一、實現效果(以槿泉壁紙為例)
二、實現過程
三、源碼
四、Python正則表達式匹配日期與時間
一、實現效果(以槿泉壁紙為例)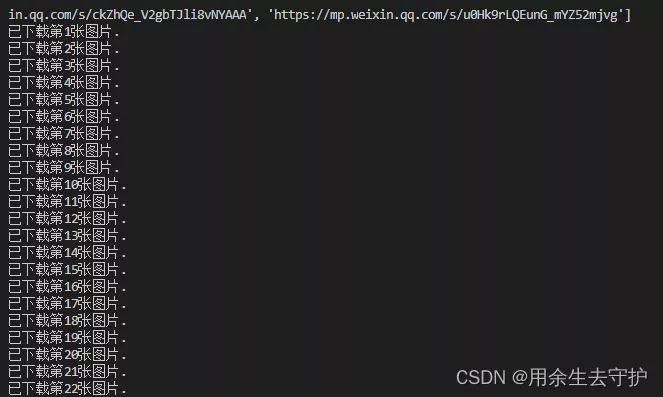

1.新建一個link文本,將需要下載的文章鏈接依次保存;

2.新建一個.py文件,將下面的源碼復制進去;
3.新建一個pic文件夾,用來保存圖片;
4.運行即可;
三、源碼sound code
代碼如下(示例):
import requestsfrom re import findallfrom bs4 import BeautifulSoupimport timeimport osimport sysweixin_title=""weixin_time=""#獲取微信公眾號內容,保存標題和時間def get_weixin_html(url): global weixin_time,weixin_title res=requests.get(url) soup=BeautifulSoup(res.text,"html.parser") #獲取標題 temp=soup.find('h1') weixin_title=temp.string.strip() #使用正則表達式獲取時間# result=findall(r'[0-9]{4}-[0-9]{2}-[0-9]{2}.+:[0-9]{2}',res.text) result=findall(r"(\d{4}-\d{1,2}-\d{1,2})",res.text) weixin_time=result[0] #獲取正文html並修改 content=soup.find(id='js_content') soup2=BeautifulSoup((str(content)),"html.parser") soup2.div['style']='visibility: visible;' html=str(soup2) pattern=r'http[s]?:\/\/[a-z.A-Z_0-9\/\?=-_-]+' result = findall(pattern, html) #將data-src修改為src for url in result: html=html.replace('data-src="'+url+'"','src="'+url+'"') return html#上傳圖片至服務器def download_pic(content): pic_path= 'pic/' + str(path)+ '/' if not os.path.exists(pic_path): os.makedirs(pic_path) #使用正則表達式查找所有需要下載的圖片鏈接 pattern=r'http[s]?:\/\/[a-z.A-Z_0-9\/\?=-_-]+' pic_list = findall(pattern, content) for index, item in enumerate(pic_list,1): count=1 flag=True pic_url=str(item) while flag and count<=10: try: data=requests.get(pic_url); if pic_url.find('png')>0: file_name = str(index)+'.png' elif pic_url.find('gif')>0: file_name=str(index)+'.gif' else: file_name=str(index)+'.jpg' with open( pic_path + file_name,"wb") as f: f.write(data.content) #將圖片鏈接替換為本地鏈接 content = content.replace(pic_url, pic_path + file_name) flag = False print('已下載第' + str(index) +'張圖片.') count += 1 time.sleep(1) except: count+=1 time.sleep(1) if count>10: print("下載出錯:",pic_url) return contentdef get_link(dir): link = [] with open(dir,'r') as file_to_read: while True: line = file_to_read.readline() if not line: break line = line.strip('\n') link.append(line) return linkpath = 'link.txt'linklist = get_link(path)print(linklist)s = len(linklist)if __name__ == "__main__": #獲取html input_flag=True while input_flag:# for j in range(0,s):# pic = str(j) j = 1 for i in linklist: weixin_url = i path = j j += 1 #weixin_url=input() re=findall(r'http[s]?:\/\/mp.weixin.qq.com\/s\/[0-9a-zA-Z_]+',weixin_url) if len(re)<=0: print("鏈接有誤,請重新輸入!") else: input_flag=False content=get_weixin_html(weixin_url) content=download_pic(content) #保存至本地 with open(weixin_title+'.txt','w+',encoding="utf-8") as f: f.write(content) with open(weixin_title+'.html','w+',encoding="utf-8") as f: f.write(content) print() print("標題:《"+weixin_title+"》") print("發布時間:"+weixin_time)四、Python正則表達式匹配日期與時間import refrom datetime import datetimetest_date = '小明的生日是2016-12-12 14:34,小張的生日是2016-12-21 11:34 .'test_datetime = '小明的生日是2016-12-12 14:34,.小晴的生日是2016-12-21 11:34,好可愛的.'# datemat = re.search(r"(\d{4}-\d{1,2}-\d{1,2})",test_date)print mat.groups()# ('2016-12-12',)print mat.group(0)# 2016-12-12date_all = re.findall(r"(\d{4}-\d{1,2}-\d{1,2})",test_date)for item in date_all: print item# 2016-12-12# 2016-12-21# datetimemat = re.search(r"(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2})",test_datetime)print mat.groups()# ('2016-12-12 14:34',)print mat.group(0)# 2016-12-12 14:34date_all = re.findall(r"(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2})",test_datetime)for item in date_all: print item# 2016-12-12 14:34# 2016-12-21 11:34## 有效時間# 如這樣的日期2016-12-35也可以匹配到.測試如下.test_err_date = '如這樣的日期2016-12-35也可以匹配到.測試如下.'print re.search(r"(\d{4}-\d{1,2}-\d{1,2})",test_err_date).group(0)# 2016-12-35# 可以加個判斷def validate(date_text): try: if date_text != datetime.strptime(date_text, "%Y-%m-%d").strftime('%Y-%m-%d'): raise ValueError return True except ValueError: # raise ValueError("錯誤是日期格式或日期,格式是年-月-日") return Falseprint validate(re.search(r"(\d{4}-\d{1,2}-\d{1,2})",test_err_date).group(0))# false# 其他格式匹配. 如2016-12-24與2016/12/24的日期格式.date_reg_exp = re.compile('\d{4}[-/]\d{2}[-/]\d{2}')test_str= """ 平安夜聖誕節2016-12-24的日子與去年2015/12/24的是有不同哦. """# 根據正則查找所有日期並返回matches_list=date_reg_exp.findall(test_str)# 列出並打印匹配的日期for match in matches_list: print match# 2016-12-24# 2015/12/24以上就是Python實現快速保存微信公眾號文章中的圖片的詳細內容,更多關於Python保存文章圖片的資料請關注軟件開發網其它相關文章!