上一篇博文兩萬字博文教你python爬蟲requests庫【詳解篇】被眾多爬蟲愛好者/想要學習爬蟲的小伙伴們閱讀之後,小伙伴們都說學費了學費了,但是又有不少同學私信我做一些要求使用urllib庫實現的爬蟲項目,腦瓜子疼~
(苦笑)程序猿世界:“授之以魚不如授之以漁,” 所以本博主又連夜加班加點,苦苦熬制本文,為大家深入全面的講解一下Python中請求URL連接的官方標准庫——urllib庫以及urllib3庫!”
題外話——如果小伙伴們想要系統性學習爬蟲這門技術,那麼建議本文是你爬蟲路上的第一個必須要熟練掌握的爬蟲庫哦!(而入坑爬蟲的話必備知識點是這篇——一篇萬字博文帶你入坑爬蟲這條不歸路 【萬字圖文】)
重點來啦!重點來啦!!
相信有不少小伙伴已經通過我的上篇博文完全地學費了requests庫,而本篇文講解的urllib庫則是Python內置的HTTP請求庫,也就是說不需要額外安裝即可使用(隨拿隨用,多爽!),同樣是爬蟲必備哦~
直接跳到末尾 ——>領取專屬粉絲福利
️
閒談一嘴:
urllib是Python中請求url連接的官方標准庫,在Python2中主要為urllib和urllib2,在Python3中整合成了urllib。
而urllib3則是增加了連接池等功能,兩者互相都有補充的部分。
就先來看看urllib庫。
簡介:urllib庫(官方文檔!),是Python內置的HTTP請求庫(不需要額外安裝就可以使用哦~),它包含如下4個模塊:
1.request:它是最基本的HTTP請求模塊,可以用來模擬發送請求。就像在浏覽器裡輸入網址然後回車一樣,
只需要給庫方法傳入URL以及額外的參數,就可以模擬實現這個過程了。
2.error:異常處理模塊,如果出現請求錯誤,我們可以捕獲這些異常,然後進行重試或其他操作以保證程序
不會意外終止。
3.parse:一個工具模塊,提供了多種URL處理方法。比如:拆分,解析,合並等。
4.robotparser:主要是用來識別網站的robots.txt文件,然後判斷哪些網站可以爬,哪些網站不可以爬,
其實用的很少!
request模塊主要負責構造和發起網絡請求,並在其中添加Headers,Proxy等,我們可以方便地實現請求的發送並得到響應。
利用它可以模擬浏覽器的請求發起過程。
小拓展——使用代理解釋:(在這篇文章中有書面化的講解,可以看看——學了那麼久爬蟲,快來看看這些反爬,你能攻破多少?【對應看看自己修煉到了哪個等級~】)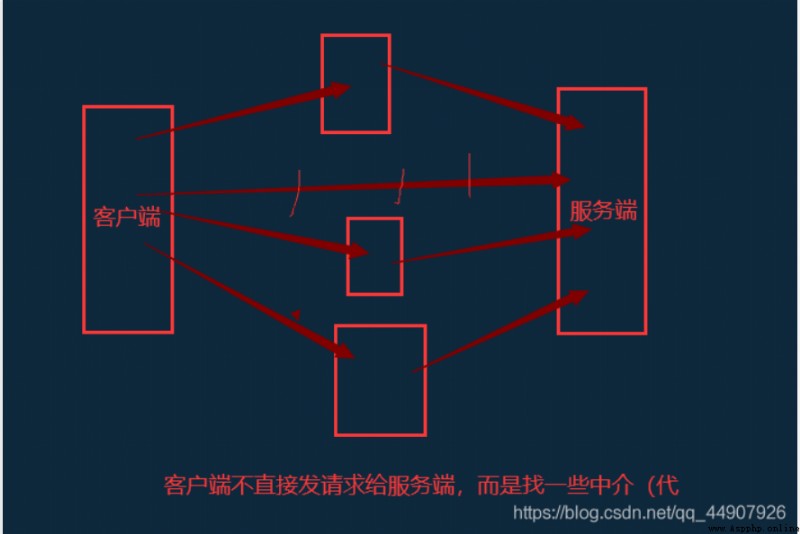
urilib.request模塊提供了最基本的構造HTTP請求的方法,利用它可以模擬浏覽器的一個請求發起的過程,同時它還帶有處理授權驗證(authentication),重定向(redirection),浏覽器Cookies以及其他內容。
小知識點:
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
print(type(response))
print("*"*50)
print(response.read().decode('utf-8'))
很容易的就完成了百度首頁的抓取,輸出了網頁的源代碼。同時,我們發現這個響應是一個HTTPResponse類型的對象,主要包含read(),readinto(),getheader(name),getheaders()等方法,以及msg,version,status,reason等屬性。例如:調用read()方法可以得到返回的網頁內容;調用getheaders()方法可以得到響應的頭信息;調用getheader(name)方法可以得到響應頭中的name值!
大致演示下某些常用方法的實際使用:
from urllib import request
test_url_get = "http://httpbin.org/get" #測試網站
response=request.urlopen(test_url_get,timeout=10,data=None) #有data即為post請求;無data(None)即為get請求
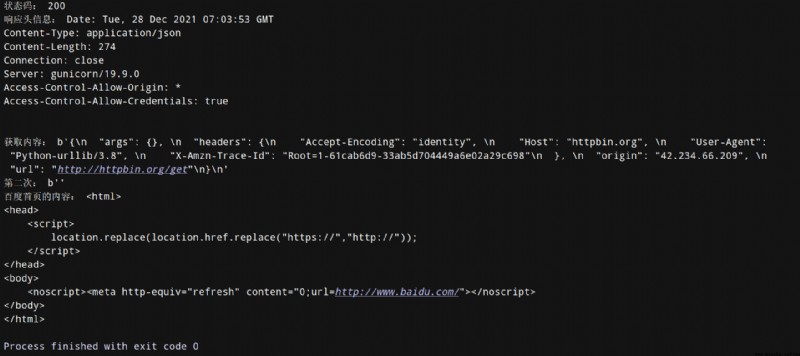
print("狀態碼:",response.getcode()) #獲得狀態碼
print("響應頭信息:",response.info()) #顯示響應頭信息
print("獲取內容:",response.read()) #取出內容
# 需要注意:(如果你這樣搞,服務端一眼就看出來你圖謀不軌,不是正經的客戶端了!)
# 如果是浏覽器直接訪問測試網站:"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
#如果是爬蟲獲取: "User-Agent": "Python-urllib/3.8"
# 一個小重點: read只能read一次,再read就獲取不到信息咯
print("第二次:",response.read()) #輸出:第二次: b''
# 獲取百度首頁
baidu_url = "http://www.baidu.com"
response_baidu = request.urlopen(baidu_url)
print("百度首頁的內容:",response_baidu.read().decode())
# 源碼如下:
def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
*, cafile=None, capath=None, cadefault=False, context=None):
看函數源碼肯定要看看這個函數對應的三大特性:
data參數是可選的,如果需要添加該參數,要使用bytes()方法將參數轉化為字節流編碼格式的內容,即bytes類型。並且,此時它的請求方式也不再是GET方式,而是POST方式(我們傳遞的參數出現在form字段中,表明是模擬了表單提交的方式!)。
import urllib.request,urllib.parse
data = bytes(urllib.parse.urlencode({
'word':'hello'}),encoding='utf-8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())
使用bytes()方法,將參數轉碼為bytes(字節流)類型。該方法第一個參數需要是str(字符串)類型,需要用urllib.parse模塊裡的urlencode()方法來將參數字典轉化為字符串;第二個參數指定編碼格式。

timeout參數用於設置超時時間,單位是秒,意思是如果請求超出了設置的這個時間,還麼有得到響應,就會拋出URLError異常,該異常屬於urllib.error模塊,錯誤原因是超時。如果不指定,就會使用全局默認時間。
用武之地:
可以通過設置這個超時時間來控制一個網頁如果長時間未響應, 就跳過它的抓取。這可以利用try except語句來實現。如下:
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.01)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout): # 判斷異常是socket.timeout類型(意思就是超時異常),從而得出它確實是因為超時而報錯!
print('TIME OUT') # 按照常理來說。0.01秒內基本不可能得到服務器響應,因此輸出了TIME OUT提示。
urlopen()方法可以實現最基本請求的發起,但是不足以構建一個完整的請求。如果請求中需要加入headers等信息,就要使用更強大的Request類來構建!
老樣子,來看看三大特性:
上源碼:
def __init__(self, url, data=None, headers={
},
origin_req_host=None, unverifiable=False,
method=None):
import urllib.request
request = urllib.request.Request('https://www.baidu.com')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
其實,依然使用的是urlopen()方法來發送這個請求,只不過這次該方法的參數不再是URL,而是一個Request類型的對象。通過構造這個數據結構,一方面我們可以將請求獨立成一個對象,另一方面可以更豐富靈活的配置參數。
通過urllib發送的請求會有一個默認的Headers: “User-Agent”:“Python-urllib/3.6”,指明請求是由urllib發送的。所以遇到一些驗證User-Agent的網站時,需要我們自定義Headers把自己偽裝起來。
from urllib import request
img_url = "https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=261409204,1345114629&fm=26&gp=0.jpg"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
req = request.Request(url=img_url,headers=headers) #構建Request對象 作用:向服務端發送請求時,User-Agent改變成了我們定義的這個,簡單偽裝!
# response = request.urlopen(url=img_url) #普通方法
response = request.urlopen(req) #添加了Hearders的高級一點的方法
data = response.read()
with open("cat.jpg","wb") as f:
f.write(data)
# 我們可以來查看一下我們是否真正改變了請求頭信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
test_url = "http://httpbin.org/get"
req = request.Request(url=test_url,headers=headers)
res_test = request.urlopen(req)
print(res_test.read()) #在直接使用urlopen時:"User-Agent": "Python-urllib/3.8"
#但是我們現在使用了Request偽裝,現在就是我們所設置的

import urllib.request,urllib.parse
from fake_useragent import UserAgent
url = 'http://httpbin.org/post'
headers = {
'User-Agent':UserAgent().random
}
dict = {
'name':'Peter'
}
data = bytes(urllib.parse.urlencode(dict), encoding='utf-8')
request = urllib.request.Request(url, data=data, headers=headers, method='POST')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
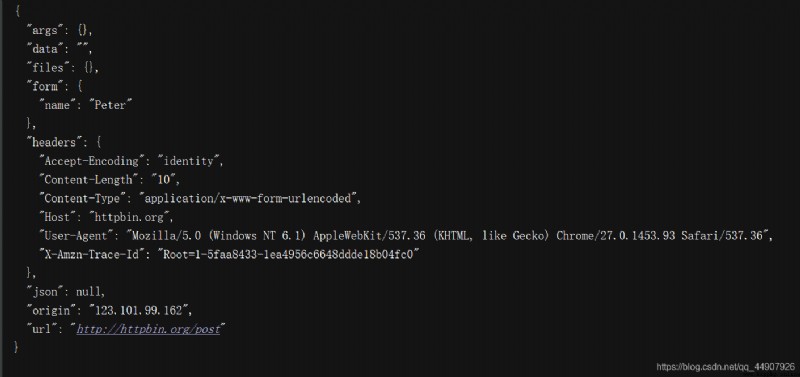
上面我們雖然可以構造請求,但是對於一些更高級的操作(比如Cookies處理,代理設置等),該怎麼辦?
這就需要更強大的工具Handler!簡而言之,我們可以把它理解為各種處理器,有專門處理登錄驗證的,有處理Cookies的,有處理代理設置的。利用他們,我們幾乎可以做到一切HTTP請求中所有的事情。
第一部分:簡介!
urllib.request模塊裡的BaseHandler類是所有其他Handler 的父類,提供了最基本的方法。下面是舉例的各種繼承了這個BaseHandler類的Handler子類:
另一個比較重要的類就是OpenerDirector,我們稱為Opener。之前用過urlopen()這個方法,實際上就是urllib為我們提供的一個Opener。
我們引入Opener,就是因為需要實現更高級的功能。之前使用的Request和urlopen()相當於類庫為你封裝好了極其常用的請求方法,利用它們就可以完成基本的請求,但是現在我們需要通過Handler實現更高級的功能,就要深入一層進行配置,使用更底層的實例來完成操作,這就用到了Opener(簡言之:就是利用Handler來構建Opener)。Opener可以使用open()方法,返回的類型和urlopen()一樣。
第二部分:實戰!
from urllib.request import HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandler,build_opener
from urllib.error import URLError
username = 'username'
password = 'password'
url = 'url'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
# 首先,實例化HTTPBasicAuthHandler對象,參數是HTTPPasswordMgrWithDefaultRealm對象,它利用add_password()添加進去用戶名和密碼,
# 這樣就建立了一個處理驗證的handler。
auth_handler = HTTPBasicAuthHandler(p)
# 然後,使用這個Handler並使用build_opener()方法構建一個Opener,這個Opener在發送請求時就相當於已經驗證成功了!
opener = build_opener(auth_handler)
try:
# 最後,使用Opener的open()方法打開鏈接,就可以完成驗證了!
result = opener.open(url)
html = result.read().decode('utf-8')
except URLError as e:
print(e.reason)
首先,獲取網站的Cookies。
import http.cookiejar,urllib.request
# 首先,聲明一個CookieJar對象
cookie = http.cookiejar.CookieJar()
# 然後,利用HTTPCookieProcessor構建一個Handler
handler = urllib.request.HTTPCookieProcessor(cookie)
# 最後,利用build_opener構建Opener
opener = urllib.request.build_opener(handler)
# 執行open()函數即可!
response = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value)
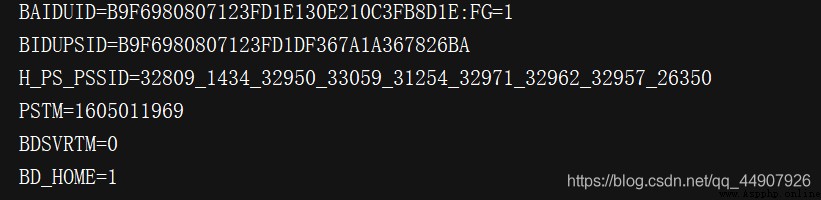
拓展:輸出成文件格式,即以文本形式保存!
import http.cookiejar,urllib.request
filename = 'cookies.txt'
# 此時,CookieJar就需要換成MozillaCookieJar,它在生成文件時會用到,是CookieJar的子類,
# 可以用來處理Cookie和文件相關的事件,比如讀取和保存Cookie,可以將Cookies保存成
# Mozilla型浏覽器的Cookie格式。
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
“
如果改為
cookie = http.cookiejar.LWPCookirJar(filename)
那麼會保存成libwww-perl(LWP)格式的Cookies文件!
”
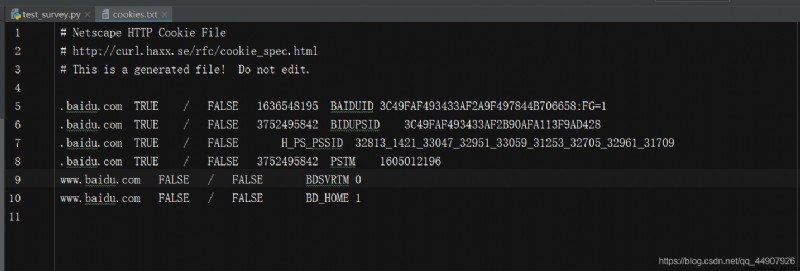
那麼,生成了Cookies文件後,怎樣從文件中讀取利用呢?(以LWPCookieJar格式為例)
import http.cookiejar,urllib.request
cookie = http.cookiejar.LWPCookieJar()
# 調用load()方法來讀取本地的Cookies文件,獲取到了Cookies的內容(注意前提一定要生成並保存了),然後獲取Cookies之後使用同樣的方法構建Handler和Opener即可!
cookie.load('cookies.txt', ignore_expires=True, ignore_discard=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
運行爬蟲的時候,經常會出現被封IP的情況,這是我們就需要使用ip代理來處理,urllib的IP代理的設置如下:
from urllib import request
url = "http://httpbin.org/ip"
# 代理地址
proxy = {
"http":"域名:端口號"}
# 代理處理器
proxies = request.ProxyHandler(proxy)
# 創建openner對象
openner = request.build_opener(proxies)
res = openner.open(url)
print(res.read().decode())
error模塊主要負責處理異常,如果請求出現錯誤,我們可以用error模塊進行處理。
主要包含URLError和HTTPError
URLError類來自urllib庫的error模塊,它繼承自OSError類,是error異常模塊的基類,由request模塊產生的異常都可以通過捕獲這個類來處理。(屬性reason:返回錯誤的原因。)
from urllib import request,error
try:
response = request.urlopen('http://www.baidu.com/peter')
except error.URLError as e:
print(e.reason)
我們打開一個不存在的頁面,本來該報錯,但是我們捕獲了這個URLError異常。
它是URLError的子類,專門用來處理HTTP請求錯誤,比如認證請求失敗等。它有如下三個屬性:
因為URLError是HTTPError的父類,所以可以先選擇捕獲子類的錯誤,如果不是HTTPError異常,再去捕獲父類的錯誤:
from urllib import request,error
try:
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
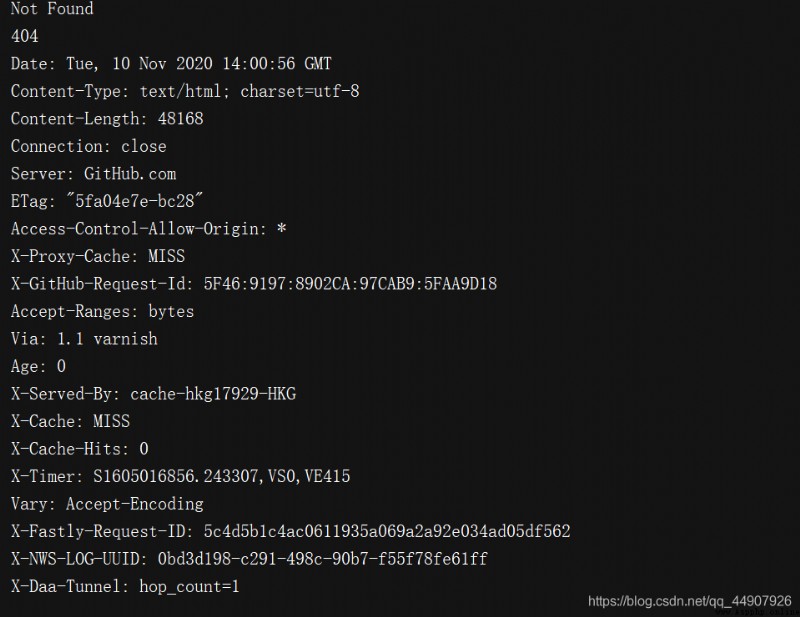
拓展:注意!有時候reason屬性返回的不一定是字符串,也可能是一個對象,如下例子:
from urllib import request,error
import socket
try:
response = request.urlopen('http://www.baidu.com', timeout=0.01)
except error.URLError as e:
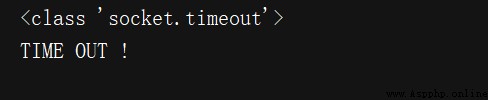
print(type(e.reason))
if isinstance(e.reason, socket.timeout):
print('TIME OUT !')
urllib庫裡還提供了parse模塊(是一個工具模塊),它定義了處理URL的標准接口,例如:實現URL各部分的抽取、合並以及鏈接轉換。
該方法可以實現URL的識別和分段。
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result), result)
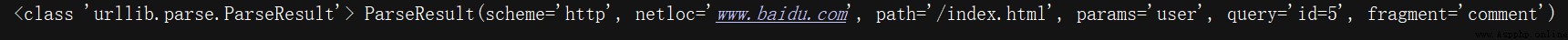
返回的結果是一個ParseResult類型的對象,urlparse()方法將其拆分成了6個部分:
/前面的就是scheme,代表協議;第一個/符號前面的便是netloc,即域名;後面是path,即訪問路徑;分號;後面的是params,代表參數;問號?後面是查詢條件query,一般用作GET類型的URL;井號#後面的是錨點,用於直接定位頁面內部的下拉位置。(更多詳解請看本篇:一篇萬字博文帶你入坑爬蟲這條不歸路 【萬字圖文】)
可得一個標准的鏈接格式:
scheme://netloc/path;params?query#fragment
urlparse()的API用法:
# 源碼:
def urlparse(url, scheme='', allow_fragments=True):
# 三個參數講解:
“
1.url:必填項,即待解析的URL;
2.scheme:默認的協議(比如http或https等)。scheme參數只有在URL中不包含scheme信息時才生效。如果URL中有scheme信息,就會返回解析出的scheme。
3.allow_fragments:即是否忽略fragment。如果它被設置為False,fragment部分就會被忽略,會被解析為path,parameters或者query的一部分,而fragment部分為空。
”
舉例看:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False)
print(result)

假設URL中不包含params和query,再試試:
可以發現,fragment會被解析為path的一部分;
而且,返回結果ParseResult實際上是一個元組,可以用索引順序或者屬性名獲取!
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result)
print(result.scheme, result[0], sep='\n')

urlparse()的對立方法urlunparse(),接收的參數是一個可迭代對象,長度必須是6,否則會報錯!
from urllib.parse import urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))
此處的參數data用了列表類型,當然也可以使用其他類型,比如元組或者特定的數據結構!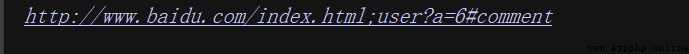
和urlparse()方法非常相似,但是不再單獨解析params,它只返回5個結果,上面例子中的params會合並到path中。(常用!)如下:
from urllib.parse import urlsplit
result = urlsplit('http://www.baidu.com/index.html;user?id=5#comment')
print(result)
# 它的返回結果是SplitResult,是一個元組類型,可以用屬性及索引獲取!
print('返回結果是:',type(result))
print(result.scheme, result[0], sep='\n')

與urlunparse()類似,它也是將鏈接各個部分組合成完整鏈接的方法,傳入的參數也是一個可迭代對象,唯一的區別是長度必須是5!
from urllib.parse import urlunsplit
data = ['http', 'www.baidu.com', 'index.html;user', 'a=6', 'comment']
print(urlunsplit(data))

上述的urlunparse()和urlunsplit()方法可以完成鏈接的合並,但是前提是必須有特定長度的對象,鏈接的每一部分都要清晰分開。
這就要用到生成鏈接的另一個方法—urljoin()方法。我們可以提供一個base_url(基礎鏈接)作為第一個參數,將新的鏈接作為第二個參數,該方法會分析base_url的scheme,netloc和path這3個內容並對新鏈接缺失的部分進行補充,最後返回結果。
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com', 'FAQ.html'))
print(urljoin('http://www.baidu.com', 'https://pythonsite.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://pythonsite.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://pythonsite.com/FAQ.html?question=2'))
print(urljoin('http://www.baidu.com?wd=abc', 'https://pythonsite.com/index.php'))
print(urljoin('http://www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com#comment', '?category=2'))
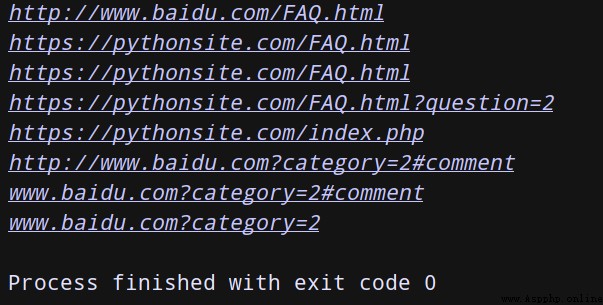
可以發現,base_url提供了三項內容scheme,netloc和path。如果這三項在新的鏈接裡不存在,就予以補充;如果存在,就使用新鏈接裡的!
一句話總結—從拼接的結果我們可以看出,拼接的時候後面的優先級高於前面的url
在發送請求的時候,往往會需要傳遞很多的參數,如果用字符串方法去拼接會比較麻煩,parse.urlencode()方法就是用來拼接url參數的。(將字典格式轉換成url請求參數)
也可以通過parse.parse_qs()方法將它轉回字典
此方法在構造GET請求參數的時候很有用!
# 單個示范
params = parse.urlencode({
"name":"美女","name2":"帥哥","name3":"姐姐"}) #字典格式轉換為url請求參數
print(params)
print("轉換回來:",parse.parse_qs(params)) #url請求參數轉換為字典格式
# 實際使用
test_url2 = "http://httpbin.org/get?{}".format(params)
res2 = request.urlopen(test_url2)
print(res2.read())

有了序列化,必然就有反序列化。可將一串GET請求參數,利用parse_qs()方法將其轉回字典!
from urllib.parse import parse_qs
query = 'name=peter&age=22'
print(parse_qs(query))

用於將參數轉化為元組組成的列表。
from urllib.parse import parse_qsl
query = 'name=peter&age=22'
print(parse_qsl(query))
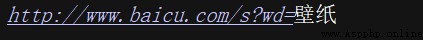
功能:url中只能包含ascii字符,在實際操作過程中,get請求通過url傳遞的參數中會有大量的特殊字符,例如漢字,那麼就需要進行url編碼。
利用parse.unquote()可以反編碼回來。
from urllib.parse import quote
keyword = "壁紙"
url = 'http://www.baicu.com/s?wd=' + quote(keyword)
print(url)
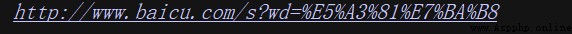
用於將URL解碼。
from urllib.parse import unquote
url = 'http://www.baicu.com/s?wd=%E5%A3%81%E7%BA%B8'
print(unquote(url))
robotparse模塊主要負責處理爬蟲協議文件,robots.txt.的解析。(君子協定)
比如:百度的robots協議:
http://www.baidu.com/robots.txt即可查看。
當搜索爬蟲訪問一個站點時,他首先會檢查這個站點根目錄下是否有robots.txt文件,如果存在,搜索爬蟲會根據其中定義的爬取范圍來爬取。如果沒有,搜索爬蟲便會訪問所有可直接訪問的頁面。
robots.txt文件是一個文本文件,使用任何一個常見的文本編輯器,比如Windows系統自帶的Notepad,就可以創建和編輯它 。robots.txt是一個協議,而不是一個命令。robots.txt是搜索引擎中訪問網站的時候要查看的第一個文件。robots.txt文件告訴蜘蛛程序在服務器上什麼文件是可以被查看的。
舉例:下述Robots協議實現了對所有搜索爬蟲只允許爬取public目錄的功能。
User-agent:*
Disallow: /
Allow: /public/
可以使用robotparser模塊來解析robots.txt,該模塊提供了一個類RobotFileParser,它可以根據某網站的robots.txt文件來判斷一個爬蟲是否有權限來爬取這個網頁。
使用方法,只需在構造方法裡傳入robots.txt的鏈接即可。當然,也可在聲明的時候不傳入,默認為空,最後再使用set_url()方法設置也可。下述是它的聲明:
# 源碼:
def __init__(self, url=''):
from urllib.robotparser import RobotFileParser
# 首先,創建RobotFileParser對象
rp = RobotFileParser()
# 然後,通過set_url()方法設置了robots.txt的鏈接
rp.set_url('http://www.jianshu.com/robots.txt')
rp.read()
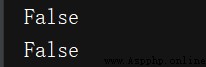
# 利用can_fetch()方法判斷了網頁是否可以被抓取
print(rp.can_fetch('*', 'http://www.jianshu.com/p'))
print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7dsdfsdf'))
同樣可以使用parse()方法執行讀取和分析:
from urllib.robotparser import RobotFileParser
from urllib.request import urlopen
# 首先,創建RobotFileParser對象
rp = RobotFileParser()
rp.parse(urlopen('http://www.jianshu.com/robots.txt').read().decode('utf-8').split('\n'))
# 利用can_fetch()方法判斷了網頁是否可以被抓取
print(rp.can_fetch('*', 'http://www.jianshu.com/p'))
print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7dsdfsdf'))
urllib3 是一個基於python3的功能強大,友好的http客戶端。越來越多的python應用開始采用urllib3.它提供了很多python標准庫裡沒有的重要功能(線程安全,連接池)。
源碼:
request(self, method, url, fields=None, headers=None,**urlopen_kw)
import urllib3
import json
http=urllib3.PoolManager() #實例化一個連接池對象 保持socket開啟。這個對象處理了連接池和線程安全的所有細節,所以我們不用自行處理!
test_url = "http://httpbin.org/get"
# 添加頭
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
#參數fileds使用:如果是get就將fields這個字典轉換為url參數;如果是post就將fields這個字典轉換為form表單數據。
#對於put和post請求,需要提供字典類型的參數field來傳遞form表單數據。如何獲取JSON響應格式數據內的特定信息,借鑒小拓展部分!
data_dict={
"name1":"allen","name2":"rose"}
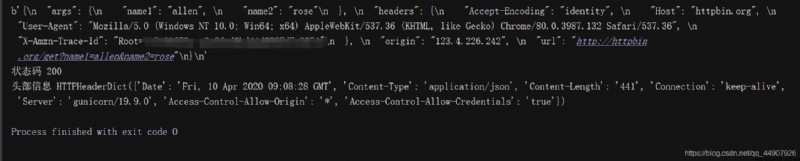
res = http.request("GET",test_url,headers=headers,fields=data_dict) #功能:發送完整的網絡請求
print(res.data) #獲取內容
print("狀態碼",res.status) #狀態碼
print("頭部信息",res.headers) #響應頭信息
 如果是POST請求,會將fields對應的字典轉換為form表單數據:
如果是POST請求,會將fields對應的字典轉換為form表單數據:
在上述代碼加入:
data = res.data.decode() #將字節數據轉換為utf-8格式
print(json.loads(data)["args"]["name1"]) #json.loads()將json數據轉換為字典,這樣可以進行特定信息的獲取
#輸出為:allen
當我們需要發送json數據時,我們需要在request中傳入編碼後的二進制數據類型的body參數,並制定Content-Type的請求頭:
import json
import urllib3
http=urllib3.PoolManager() #實例化一個連接池對象 保持socket開啟。這個對象處理了連接池和線程安全的所有細節,所以我們不用自行處理!
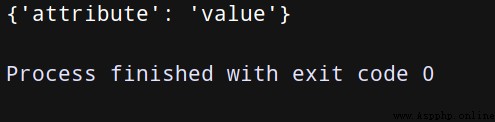
data = {
'attribute': 'value'}
encoded_data = json.dumps(data).encode('utf-8')
r = http.request('post', 'http://httpbin.org/post',body=encoded_data,
headers={
'Content-Type':' application/json'})
print(json.loads(r.data.decode('utf-8'))['json'])
對於文件上傳,我們可以模仿浏覽器表單的方式:
import json
import urllib3
http=urllib3.PoolManager() #實例化一個連接池對象 保持socket開啟。這個對象處理了連接池和線程安全的所有細節,所以我們不用自行處理!
with open('test.txt') as f:
file_data = f.read()
r = http.request('post', 'http://httpbin.org/post',
fields={
'filefield': ('test.txt', file_data)
})
print(json.loads(r.data.decode('utf-8'))['files'])
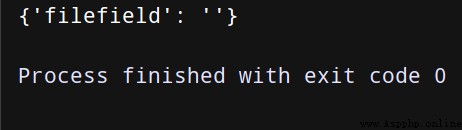
(只做模擬,所以文件是空文件)
對於二進制的數據上傳,我們用指定body的方式,並設置Content-Type的請求頭:
import json
import urllib3
http=urllib3.PoolManager() #實例化一個連接池對象 保持socket開啟。這個對象處理了連接池和線程安全的所有細節,所以我們不用自行處理!
with open('girl.jpg', 'rb') as f:
binary_data = f.read()
r = http.request('post', 'http://httpbin.org/post',
body=binary_data,
headers={
'Content-Type': 'image/jpeg'})
print(json.loads(r.data.decode('utf-8'))['files'])
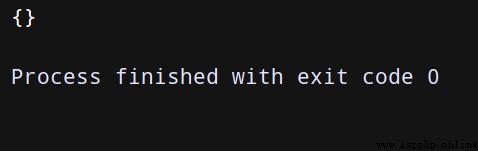
(只做模擬,所以圖片也是空的)
可以利用ProxyManager進行http代理操作:
import urllib3
proxy = urllib3.ProxyManager('http://111.11.111.11:1111')
res = proxy.request('get', 'http://httpbin.org/ip')
print(res.data)