之前介紹了計算機視覺的基礎內容,本篇正式介紹計算機視覺一個應用廣泛的內容,圖像的檢索與識別,這裡我們使用的方法是由自然語言處理領域的Bag-of-words 模型改進而來的Bag of features。
在介紹Bag of features模型前,我們先介紹其原型Bag-of-words 模型。
Bagofwords模型,也叫做“詞袋”,在信息檢索中,Bag of words model假定對於一個文本,忽略其詞序和語法、句法,將其僅僅看做是一個詞集合,或者說是詞的一個組合,文本中每個詞的出現都是獨立的,不依賴於其他詞是否出現,或者說當這篇文章的作者在任意一個位置選擇一個詞匯都不受前面句子的影響而獨立選擇的。
研表究明,漢字序順並不定一影閱響讀。比如當你看完這句話後,才發這現裡的字全是都亂的。
具體原理可以參考我以前寫的樸素貝葉斯算法裡的詞袋模型:機器學習_5:樸素貝葉斯算法
簡單來說,詞袋模型拋棄了詞與詞之間的聯系,將每個詞單獨進行比較,比如如果兩個文檔具有相似的內容,那麼它們就是相似的,最典型的例子就是回文,比如信言不美,美言不信,讀起來意思不一樣,但如果是詞袋檢測的話會認為這兩句話是同一個句子。
和以前的特征提取一樣,我們使用SIFT算法提取特征點,假設我們每張圖像提取的特征點數目是固定的100個(實際上每幅圖像能提取的特征點數量不同且遠遠大於100個),假設有100張圖片(實際圖片數目遠比這個多),那麼我們一共可以收集到1萬個特征點。如果我們直接用這1萬個特征點作為視覺詞典,針對輸入特征集,根據視覺詞典進行量化,把輸入圖像轉化成視覺單詞(visual words)的頻率直方圖。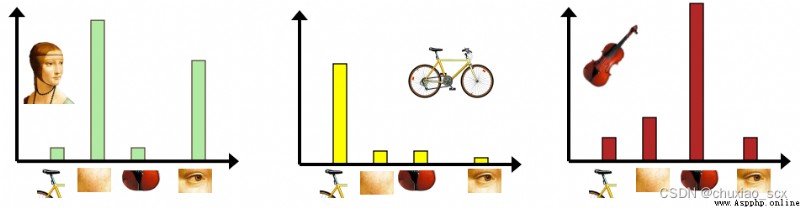
如圖所示,類似圖像中的例子,但如果我們這1萬個特征點都作為特征向量的話,每幅圖像的頻率直方圖就會變得很寬,使用率才1/100。所以我們使用其他方法來將特征向量的數量減少。
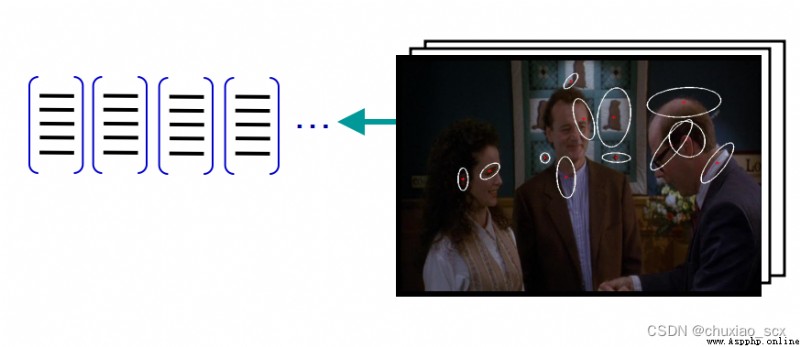
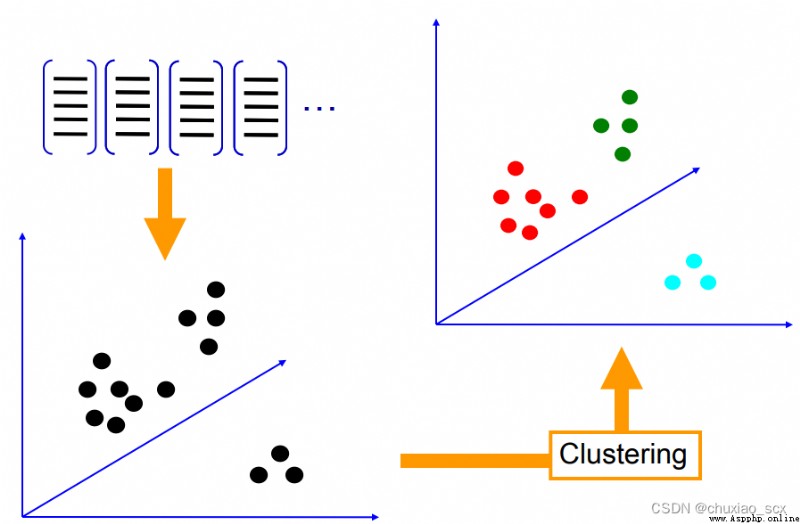
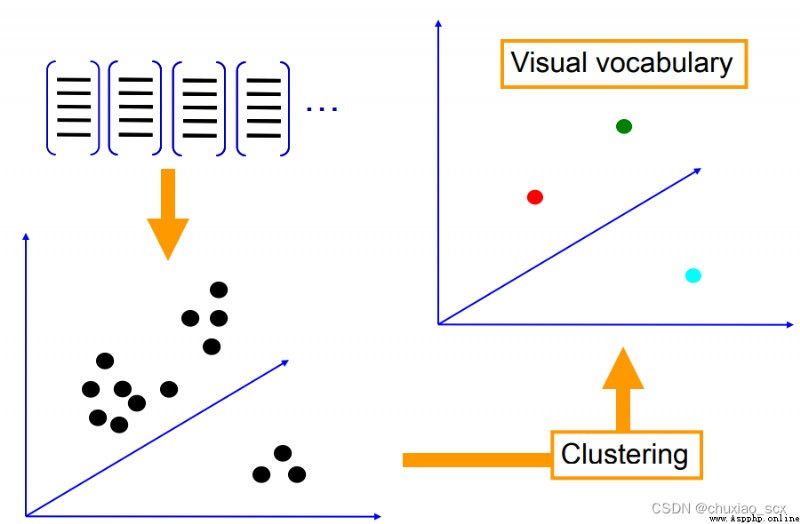
如圖所示,每個特征點都有RGB三個像素通道,我們將這些特征點轉換成RGB色彩空間中的立體點,然後隨機設置k個聚類中心,最小化每個特征 xi 與其相對應的聚類中心 mk之間的歐式距離,最後將所有的特征點聚集成k個特征中心,這樣我們就可以大幅度減少視覺詞典內的特征數。
算法流程:
1.隨機初始化 K 個聚類中
2.重復下述步驟直至算法收斂:
對應每個特征,根據距離關系賦值給某個中心/類別
對每個類別,根據其對應的特征集重新計算聚類中心
問題顯而易見,k的取值是比較難以確定的,k值太少,視覺單詞無法覆蓋所有可能出現的情況,k值過大,計算量大,容易過擬合
那麼有了給定圖像的bag-of-features直方圖特征,應該如何實現圖像分類/檢索呢?
給定輸入圖像的BOW直方圖, 在數據庫中查找 k 個最近鄰的圖像,對於圖像分類問題,可以根據這k個近鄰圖像的分類標簽,投票獲得分類結果,當訓練數據足以表述所有圖像的時候,檢索/分類效果良好
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
#獲取圖像列表
imlist = get_imlist("D:\\vscode\\python\\input\\image")
nbr_images = len(imlist)
print('nbr_images:',nbr_images)
#獲取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#提取文件夾下圖像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
#生成詞匯
voc = vocabulary.Vocabulary('Image')
voc.train(featlist, 200, 10)#調用了PCV的vocabulary.py中的train函數
#保存詞匯
with open('D:\\vscode\\python\\input\\image\\vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)#將生成的詞匯保存到vocabulary.pkl(f)中
print ('vocabulary is:', voc.name, voc.nbr_words)
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#獲取圖像列表
imlist = get_imlist("D:\\vscode\\python\\input\\image")
nbr_images = len(imlist)
#獲取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#載入詞匯
with open('D:\\vscode\\python\\input\\image\\vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#創建索引
indx = imagesearch.Indexer('testImaAdd.db',voc)
indx.create_tables()
#遍歷所有的圖像,並將它們的特征投影到詞匯上
for i in range(nbr_images)[:110]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
#提交到數據庫
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
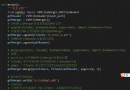
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
#載入圖像列表
imlist = get_imlist('D:\\vscode\\python\\input\\image')
nbr_images = len(imlist)
#載入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#載入詞匯
with open('D:\\vscode\\python\\input\\image\\vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
#查詢圖像索引和查詢返回的圖像數
q_ind = 1
nbr_results = 5
# 常規查詢(按歐式距離對結果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print ('top matches (regular):', res_reg)
# load image features for query image
#載入查詢圖像特征
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# RANSAC model for homography fitting
#用單應性進行擬合建立RANSAC模型
model = homography.RansacModel()
rank = {
}
# load image features for result
#載入候選圖像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
# sort dictionary to get the most inliers first
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 顯示查詢結果
imagesearch.plot_results(src,res_reg[:5]) #常規查詢
imagesearch.plot_results(src,res_geom[:5]) #重排後的結果

1.使用k-means聚類,除了其K和初始聚類中心選擇的問題外,對於海量數據,輸入矩陣的巨大將使得內存溢出及效率低下。
2.字典大小的選擇也是問題,字典過大,單詞缺乏一般性,對噪聲敏感,計算量大,關鍵是圖象投影後的維數高;字典太小,單詞區分性能差,對相似的目標特征無法表示。
3.相似性測度函數用來將圖象特征分類到單詞本的對應單詞上,其涉及線型核,塌方距離測度核,直方圖交叉核等的選擇。