處理yaml和嵌套數據結構的的一些技巧,首先從修改yaml格式文件的問題出發,演變出了各個解決辦法,又從最後的解決辦法中引申出了普適性更強的嵌套數據結構的定位方法。
保留注釋修改yaml文件
定位嵌套數據結構
定位嵌套數據結構2
保留注釋修改yaml文件yaml比之json文件的其中一個區別就是可以注釋,這些注釋有時候是很重要的內容,就像代碼中的注釋一樣,如果是手動編輯自然是沒有問題的,那麼如何在保留注釋的情況下用代碼修改yaml文件呢?
假設我們要修改的yaml文件如下:
# 主要維護人name: zhangsan# 各集群運維人員cluster1: node1: tomcat: user11cluster2: node1: tomcat: user21不保留注釋為了演示處理yaml的各個方法,這裡把不保留注釋的方法也納入到本文了。
def ignore_comment(): data = yaml.load(text, Loader=yaml.Loader) data["name"] = "wangwu" print(yaml.dump(data))輸出如下:
cluster1:
node1:
tomcat: user11
cluster2:
node1:
tomcat: user21
name: wangwu
很顯然,這不是我們要的結果, 那麼就淘汰這個方法吧。
此方法只適用於不需要保留注釋的修改。
正則表達式既然load, dump方法會丟棄注釋,那麼用正則表達式不就可以了麼,處理文本一定有正則表達式一席之地的。
假設還是將name: zhangsan改成name: wangwu。
def regex1(): pattern = "name:\s+\w+" pat = re.compile(pattern=pattern) # 首先匹配到對應的字符串 sub_text = pat.findall(text)[0] # 根據這個字符串找到在文本的位置 start_index = text.index(sub_text) # 根據起始位置計算結束位置 end_index = start_index + len(sub_text) print(start_index, end_index, text[start_index:end_index]) # 將根據索引替換內容 replace_text = "name: wangwu" new_text = text[:start_index] + replace_text + text[end_index:] print("="*10) print(new_text)輸出如下:
8 22 name: zhangsan
==========
# 主要維護人
name: wangwu
# 各集群運維人員
cluster1:
node1:
tomcat: user11
cluster2:
node1:
tomcat: user21
看起來不錯,好像能夠滿足需求,但是這裡有一個問題就是,假設修改是cluster2.node1.tomcat的值呢?
因為文本中有兩個tomcat的值,所以只是通過正則表達式不能一擊即中,需要多一些判斷條件,比如首先找到cluster2的起始位置,然後過濾掉小於這個起始位置的索引值,但是如果還有cluster3,cluster4呢?總的來說還 是需要人工的過一遍,然後根據觀察結果來編寫正則表達式,但是這樣太不智能,太不自動了。
此方法適用於比較容器匹配的文本。
語法樹其實整個文本的數據結構大致如下:
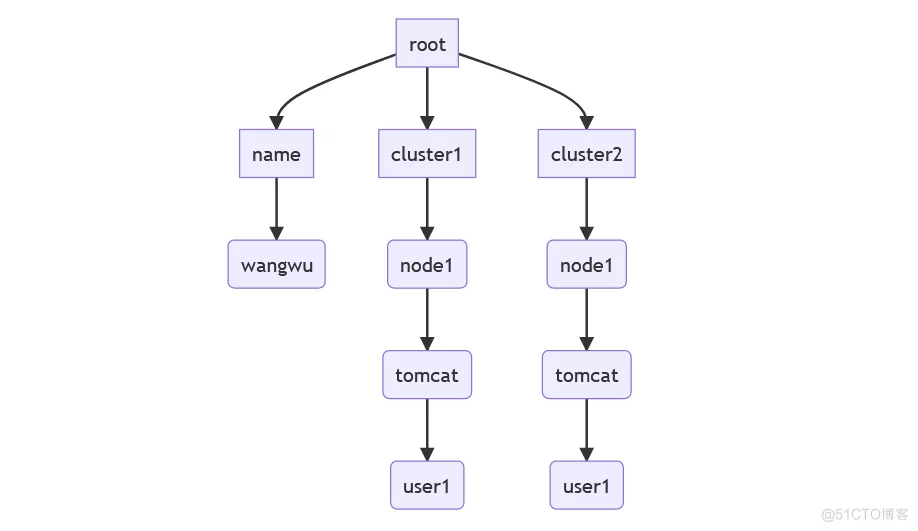
無論是編程語言還是數據文本,如json, yaml, toml都可以得到這樣的語法樹,通過搜索這顆語法樹,我們就能找到對應的鍵值對。
def tree1():
tree = yaml.compose(text)
print(tree)
輸出如下:
MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='name'), ScalarNode(tag='tag:yaml.org,2002:str', value='zhangsan')), (ScalarNode(tag='tag:yaml.org,2002:str', value='cluster1'), MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='node1'), MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='tomcat'), ScalarNode(tag='tag:yaml.org,2002:str', value='user11'))]))])), (ScalarNode(tag='tag:yaml.org,2002:str', value='cluster2'), MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='node1'), MappingNode(tag='tag:yaml.org,2002:map', value=[(ScalarNode(tag='tag:yaml.org,2002:str', value='tomcat'), ScalarNode(tag='tag:yaml.org,2002:str', value='user21'))]))]))])
通過yaml.compose方法我們就能得到一顆節點樹,並且每個節點會包括該節點的文本信息,比如起始,終止的文本索引。
通過觀察我們能找到name: zhangsan的兩個節點, 鍵name是一個ScalarNode節點, 值zhangsan也是一個ScalarNode, 所以我們可以打印一下看看是否和正則表達式的結果一致。
def tree2(): tree = yaml.compose(text) key_name_node = tree.value[0][0] value_name_node = tree.value[0][1] print(key_name_node.start_mark.pointer, value_name_node.end_mark.pointer, key_name_node.value, value_name_node.value)輸出如下:
8 22 name zhangsan
結果與正則表達式一致,所以說明這種方法可行並且准確。
得到了修改文本的索引位置,就可以替換了,這裡就不再演示了。
此方法適合保留注釋的修改,並且定位嵌套結構較之正則表達式要簡單,並且不需要人工介入。
那麼如何定位嵌套結構呢?
定位嵌套數據結構從上一節我們了解到了數據結構可以抽象成一顆語法樹, 那麼利用一些樹的搜索算法就可以定位到目標文本了。
這裡展示一下不包含列表節點的搜索算法。
def find_slice(tree: yaml.MappingNode, keys: List[str]) -> Tuple[Tuple[int, int], Tuple[int, int]]: """ 找到yaml文件中對應鍵值對的索引, 返回一個((key起始索引, key結束索引+1), (value起始索引, value結束索引+1))的元組 暫時只支持鍵值對的尋找. 比如: >>> find_slice("name: zhangsan", ["name"]) ((0, 4), (6, 14)) """ if isinstance(tree, str): tree = yaml.compose(tree, Loader=yaml.Loader) assert isinstance(tree, yaml.MappingNode), "未支持的yaml格式" target_key = keys[0] for node in tree.value: if target_key == node[0].value: key_node, value_node = node if len(keys) == 1: key_pointers = (key_node.start_mark.pointer, key_node.end_mark.pointer) value_pointers = (value_node.start_mark.pointer, value_node.end_mark.pointer) return (key_pointers, value_pointers) return find_slice(node[1], keys[1:]) return ValueError("沒有找到對應的值")算法核心在於遞歸。
這裡的實現並沒有處理列表節點(SequenceNode)。
假設我們要找cluster1.node1.tomcat並將其值改成changed, 代碼如下:
def tree3(): slices = find_slice(text, ["cluster1", "node1", "tomcat"]) value_start_index, value_end_index = slices[1] replace_text = "changed" new_text = text[:value_start_index] + replace_text + text[value_end_index:] print(new_text)輸出如下
# 主要維護人
name: zhangsan# 各集群運維人員
cluster1:
node1:
tomcat: changedcluster2:
node1:
tomcat: user21
上面的算法只能定位key-value類型的數據結構,現在在此優化一下,讓其 支持序列。
def find_slice2(tree: yaml.MappingNode, keys: List[str]) -> Tuple[Tuple[int, int], Tuple[int, int]]: """ 找到yaml文件中對應鍵值對的索引, 返回一個((key起始索引, key結束索引+1), (value起始索引, value結束索引+1))的元組 暫時只支持鍵值對的尋找. 比如: >>> find_slice2("name: zhangsan", ["name"]) ((0, 4), (6, 14)) """ if isinstance(tree, str): tree = yaml.compose(tree, Loader=yaml.Loader) target_key = keys[0] assert isinstance(tree, yaml.MappingNode) or isinstance(tree, yaml.SequenceNode), "未支持的yaml格式" ret_key_node = None ret_value_node = None value_pointers= (-1, -1) if isinstance(tree, yaml.SequenceNode): assert isinstance(target_key, int), "錯誤的數據格式" # 索引可以是負索引, 比如[1,2,3][-1] if len(tree.value) < abs(target_key): raise IndexError("索引值大於列表長度") node = tree.value[target_key] if len(keys) > 1: return find_slice2(tree.value[target_key], keys[1:]) if isinstance(node, yaml.MappingNode): ret_key_node, ret_value_node = node.value[0] else: ret_key_node = node if isinstance(tree, yaml.MappingNode): for node in tree.value: if target_key == node[0].value: key_node, value_node = node if len(keys) > 1: return find_slice2(node[1], keys[1:]) ret_key_node = key_node ret_value_node = value_node if ret_key_node: key_pointers = (ret_key_node.start_mark.pointer, ret_key_node.end_mark.pointer) if ret_value_node: value_pointers = (ret_value_node.start_mark.pointer, ret_value_node.end_mark.pointer) if ret_key_node: return (key_pointers, value_pointers) return ValueError("沒有找到對應的值")假設yaml文件如下:
# 用戶列表users: - user1: wangwu - user2: zhangsan# 集群中間件版本cluster: - name: tomcat version: 9.0.63 - name: nginx version: 1.21.6def tree4(): slices = find_slice2(text2, ["cluster", 1, "version"]) value_start_index, value_end_index = slices[1] replace_text = "1.22.0" new_text = text2[:value_start_index] + replace_text + text2[value_end_index:] print(new_text)輸出如下:
# 用戶列表
users:
- user1: wangwu
- user2: zhangsan# 集群中間件版本
cluster:
- name: tomcat
version: 9.0.63
- name: nginx
version: 1.22.0
結果符合預期。
定位嵌套數據結構2上面介紹了如何定位嵌套的數據結構樹,這一節介紹一下如何定位較深的樹結構(主要指python字典)。
鏈式調用get在獲取api數據的時候因為想要的數據結構比較深,用索引會報錯,那麼就 需要捕獲異常,這樣很麻煩,並且代碼很冗長,比如:
data1 = {"message": "success", "data": {"limit": 0, "offset": 10, "total": 100, "data": ["value1", "value1"]}}data2 = {"message": "success", "data": None}data3 = {"message": "success", "data": {"limit": 0, "offset": 10, "total": 100, "data": None}}上面的數據結構很有可能來自同一個api結構,但是數據結構卻不太一樣。
如果直接用索引,就需要捕獲異常,這樣看起來很煩,那麼可以利用字典的get方法。
ret = data1.get("data", {}).get("data", [])if ret: pass # 做一些操作if data2.get("data"): ret = data2["data"].get("data", [])ret = data3.get("data", {}).get("data", [])通過給定一個預期的數據空對象,讓get可以一致寫下去。
寫一個遞歸的get起始在之前的find_slice方法中,我們就發現遞歸可以比較好的處理這種嵌套的數據結構,我們可以寫一個遞歸處理函數,用來處理很深的數據結構。
假設數據結構如下:
data = {"message": "success", "data": {"data": {"name": "zhangsan", "scores": {"math": {"mid-term": 88, "end-of-term": 90}}}}}我們的目標就是獲取數據中張三期中數學成績: 88
實現的遞歸調用如下:
def super_get(data: Union[dict, list], keys: List[Union[str, int]]): assert isinstance(data, dict) or isinstance(data, list), "只支持字典和列表類型" key = keys[0] if isinstance(data, list) and isinstance(key, int): try: new_data = data[key] except IndexError as exc: raise IndexError("索引值大於列表長度") from exc elif isinstance(data, dict) and isinstance(key, str): new_data = data.get(key) else: raise ValueError(f"數據類型({type(data)})與索引值類型(f{type(key)}不匹配") if len(keys) == 1: return new_data if not isinstance(new_data, dict) and not isinstance(new_data, list): raise ValueError("找不到對應的值") return super_get(new_data, keys[1:])然後執行代碼:
def get2(): data = {"message": "success", "data": {"data": {"zhangsan": {"scores": {"math": {"mid-term": 88, "end-of-term": 90}}}}}} print(super_get(data, ["data", "data", "zhangsan", "scores", "math", "mid-term"])) # 輸出 88 data = {"message": "success", "data": {"data": {"zhangsan": {"scores": {"math": [88, 90]}}}}} print(super_get(data, ["data", "data", "zhangsan", "scores", "math", 0])) # 輸出 88 data = {"message": "success", "data": {"data": {"zhangsan": {"scores": {"math": [88, 90]}}}}} print(super_get(data, ["data", "data", "zhangsan", "scores", "math", -1])) # 輸出 90 第三方庫其實有語法比較強大的庫,比如jq, 但是畢竟多了一個依賴,並且需要一定的學習成本,但是,如果確定自己需要更多的語法,那麼可以去安裝一下第三方庫。
總結如果遇到較深的嵌套,遞歸總能很好的解決,如果實在想不出比較好的算法,那就找個第三方庫吧,調庫嘛,不寒碜。
源碼地址:https://github.com/youerning/blog/tree/master/py_yaml_nested_data
以上就是Python處理yaml和嵌套數據結構技巧示例的詳細內容,更多關於Python處理yaml嵌套數據結構的資料請關注軟件開發網其它相關文章!