#####################################################
##### 對電影數據的操作。 生成啞變量
#####################################################
import os
data_dir = "python數據科學手冊/pydata-book-2nd-edition-代碼/datasets/movielens"
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table(os.path.join(data_dir, 'movies.dat'), sep='::', header=None, names=mnames)
movies.head()
all_genres = []
for x in movies.genres:
all_genres.extend(x.split('|'))
movies.shape
len(all_genres)
genres = pd.unique(all_genres)
len(genres)
genres
'''
構建指標DataFrame的方法之一是從一個全零DataFrame開始:
'''
zero_matrix = np.zeros((len(movies), len(genres)))
zero_matrix.ndim
zero_matrix.shape
dummies = pd.DataFrame(zero_matrix, columns=genres)
dummies
gen = movies.genres[0]
gen
gen.split('|')
dummies.columns.get_indexer(gen.split('|'))
######################
#### 這裡的 get_indexer 功能很好,就是獲得標簽,從一個列表裡面,找到 相符合的, 獲得它的編號。
# 必須是 columns 的方法。
######################
dummies.columns.get_indexer(movies.genres[1].split('|'))
dummies.columns.get_indexer(movies.genres[3].split('|'))
movies.genres
for i, gen in enumerate(movies.genres):
indices = dummies.columns.get_indexer(gen.split("|"))
dummies.iloc[i, indices] = 1
dummies
'''
這個操作 值得學習。
'''
#
# g2 = movies.genres[2]
# g2
# g2.split('|')
#
# dummies
# x = pd.DataFrame(np.zeros(18))
# x
# x.get_indexer(g2.split('|'))
# x.columns = genres
# genres
# dfx = pd.DataFrame(x, columns=genres)
# dfx
# dfx.get_indexer(g2.split('|'))
# dfx.columns.get_indexer(g2.split('|'))
# locx = dfx.columns.get_indexer(g2.split('|'))
# locx
#
# dfx.iloc[0, locx] = 10
# dfx.iloc[0,]
# dfx
movies_windic = movies.join(dummies.add_prefix('Genre_'))
movies_windic.iloc[0]
這段代碼裡面,最騷的操作就是 get_indexer。
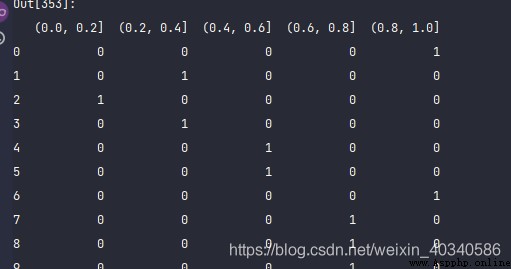
使用cut生成虛擬變量也很方便。
比如
np.random.seed(12345)
values = np.random.rand(10)
values
bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
pd.get_dummies(pd.cut(values, bins))
另外, add_prefix, 可以直接對變量名字全部修改。比如:
df = pd.DataFrame(np.arange(12).reshape(3, 4),
columns=list('abcd'))
df
df.add_prefix('key_')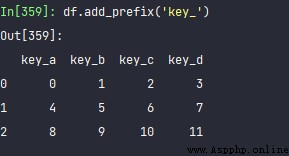
這部分用我自己的例子做一個。
有一個數據是這樣的。
一些組織的活動,也是分成好多類別。
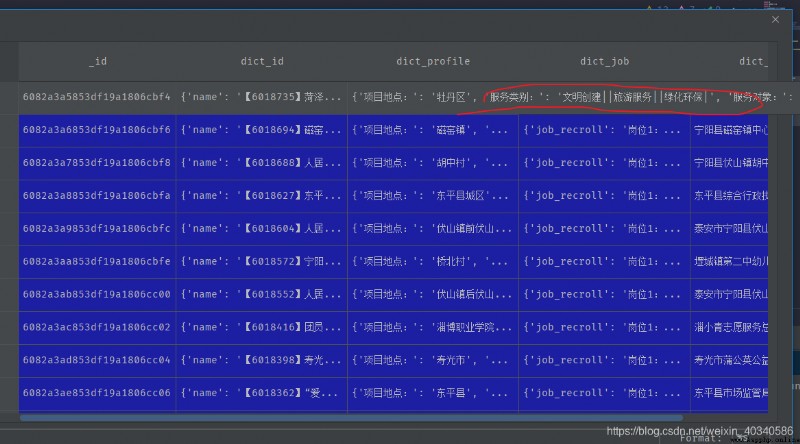
這個數據只不過稍微更復雜一點,服務類別是在dict_profile這個鍵裡面。還需要抽出來。不影響。
import os
path = "all_volunteer_data_dir/每一個項目的信息(包含多個字典)"
import pandas as pd
df = pd.read_pickle(path)
df.keys()
df.iloc[0,]
df.shape
df = df.iloc[:100]
df.shape
df.keys()
df['dict_profile']
serve_type = []
for i in range(df.shape[0]):
profile = df.iloc[i, ]['dict_profile']
serve_type.append(profile['服務類別:'])
serve_type

先得到serve_type的列表。然後添加僅df
df['serve_type'] = serve_type
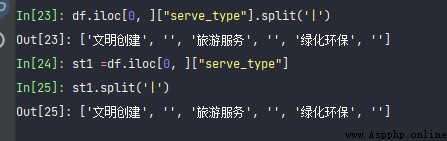
df.iloc[0, ]["serve_type"].split('|')
st1 =df.iloc[0, ]["serve_type"]
st1.split('|')
st1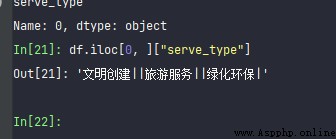
好了,准備就緒,開始生成虛擬變量。
serve_type_all = []
for i in range(df.shape[0]):
serve_type_listi = df.iloc[i,]['serve_type'].split("|")
serve_type_all.extend(serve_type_listi)
len(serve_type_all)
pd.Series(serve_type_all).value_counts()
import numpy as np
serve_type_all = np.unique(serve_type_all)
serve_type_all
serve_type_all.delete([""])
serve_type_all
new_serve_type_all = np.delete(serve_type_all, 0)
new_serve_type_all
這樣獲得所有服務類別的列表。

不過,這個還是不能用到循環裡
在循環裡,加一個判斷,字符長度不能為0,就剔除了,空格。
for i, st in enumerate(df['serve_type']):
st_list = st.split('|')
clean_st_list = [ s for s in st_list if len(s) >0]
indices = dummies.columns.get_indexer(clean_st_list)
dummies.iloc[i, indices] = 1
dummies結果,就能得到dummies

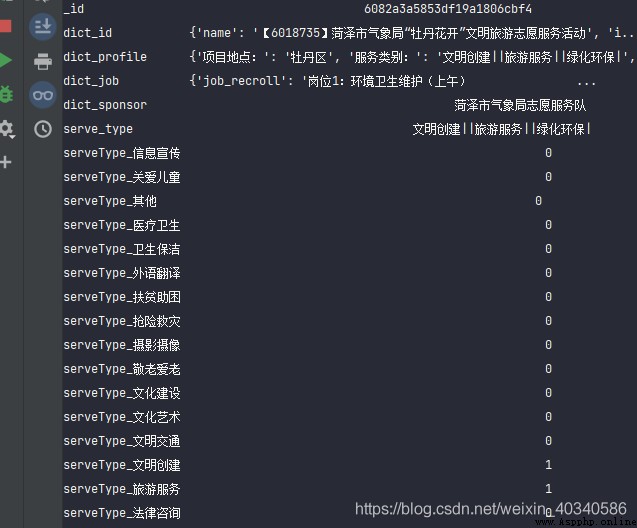
查看第一行數據,結果如下:
df_with_serve_type = df.join(dummies.add_prefix("serveType_"))
df_with_serve_type.iloc[0, ]