本文簡要而簡潔地介紹了Python編程語言中的多進程。
什麼是多進程?
多進程是指系統同時支持多個處理器的能力。多進程系統中的應用程序被分解為獨立運行的較小例程。操作系統將這些線程分配給處理器,以提高系統的性能。
為什麼選擇多進程?
考慮一個具有單個處理器的計算機系統。如果同時為它分配了多個進程,它將不得不中斷每個任務並短暫切換到另一個任務,以保持所有進程的運行。
這種情況就像廚師獨自在廚房工作一樣。他必須做幾項任務,如烘烤,攪拌,揉面團等。
因此,要點是:您必須同時完成的任務越多,跟蹤所有任務就越困難,並且保持正確的時機變得更加具有挑戰性。
這就是多進程概念出現的地方!
多進程系統可以具有:
在這裡,CPU可以輕松地一次執行多個任務,每個任務都使用自己的處理器。
這就像上一種情況下的廚師在他的助手的協助下一樣。現在,他們可以在自己之間分配任務,廚師不需要在他的任務之間切換。
Python中的多進程
在Python中,多進程模塊包括一個非常簡單直觀的API,用於在多個進程之間劃分工作。
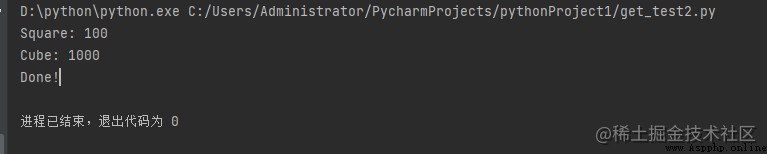
讓我們參考一個使用多處理模塊的簡單示例:
# 導入多進程模塊
import multiprocessing
def print_cube(num):
"""用於打印給定數字的多維數據集的函數"""
print("Cube: {}".format(num * num * num))
def print_square(num):
"""函數打印給定數值的平方"""
print("Square: {}".format(num * num))
if __name__ == "__main__":
# 創建進程
p1 = multiprocessing.Process(target=print_square, args=(10,))
p2 = multiprocessing.Process(target=print_cube, args=(10,))
# 開啟進程1
p1.start()
# 開啟進程2
p2.start()
# 等待進程1完成
p1.join()
# 等待進程2完成
p2.join()
# 進程任務全部完成
print("Done!")
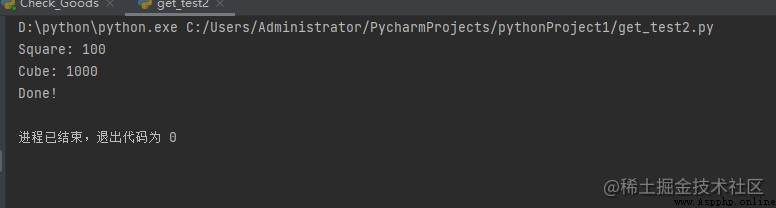
運行結果:
讓我們試著理解上面的代碼:
import multiprocessing
為了創建一個進程,我們創建了一個進程類的對象。它需要以下參數:
注意:流程構造函數也采用許多其他參數,稍後將討論。在上面的例子中,我們創建了2個具有不同目標函數的進程:
p1 = multiprocessing.Process(target=print_square, args=(10, ))
p2 = multiprocessing.Process(target=print_cube, args=(10, ))
要啟動進程,我們使用進程類的啟動方法。
p1.start()
p2.start()
進程啟動後,當前程序也會繼續執行。為了在進程完成之前停止執行當前程序,我們使用 join 方法。
p1.join()
p2.join()
因此,當前程序將首先等待 p1 的完成,然後等待 p2 的完成。一旦它們完成,將執行當前程序的下一個語句。
讓我們考慮另一個程序來理解在同一python腳本上運行的不同進程的概念。在下面的示例中,我們打印運行目標函數的進程的 ID:
# 導入多進程模塊
import multiprocessing
import os
def worker1():
# 打印進程id
print("ID of process running worker1: {}".format(os.getpid()))
def worker2():
# 打印進程id
print("ID of process running worker2: {}".format(os.getpid()))
if __name__ == "__main__":
# 正在打印主程序進程id
print("ID of main process: {}".format(os.getpid()))
# 創建進程
p1 = multiprocessing.Process(target=worker1)
p2 = multiprocessing.Process(target=worker2)
# 開始進程
p1.start()
p2.start()
# 進程ID
print("ID of process p1: {}".format(p1.pid))
print("ID of process p2: {}".format(p2.pid))
# 等待進程完成
p1.join()
p2.join()
# 兩個過程都已完成
print("Both processes finished execution!")
# 檢查進程是否處於活動狀態
print("Process p1 is alive: {}".format(p1.is_alive()))
print("Process p2 is alive: {}".format(p2.is_alive()))
運行結果:
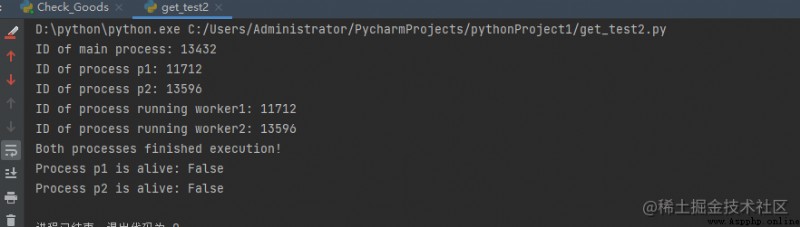
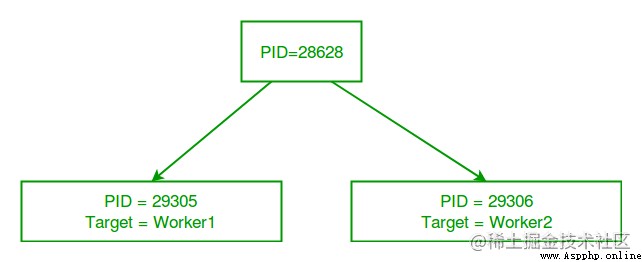
主 python 腳本具有不同的進程 ID,當我們創建進程對象 p1 和 p2 時,多處理模塊會生成具有不同進程 ID 的新進程。在上面的程序中,我們使用os.getpid() 函數來獲取運行當前目標函數的進程的ID。
請注意,它與我們使用 Process 類的 pid 屬性獲取的 p1 和 p2 的進程 ID 匹配。
每個進程獨立運行,並有自己的內存空間。
一旦目標函數的執行完成,進程就會終止。在上面的程序中, 我們使用is_alive方法Process類來檢查進程是否仍然處於活動狀態。
考慮下圖,了解新流程與主要Python腳本的不同之處: