Alors que nous apprenons quelque chose sur l'apprentissage automatique,.En général, nous n'avons pas besoin d'aller chercher les données nous - mêmes,Parce que beaucoup d'algorithmes d'apprentissage sont très amicaux pour nous aider à emballer les données pertinentes,Mais cela ne veut pas dire que nous n'avons pas besoin d'apprendre et de comprendre.Ici, nous apprenons à ramper trois types de données:Fleurs/Ramper pour l'image de l'étoile、Ramper des images d'artistes chinois、Accès aux données sur les stocks.Apprendre et utiliser trois espèces de reptiles séparément.
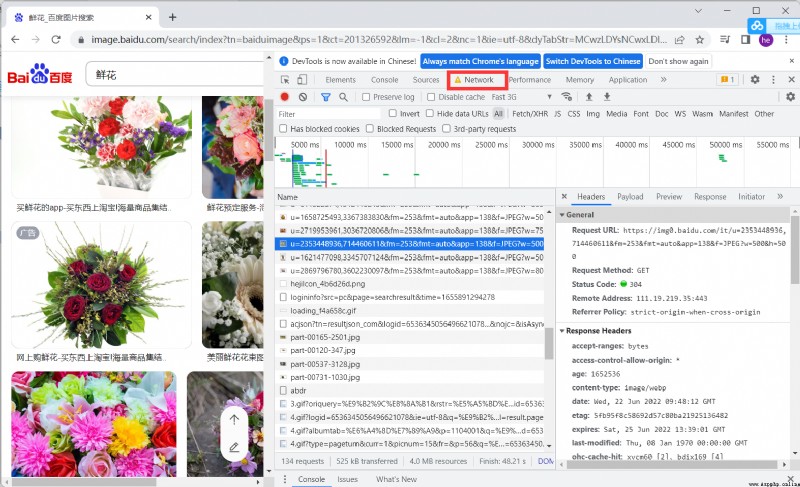
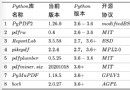
Trouver des paquets pour l'analyse,Analyse des paramètres importants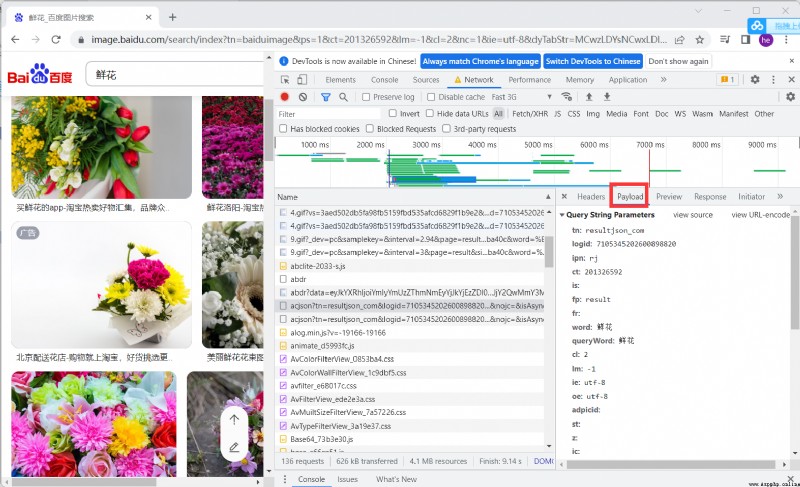
Afficher les valeurs de retour pour l'analyse , Vous pouvez voir que le système d'image ThumbURLMoyenne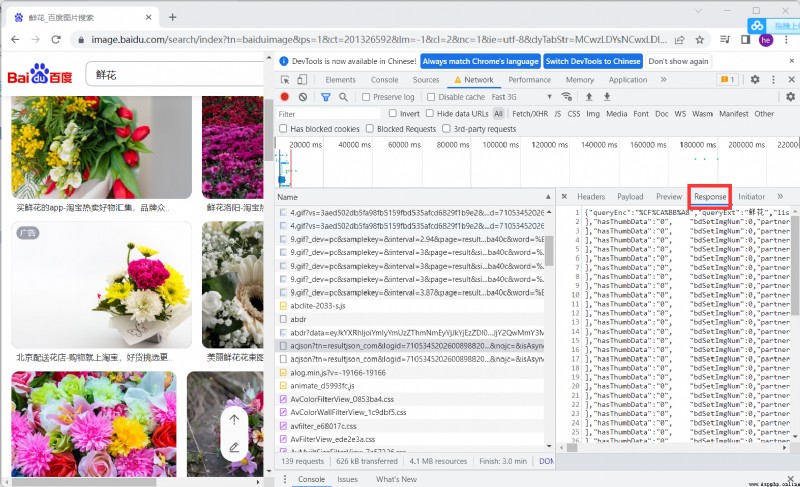
http://image.baidu.com/search/acjson? Baidu picture address
épissagetn Pour accéder à chaque image URL, Après le retour des données thumbURLMoyenne
https://image.baidu.com/search/acjson?+tn
Pour séparer les images URL Puis accédez au téléchargement
import requests
import os
import urllib
class GetImage():
def __init__(self,keyword='Fleurs',paginator=1):
self.url = 'http://image.baidu.com/search/acjson?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
self.keyword = keyword
self.paginator = paginator
def get_param(self):
keyword = urllib.parse.quote(self.keyword)
params = []
for i in range(1,self.paginator+1):
params.append(
'tn=resultjson_com&logid=10338332981203604364&ipn=rj&ct=201326592&is=&fp=result&fr=&word={}&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&expermode=&nojc=&isAsync=&pn={}&rn=30&gsm=78&1650241802208='.format(keyword,keyword,30*i)
)
return params
def get_urls(self,params):
urls = []
for param in params:
urls.append(self.url+param)
return urls
def get_image_url(self,urls):
image_url = []
for url in urls:
json_data = requests.get(url,headers = self.headers).json()
json_data = json_data.get('data')
for i in json_data:
if i:
image_url.append(i.get('thumbURL'))
return image_url
def get_image(self,image_url):
##Selon l'imageurl,Enregistrer l'image
file_name = os.path.join("", self.keyword)
#print(file_name)
if not os.path.exists(file_name):
os.makedirs(file_name)
for index,url in enumerate(image_url,start=1):
with open(file_name+'/{}.jpg'.format(index),'wb') as f:
f.write(requests.get(url,headers=self.headers).content)
if index != 0 and index%30 == 0:
print("No{}Téléchargement de page terminé".format(index/30))
def __call__(self, *args, **kwargs):
params = self.get_param()
urls = self.get_urls(params)
image_url = self.get_image_url(urls)
self.get_image(image_url=image_url)
if __name__ == '__main__':
spider = GetImage('Fleurs',3)
spider()
if __name__ == '__main__':
spider = GetImage('Star',3)
spider()
if __name__ == '__main__':
spider = GetImage('Animation',3)
spider()
import requests
import json
import os
import urllib
def getPicinfo(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:101.0) Gecko/20100101 Firefox/101.0',
}
response = requests.get(url,headers)
if response.status_code == 200:
return response.text
return None
Download_dir = 'picture'
if os.path.exists(Download_dir) == False:
os.mkdir(Download_dir)
pn_num = 1
rn_num = 10
for k in range(pn_num):
url = "https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28266&from_mid=500&format=json&ie=utf-8&oe=utf-8&query=%E4%B8%AD%E5%9B%BD%E8%89%BA%E4%BA%BA&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn="+str(pn_num)+"&rn="+str(rn_num)+"&_=1580457480665"
res = getPicinfo(url)
json_str = json.loads(res)
figs = json_str['data'][0]['result']
for i in figs:
name = i['ename']
img_url = i['pic_4n_78']
img_res = requests.get(img_url)
if img_res.status_code == 200:
ext_str_splits = img_res.headers['Content-Type'].split('/')
ext = ext_str_splits[-1]
fname = name+'.'+ext
open(os.path.join(Download_dir,fname),'wb').write(img_res.content)
print(name,img_url,'saved')
Nous sommes d'accord avechttp://quote.eastmoney.com/center/gridlist.html Les données sur les stocks sont récupérées , Et stocker les données
# http://quote.eastmoney.com/center/gridlist.html
import requests
from fake_useragent import UserAgent
import json
import csv
import urllib.request as r
import threading
def getHtml(url):
r = requests.get(url, headers={
'User-Agent': UserAgent().random,
})
r.encoding = r.apparent_encoding
return r.text
# Combien de rampants
num = 20
stockUrl = 'http://52.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409623798991171317_1654957180928&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1654957180938'
if __name__ == '__main__':
responseText = getHtml(stockUrl)
jsonText = responseText.split("(")[1].split(")")[0];
resJson = json.loads(jsonText)
datas = resJson['data']['diff']
dataList = []
for data in datas:
row = [data['f12'],data['f14']]
dataList.append(row)
print(dataList)
f = open('stock.csv', 'w+', encoding='utf-8', newline="")
writer = csv.writer(f)
writer.writerow(("Code","Nom"))
for data in dataList:
writer.writerow((data[0]+"\t",data[1]+"\t"))
f.close()
def getStockList():
stockList = []
f = open('stock.csv', 'r', encoding='utf-8')
f.seek(0)
reader = csv.reader(f)
for item in reader:
stockList.append(item)
f.close()
return stockList
def downloadFile(url,filepath):
try:
r.urlretrieve(url,filepath)
except Exception as e:
print(e)
print(filepath,"is downLoaded")
pass
sem = threading.Semaphore(1)
def dowmloadFileSem(url,filepath):
with sem:
downloadFile(url,filepath)
urlStart = 'http://quotes.money.163.com/service/chddata.html?code='
urlEnd = '&end=20210221&fields=TCLOSW;HIGH;TOPEN;LCLOSE;CHG;PCHG;VOTURNOVER;VATURNOVER'
if __name__ == '__main__':
stockList = getStockList()
stockList.pop(0)
print(stockList)
for s in stockList:
scode = str(s[0].split("\t")[0])
url = urlStart+("0" if scode.startswith('6') else '1')+ scode + urlEnd
print(url)
filepath = (str(s[1].split("\t")[0])+"_"+scode)+".csv"
threading.Thread(target=dowmloadFileSem,args=(url,filepath)).start()
Il est possible que les données qui ont été rampes à ce moment - là étaient sales , Le code suivant ne fonctionne pas toujours. , Avez - vous besoin de traiter les données vous - même ou d'une autre façon
## Utilisation principalematplotlibPour dessiner des images
import pandas as pd
import matplotlib.pyplot as plt
import csv
import Accès aux données boursières as gp
plt.rcParams['font.sans-serif'] = ['simhei'] #Spécifier la police
plt.rcParams['axes.unicode_minus'] = False #Afficher-No.
plt.rcParams['figure.dpi'] = 100 #Points par pouce
files = []
def read_file(file_name):
data = pd.read_csv(file_name,encoding='gbk')
col_name = data.columns.values
return data,col_name
def get_file_path():
stock_list = gp.getStockList()
paths = []
for stock in stock_list[1:]:
p = stock[1].strip()+"_"+stock[0].strip()+".csv"
print(p)
data,_=read_file(p)
if len(data)>1:
files.append(p)
print(p)
get_file_path()
print(files)
def get_diff(file_name):
data,col_name = read_file(file_name)
index = len(data['Date'])-1
sep = index//15
plt.figure(figsize=(15,17))
x = data['Date'].values.tolist()
x.reverse()
xticks = list(range(0,len(x),sep))
xlabels = [x[i] for i in xticks]
xticks.append(len(x))
y1 = [float(c) if c!='None' else 0 for c in data['Augmentation ou diminution'].values.tolist()]
y2 = [float(c) if c != 'None' else 0 for c in data['Les hauts et les bas'].values.tolist()]
y1.reverse()
y2.reverse()
ax1 = plt.subplot(211)
plt.plot(range(1,len(x)+1),y1,c='r')
plt.title('{}-Augmentation ou diminution/Les hauts et les bas'.format(file_name.split('_')[0]),fontsize = 20)
ax1.set_xticks(xticks)
ax1.set_xticklabels(xlabels,rotation = 40)
plt.ylabel('Augmentation ou diminution')
ax2 = plt.subplot(212)
plt.plot(range(1, len(x) + 1), y1, c='g')
#plt.title('{}-Augmentation ou diminution/Les hauts et les bas'.format(file_name.splir('_')[0]), fontsize=20)
ax2.set_xticks(xticks)
ax2.set_xticklabels(xlabels, rotation=40)
plt.xlabel('Date')
plt.ylabel('Augmentation ou diminution')
plt.show()
print(len(files))
for file in files:
get_diff(file)
Trois cas d'extraction de données sont décrits ci - dessus , Différentes rampes de données exigent que nous fassions face à différents URLObtenir, Entrée de différents paramètres ,URLComment combiner、Comment obtenir、 C'est la difficulté d'accéder aux données. , Une certaine expérience et une certaine base sont nécessaires .
Spider-01-Introduction aux reptiles Python Les reptiles n'ont pas beaucoup de connaissances,Mais je dois continuer à travailler avec le Web.,Chaque page Web est différente,Il y a donc des exigences en matière de capacité variable Préparation des reptiles Références MaîtrisePythonCadre crawlerScrap ...
Parce que beaucoup de gens veulent apprendrePythonCrawler,Il n'y a pas de tutoriel facile à apprendre,Je serai àCSDNPartager avec tout le mondePythonNotes d'étude des reptiles,Mises à jour occasionnelles Exigences de base Python Connaissances de base Python Les bases de,Tout le monde peut aller au tutoriel débutant ...
Python Solutions aux problèmes courants de programmation crawler : 1.Solutions communes: [Tiens bon.Ctrl La clé n'est pas lâche ],Cliquez simultanément sur[Nom de la méthode],Voir le document 2.TypeError: POST data should be bytes ...
1. Joignez d'abord le diagramme d'effet ( J'ai juste rampé 4(En milliers de dollars des États - Unis)) 2. Site Web de JD https://www.jd.com/ 3. Je ne charge pas d'images ici , Accélérer la vitesse de montée ,Peut également être utiliséHeadless Pas de mode pop - up options = webdri ...
Mon nouveau livre,<Basé sur l'analyse des données massives sur les stocksPythonDémarrer le combat réel>,Attendu le2019Publié par Tsinghua Press à la fin de l'année. Si vous êtes intéressé par l'analyse des mégadonnées,,J'ai encore envie d'étudier.Python,Ce livre est un bon choix.Du point de vue du système de connaissances,, ...
Plus de détails,Bienvenue au public:Nombre de maisons techniques, Vous pouvez également ajouter un micro - signal personnel :sljsz01,Communiquer avec moi. Importance des données en temps réel sur les stocks Pour les quatre principaux actifs négociables:Stock.Contrats à terme.Options.Pour la monnaie numérique,Contrats à terme.Options.Monnaie numérique, Peut être livré à partir de ...
L'accès aux données fait partie intégrante de l'analyse des données , Et le Web crawler est l'un des principaux canaux d'accès aux données .Compte tenu de ce qui précède,, J'ai ramassé PythonCette arme pointue, Ouvre la voie au crawler Web . La version utilisée dans cet article est python3.5, J'ai l'intention de saisir l'étoile des titres. ...
Ce chapitre commence par une introduction PythonPrincipes,Pour plus de détails, voir:PythonGuide d'apprentissage Pourquoi être un reptile Le célèbre révolutionnaire .Penseurs.Hommes politiques.Stratège. Ma Yun, le leader de la réforme sociale, était 2015 Année mentionnée par ITAller àDT,Qu'est - ce que ça veut dire?DT,DT ...
Une étape importante du crawler est l'analyse de page et l'extraction de données .Pour plus de détails, voir:PythonGuide d'apprentissage Analyse de la page et extraction des données En fait, le crawler n'est que quatre étapes principales : Allez( Pour savoir dans quel domaine ou site vous recherchez ) Grimpe!( Tous les sites Web ...
Les Crawlers filtrent principalement les informations inutiles dans les pages Web . Obtenir des informations pratiques sur les pages Web L'architecture générale du crawler est : Inpython Avant de ramper, vous devez avoir une certaine connaissance de la structure de la page . Comme l'étiquette de la page web , Connaissance de la langue des pages Web, etc ,Recommandé pourW3School: W3s ...
Environnement:RHEL6.5 + Oracle 11.2.0.4 RAC En installantRACHeure, Paquet manquant lors de l'inspection cvuqdisk-1.0.9-1,oracle Fournir une installation de réparation de script . Mais il y a eu une erreur dans l'exécution : [[email protected] ...
var box = document.getElementById("box"); var btn = document.getElementById("btn" ...
Swoole:PHPAsynchrone de la langue.Parallèle.Cadre de communication réseau haute performance,Utilisation pureCRédaction Linguistique,OffrePHPServeur multithreadé asynchrone pour la langue,AsynchroneTCP/UDPClient réseau,AsynchroneMySQL,Pool de connexion à la base de données,AsyncTask,File d'attente des messages ...
Pour dessiner,Cette méthode sera utiliséeintiWithRectQuand appeler. L'impact de cette approche est qu'il y a touch event Après ça ,Va redessiner, Beaucoup de ces boutons peuvent affecter l'efficacité . Tout ce qui suit sera appelé 1.Si dansUIViewInitialisation ...
Je suis en train decppunit testTravaux connexes,AvecgcovEtlcov Outils pour voir la couverture par ligne de code ,Sentiments personnelslcovC'est génial.,Ça a l'air très confortable., C'est bon de l'allumer aussi !~~ C'est tout. ,Comme question.: J'utiliselcovDe --remov ...
PHP Questions de base pour l'entrevue 1.La différence entre guillemets doubles et simples Les guillemets doubles expliquent les variables,Les guillemets simples n'expliquent pas les variables Insérer des guillemets simples dans les guillemets doubles,S'il y a une variable dans une seule citation,Interprétation des variables Le nom de la variable en guillemets doubles doit être suivi d'un non - nombre .Lettres. Caractères spéciaux soulignés , ...
http://www.techug.com/post/comparing-virtual-machines-vs-docker-containers.html Presse du traducteur: Diverses technologies de machines virtuelles ouvrent l'ère de l'informatique en nuage ...
Un. .Travaux préparatoires 1.Vous devez d'abord téléchargercropper,Utilisation normalenpm, Après avoir entré le chemin du projet, exécutez la commande suivante: : npm install cropper 2. cropperBasé surjquery, N'oubliez pas d'introduire jq,En même temps ...
Conseils“ Impossible de trouver un ou plusieurs types requis pour compiler des expressions dynamiques . Il manque une paire Microsoft.CSharp.dll Et System.Core.dll Références? ”Erreur Solutions: À introduireCOMObjet(misc ...
\(dijkstra\) Optimisation du tas de l'algorithme ,La complexité temporelle est\(O(n+m)\log n\) Ajouter un tableau\(id[]\) Enregistrer la position d'un noeud dans le tas , Il est possible d'éviter les empilements répétés pour réduire les constantes Cette approche repose sur des piles manuscrites #incl ...