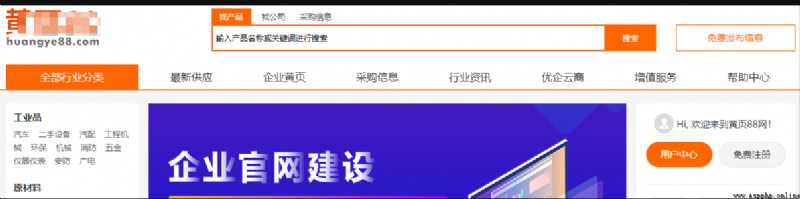
本次采集的目標站點為 aHVhbmd5ZTg4.com ,首頁截圖如下所示。
在官網找到【黃x頁】選項卡,然後得到如下界面,其中涉及的信息如下,隨機找到一個公開數據。
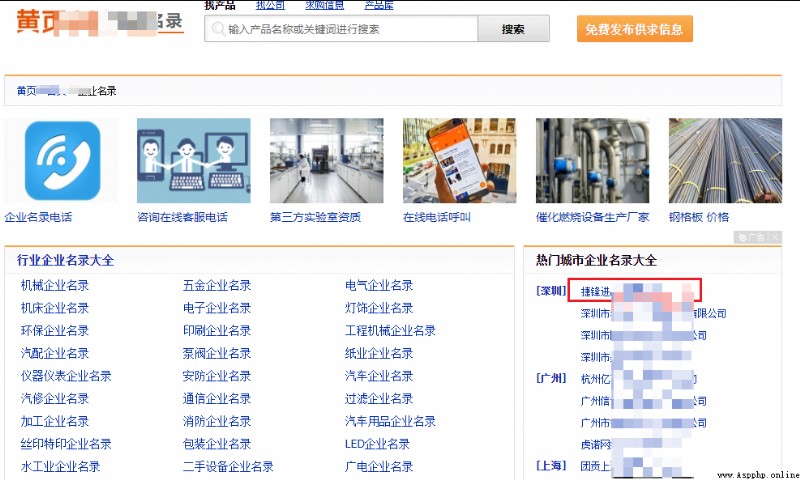
在公司黃頁詳情頁可以查看到聯系人和聯系號碼。

這裡明顯看到手機字體與其它字體有所差異,通過開發者工具進行驗證之後,確定存在字體反爬。
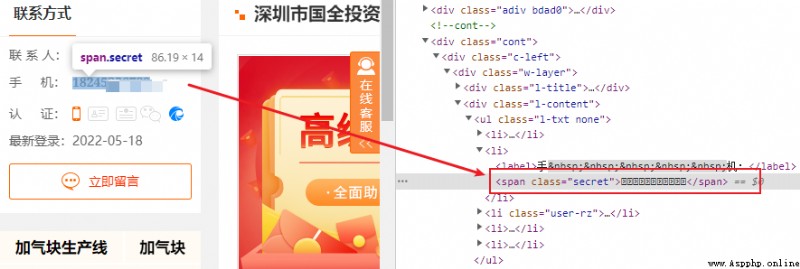
保存字體文件,得到下述字體矢量圖。

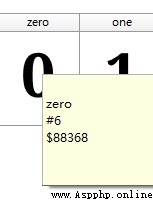
結果字體的編碼是固定的英文,那這字體反爬的難度就變的極低了。
通過開發者工具可以找到字體文件在網頁源碼中,所以我們編寫一下相關提取代碼。
import re
import requests
import base64
from fontTools.ttLib import TTFont
url = 'https://b2b.huangye88.com/qiye1edkfp0964c7/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36'
}
res_text = requests.get(url=url, headers=headers).text
ba64 = re.findall('base64,(.*?)\"\)', res_text)[0]
# print(ba64)
data = base64.b64decode(ba64)
with open('./fonts/519.woff', 'wb') as f:
f.write(data)
font = TTFont('./fonts/519.woff')
font.saveXML('./fonts/519.xml')
得到字體之後,保存的 XML 文檔如下所示。
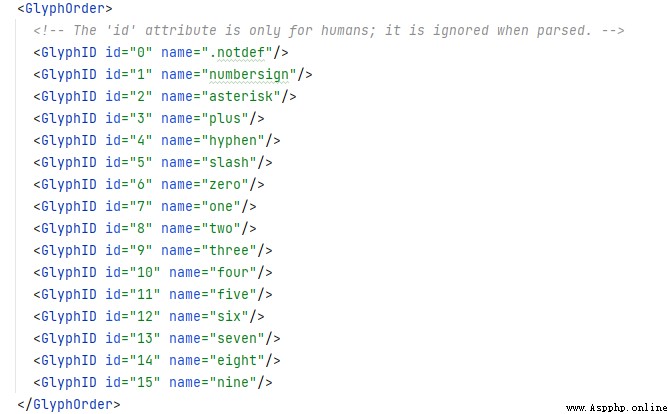
本案例已經結束。
你正在閱讀 【夢想橡皮擦】 的博客
閱讀完畢,可以點點小手贊一下
發現錯誤,直接評論區中指正吧
橡皮擦的第 680 篇原創博客
從訂購之日起,案例 5 年內保證更新