可以考慮使用下面的程序來理解此概念:
import multiprocessing
# 具有全局作用域的空列表
result = []
def square_list(mylist):
"""函數對給定列表進行平方運算"""
global result
# 將mylist的方塊附加到全局列表結果
for num in mylist:
result.append(num * num)
# 打印全局列表結果
print("Result(in process p1): {}".format(result))
if __name__ == "__main__":
# 輸入列表
mylist = [1, 2, 3, 4]
# 創建新進程
p1 = multiprocessing.Process(target=square_list, args=(mylist,))
# 開啟進程
p1.start()
# 等待進程完成
p1.join()
# 打印全局結果列表
print("Result(in main program): {}".format(result))
以下是輸出結果
Result(in process p1): [1, 4, 9, 16]
Result(in main program): []
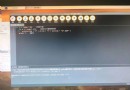
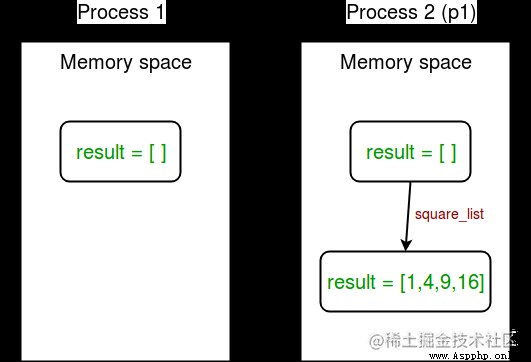
在上面的示例中,我們嘗試在兩個位置打印全局列表結果的內容:
下圖顯示了這個概念:
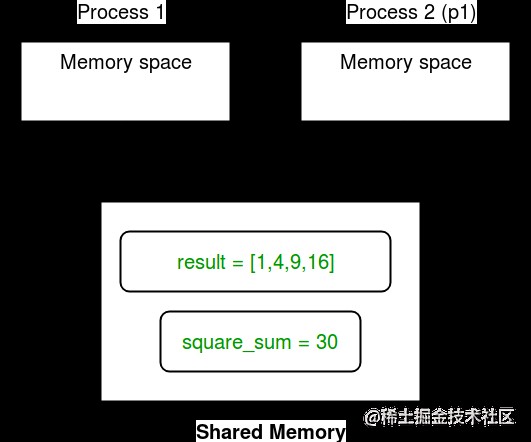
共享內存:多進程模塊提供數組和值對象以在進程之間共享數據。
下面給出的是一個簡單的示例,顯示了使用 Array 和 Value 在進程之間共享數據。
import multiprocessing
def square_list(mylist, result, square_sum):
"""函數對給定列表進行平方運算"""
# 將mylist的方塊附加到結果數組
for idx, num in enumerate(mylist):
result[idx] = num * num
# 平方和值
square_sum.value = sum(result)
# 打印結果數組
print("Result(in process p1): {}".format(result[:]))
# 打印square_sum值
print("Sum of squares(in process p1): {}".format(square_sum.value))
if __name__ == "__main__":
# 輸入列表
mylist = [1, 2, 3, 4]
# 創建int數據類型的數組,其中有4個整數的空格
result = multiprocessing.Array('i', 4)
# 創建int數據類型的值
square_sum = multiprocessing.Value('i')
# 創建新流程
p1 = multiprocessing.Process(target=square_list, args=(mylist, result, square_sum))
# 正在啟動進程
p1.start()
# 等待進程完成
p1.join()
# 打印結果數組
print("Result(in main program): {}".format(result[:]))
# 打印square_sum值
print("Sum of squares(in main program): {}".format(square_sum.value))
運行結果:
Result(in process p1): [1, 4, 9, 16]
Sum of squares(in process p1): 30
Result(in main program): [1, 4, 9, 16]
Sum of squares(in main program): 30
讓我們嘗試逐行理解上面的代碼:
首先,我們創建一個數組結果,如下所示:
result = multiprocessing.Array('i', 4)
同樣,我們創建一個價值square_sum如下所示:
square_sum = multiprocessing.Value('i')
在這裡,我們只需要指定數據類型。該值可以給出一個初始值(例如10),如下所示:
square_sum = multiprocessing.Value('i', 10)
其次,我們在創建 Process 對象時將結果和square_sum作為參數傳遞。
p1 = multiprocessing.Process(target=square_list, args=(mylist, result, square_sum))
通過指定數組元素的索引,為結果數組元素指定一個值。
for idx, num in enumerate(mylist):
result[idx] = num * num
square_sum通過使用其 value 屬性為其賦值:
square_sum.value = sum(result)
為了打印結果數組元素,我們使用 result[:] 來打印完整的數組。
print("Result(in process p1): {}".format(result[:]))
square_sum值簡單地打印為:
print("Sum of squares(in process p1): {}".format(square_sum.value))
下圖描述了進程如何共享數組和值對象:
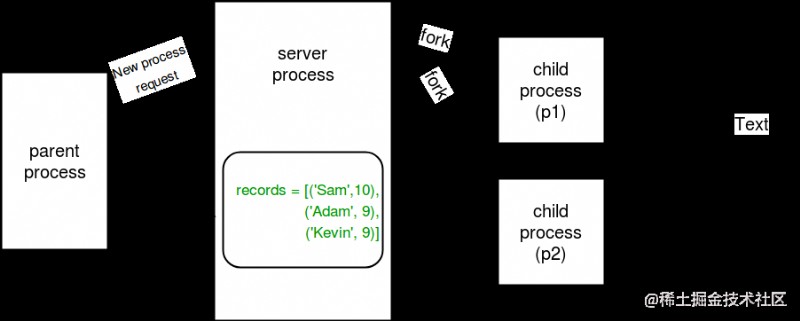
服務器進程 : 每當python程序啟動時,服務器進程也會啟動。從那時起,每當需要新進程時,父進程就會連接到服務器並請求它分叉新進程。
服務器進程可以保存Python對象,並允許其他進程使用代理操作它們。
多處理模塊提供了一個管理器類,用於控制服務器進程。因此,經理提供了一種創建可在不同流程之間共享的數據的方法。
服務器進程管理器比使用共享內存對象更靈活,因為它們可以支持任意對象類型,如列表、字典、隊列、值、數組等。此外,單個管理器可以由網絡上不同計算機上的進程共享。但是,它們比使用共享內存慢。
請考慮下面給出的示例:
import multiprocessing
def print_records(records):
"""用於打印記錄(列表)中的記錄(元組)的函數"""
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
"""向記錄(列表)添加新記錄的函數"""
records.append(record)
print("已添加新記錄!\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
# 在服務器進程內存中創建列表
records = manager.list([('Sam', 10), ('Adam', 9), ('Kevin', 9)])
# 要插入到記錄中的新記錄
new_record = ('Jeff', 8)
# 創建新流程
p1 = multiprocessing.Process(target=insert_record, args=(new_record, records))
p2 = multiprocessing.Process(target=print_records, args=(records,))
# 運行進程p1以插入新記錄
p1.start()
p1.join()
# 運行進程p2以打印記錄
p2.start()
p2.join()
運行輸出結果:
已添加新記錄!
Name: Sam
Score: 10
Name: Adam
Score: 9
Name: Kevin
Score: 9
Name: Jeff
Score: 8
進程已結束,退出代碼為 0
讓我們嘗試理解上面的代碼段:
首先,我們使用以下命令創建一個管理器對象:
with multiprocessing.Manager() as manager:
with 語句塊 下的所有行都在 manager 對象的作用域下。
然後,我們使用以下命令在服務器進程內存中創建一個列表記錄:
records = manager.list([('Sam', 10), ('Adam', 9), ('Kevin',9)])
同樣,您可以將字典創建為 manager.dict 方法。
服務器進程的概念如下圖所示:
有效使用多個流程通常需要它們之間進行一些溝通,以便可以劃分工作並聚合結果。
多處理支持進程之間的兩種類型的通信通道:
隊列: 在進程與多處理之間進行通信的一種簡單方法是使用隊列來回傳遞消息。任何Python對象都可以通過隊列。
注意:多處理。隊列類是隊列的近似克隆 。隊列。
參考下面給出的示例程序:
import multiprocessing
def square_list(mylist, q):
"""函數對給定列表進行平方運算"""
# 將mylist的方塊附加到隊列
for num in mylist:
q.put(num * num)
def print_queue(q):
"""打印隊列元素的函數"""
print("隊列元素:")
while not q.empty():
print(q.get())
print("隊列現在為空!")
if __name__ == "__main__":
# 輸入列表
mylist = [1, 2, 3, 4]
# 創建多進程隊列
q = multiprocessing.Queue()
# 創建新流程
p1 = multiprocessing.Process(target=square_list, args=(mylist, q))
p2 = multiprocessing.Process(target=print_queue, args=(q,))
# 將進程p1運行到列表
p1.start()
p1.join()
# 運行進程p2以獲取隊列元素
p2.start()
p2.join()
運行結果:
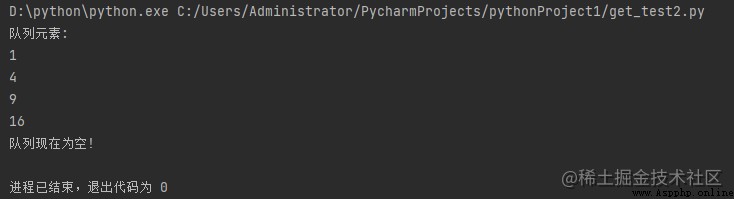
讓我們嘗試一步一步地理解上面的代碼:
首先,我們使用以下命令創建一個多處理隊列:
q = multiprocessing.Queue()
然後,我們通過進程 p1 將空隊列 q 傳遞給square_list函數。使用 put 方法將元素插入到隊列中。
q.put(num * num)
為了打印隊列元素,我們使用 get 方法,直到隊列不為空。
while not q.empty():
print(q.get())
下面給出的是一個簡單的圖表,描述了隊列上的操作:
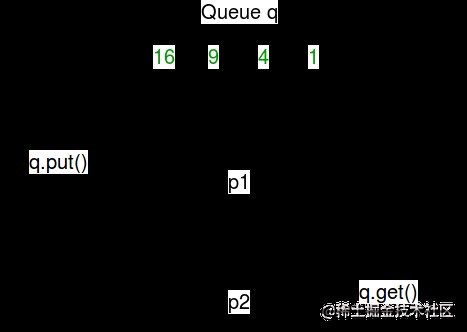
管道: 一個管道只能有兩個端點。因此,當只需要雙向通信時,它優先於隊列。
多處理模塊提供 Pipe() 函數,該函數返回一對由管道連接的連接對象。Pipe() 返回的兩個連接對象表示管道的兩端。每個連接對象都有 send() 和 recv() 方法(以及其他方法)。
考慮下面給出的程序:
import multiprocessing
def sender(conn, msgs):
"""用於將消息發送到管道另一端的函數"""
for msg in msgs:
conn.send(msg)
print("已發送消息: {}".format(msg))
conn.close()
def receiver(conn):
"""用於打印從管道另一端接收的消息的函數"""
while 1:
msg = conn.recv()
if msg == "END":
break
print("收到消息: {}".format(msg))
if __name__ == "__main__":
# 要發送的消息
msgs = ["hello", "hey", "hru?", "END"]
# 創建管道
parent_conn, child_conn = multiprocessing.Pipe()
# 創建新進程
p1 = multiprocessing.Process(target=sender, args=(parent_conn, msgs))
p2 = multiprocessing.Process(target=receiver, args=(child_conn,))
# 正在運行進程
p1.start()
p2.start()
# 等待進程完成
p1.join()
p2.join()
運行結果:
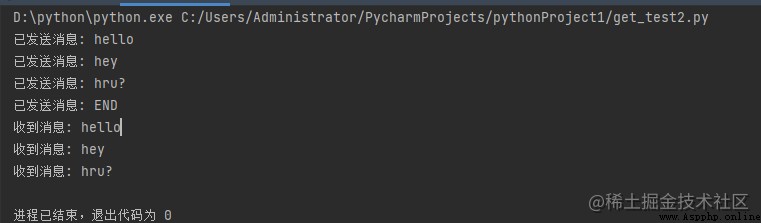
讓我們嘗試理解上面的代碼:
管道是使用以下方法創建的:
parent_conn, child_conn = multiprocessing.Pipe()
該函數為管道的兩端返回了兩個連接對象。
消息使用 send 方法從管道的一端發送到另一端。
conn.send(msg)
為了在管道的一端接收任何消息,我們使用 recv 方法。
msg = conn.recv()
在上面的程序中,我們將消息列表從一端發送到另一端。在另一端,我們閱讀消息,直到收到“END”消息。
考慮下圖,其中顯示了黑白管道和過程的關系:
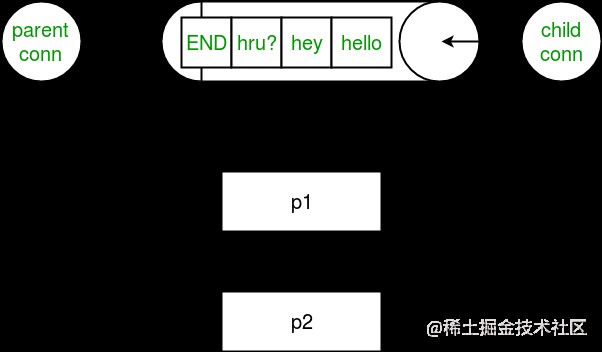
注意: 如果兩個進程(或線程)嘗試同時讀取或寫入管道的同一端,則管道中的數據可能會損壞。當然,同時使用管道不同端的進程不存在損壞的風險。另請注意,隊列在進程之間執行適當的同步,但代價是增加了復雜性。因此,隊列被認為是線程和進程安全的!