# use pymysql The module establishes a database connection , And read the data in the database
import pandas as pd
from pymysql import *
conn=connect(host='localhost',port=3306, database='database_name', user='root', password='123456',charset='utf8')
#host Is the host connecting to the database IP Address ,mysql The default port is 3306,database Is the name of the database ,user and password They are the account and password for connecting to the database ,charset Is the database character encoding
# Write a SQL sentence , use read_sql() Function to read
sql_cmd='SELECT * FROM table_name'
df=pd.read_sql(sql_cmd, conn)
df.head()
# Test the parameters parse_dates The role of
sql_cmd_2 = "SELECT * FROM test_date"
df_1 = pd.read_sql(sql_cmd_2, conn)
df_1.head()
""" output number date_columns 0 1 2021-11-11 1 2 2021-10-01 2 3 2021-11-10 """
df_1.info()
""" <class 'pandas.core.frame.DataFrame'> RangeIndex: 3 entries, 0 to 2 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 number 3 non-null int64 1 date_columns 3 non-null object dtypes: int64(1), object(1) memory usage: 176.0+ bytes """
# Normal by default ,date_columns This column is also regarded as String Data of type , If we pass parse_dates Parameter applies date resolution to the column
df_2 = pd.read_sql(sql_cmd_2, conn, parse_dates="date_columns")
df_2.info()
""" <class 'pandas.core.frame.DataFrame'> RangeIndex: 3 entries, 0 to 2 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 number 3 non-null int64 1 date_columns 3 non-null datetime64[ns] dtypes: datetime64[ns](1), int64(1) memory usage: 176.0 bytes """
# It is converted to the corresponding date format , Of course, we can also use another format mentioned above
parse_dates={
"date_column": {
"format": "%d/%m/%y"}}
df_3 = pd.read_sql(sql_cmd_2, conn, parse_dates=parse_dates)
df_3.info()
#sqlalchemy.create_engine() Function creation engine Two ways :
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://user:[email protected]/database?charset=utf8')
engine = create_engine('mysql+mysqlconnector:// user:[email protected]/database?charset=utf8')
#user:[email protected]/database --> The format is user name : password @ Server address / Database name
from sqlalchemy import create_engine
DB_STRING = 'mysql+mysqlconnector://user:[email protected]/database?charset=utf8'
engine = create_engine(DB_STRING)
data.to_sql(' Table name ',con = engine)
# It's used in mysql5.7 Version before , There is no problem , But in mysql8 After the version ,mysql8 Changed password encryption , An error will be prompted when using this method .
# In use to_sql write in mysql8 In the above version , Need to use mysqldb As a driver
# In the import pymysql You need to pymysql.install_as_MySQLdb() Can be used
import pymysql
pymysql.install_as_MySQLdb()
DB_STRING = 'mysql+mysqldb://user:[email protected]/db_name?charset=utf8'
engine = create_engine(DB_STRING)
data.to_sql(' Table name ',con = engine)
# Parameters dtype Usage method
#DATE,CHAR,VARCHAR… You can go to sqlalchemy View all of the official documents of sql data type : [‘TypeEngine’, ‘TypeDecorator’, ‘UserDefinedType’, ‘INT’, ‘CHAR’, ‘VARCHAR’, ‘NCHAR’, ‘NVARCHAR’, ‘TEXT’, ‘Text’, ‘FLOAT’, ‘NUMERIC’, ‘REAL’, ‘DECIMAL’, ‘TIMESTAMP’, ‘DATETIME’, ‘CLOB’, ‘BLOB’, ‘BINARY’, ‘VARBINARY’, ‘BOOLEAN’, ‘BIGINT’, ‘SMALLINT’, ‘INTEGER’, ‘DATE’, ‘TIME’, ‘String’, ‘Integer’, ‘SmallInteger’, ‘BigInteger’, ‘Numeric’, ‘Float’, ‘DateTime’, ‘Date’, ‘Time’, ‘LargeBinary’, ‘Binary’, ‘Boolean’, ‘Unicode’, ‘Concatenable’, ‘UnicodeText’, ‘PickleType’, ‘Interval’, ‘Enum’, ‘Indexable’, ‘ARRAY’, ‘JSON’] You can select the appropriate type to correspond to the database
from sqlalchemy.types import DATE,CHAR,VARCHAR
DTYPES = {
'col_1 Field name ' : DATE, 'col_2':CHAR(4),'col_3':VARCHAR(10)}
df.to_sql(' Table name ',con = engine,dtype = DTYPES)
# The... That will be written to the data table df in ,dtype Appoint According to the data type field corresponding to the column name
# perform SQL Statement to view the written database data
engine.execute("SELECT * FROM table_name").fetchall()
a_dict = {
' School ': ' Tsinghua University ',
' Location ': ' Beijing ',
' ranking ': 1
}
df = pd.json_normalize(a_dict) # Data in dictionary format is converted to DataFrame
df
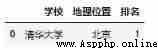
df = pd.DataFrame(a_dict, index = [0])# Data in dictionary format is converted to DataFrame
df
df = pd.DataFrame.from_dict(a_dict,orient='index')# Data in dictionary format is converted to DataFrame
df
data = {
'col_1': [1, 2, 3, 4],
'col_2': ['A', 'B', 'C', 'D']}
df = pd.DataFrame.from_dict(data, orient='columns')# Data in dictionary format is converted to DataFrame
df

df = pd.DataFrame.from_dict(data, orient='index')# Data in dictionary format is converted to DataFrame
df

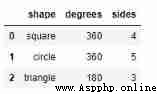
df = pd.DataFrame({
'shape': ['square', 'circle', 'triangle'],
'degrees': [360, 360, 180],
'sides': [4, 5, 3]})
df
# Output is dict
dict_out=df.to_dict(orient='dict')
dict_out
# Output
""" {'shape': {0: 'square', 1: 'circle', 2: 'triangle'}, 'degrees': {0: 360, 1: 360, 2: 180}, 'sides': {0: 4, 1: 5, 2: 3}} """
# Read
df=pd.DataFrame.from_dict(dict_out)
df
# result
""" shape degrees sides 0 square 360 4 1 circle 360 5 2 triangle 180 3 """
# Output is dict
dict_out=df.to_dict(orient='split')
dict_out
# Output
""" {'index': [0, 1, 2], 'columns': ['shape', 'degrees', 'sides'], 'data': [['square', 360, 4], ['circle', 360, 5], ['triangle', 180, 3]]} """
# Read
df=pd.DataFrame.from_dict(dict_out)
df
# result
""" index columns data 0 0 shape [square, 360, 4] 1 1 degrees [circle, 360, 5] 2 2 sides [triangle, 180, 3] """
# Output is dict
dict_out=df.to_dict(orient='list')
dict_out
# Output
""" {'shape': ['square', 'circle', 'triangle'], 'degrees': [360, 360, 180], 'sides': [4, 5, 3]} """
# Read
df=pd.DataFrame.from_dict(dict_out)
df
# result
""" shape degrees sides 0 square 360 4 1 circle 360 5 2 triangle 180 3 """
# Output is dict
dict_out=df.to_dict(orient='index')
dict_out
# Output
""" {0: {'index': 0, 'columns': 'shape', 'data': ['square', 360, 4]}, 1: {'index': 1, 'columns': 'degrees', 'data': ['circle', 360, 5]}, 2: {'index': 2, 'columns': 'sides', 'data': ['triangle', 180, 3]}} """
# Output is dict
dict_out=df.to_dict(orient='records')
dict_out
# Output
""" [{0: 0, 1: 1, 2: 2}, {0: 'shape', 1: 'degrees', 2: 'sides'}, {0: ['square', 360, 4], 1: ['circle', 360, 5], 2: ['triangle', 180, 3]}] """
pandas.read_json()
1) Parameters orient: Corresponding JSON The format of the string
2)split: The format is similar to :{index: [index], columns: [columns], data: [values]}
3)records: The format is similar to :[{column: value}, … , {column: value}]
4)index: The format is similar to :{index: {column: value}}
5)columns: The format is similar to :{column: {index: value}}
6)values: Array
split Format : The format is similar to :{index: [index], columns: [columns], data: [values]}
import pandas as pd
#split: The format is similar to :{index: [index], columns: [columns], data: [values]}
# For example, our JSON The string is so long
a='{"index":[1,2,3],"columns":["a","b"],"data":[[1,3],[2,8],[3,9]]}'
df = pd.read_json(a, orient='split')
df
# Output
""" a b 1 1 3 2 2 8 3 3 9 """
import pandas as pd
# For example, our JSON The string is so long
#records: The format is similar to :[{column: value}, ... , {column: value}]
# For example, our JSON The string is so long
a = '[{"name":"Tom","age":"18"},{"name":"Amy","age":"20"},{"name":"John","age":"17"}]'
df_1 = pd.read_json(a, orient='records')
df_1
# Output
""" name age 0 Tom 18 1 Amy 20 2 John 17 """
import pandas as pd
# For example, our JSON The string is so long
#index: {index: {column: value}}
# For example, our JSON The string is so long
a = '{"index_1":{"name":"John","age":20},"index_2":{"name":"Tom","age":30},"index_3":{"name":"Jason","age":50}}'
df_1 = pd.read_json(a, orient='index')
df_1
# Output
""" name age index_1 John 20 index_2 Tom 30 index_3 Jason 50 """
import pandas as pd
#columns: The format is similar to :{column: {index: value}}
a = '{"index_1":{"name":"John","age":20},"index_2":{"name":"Tom","age":30},"index_3":{"name":"Jason","age":50}}'
df_1 = pd.read_json(a, orient='columns')
df_1
# Output
""" index_1 index_2 index_3 name John Tom Jason age 20 30 50 """
import pandas as pd
#values: Array
# For example, our JSON The string is so long
v='[["a",1],["b",2],["c", 3]]'
df_1 = pd.read_json(v, orient="values")
df_1
# Output
""" 0 1 0 a 1 1 b 2 2 c 3 """
#!pip3 install lxml # For the first time read_html when , To be installed lxml package
from lxml import *
url = "https://www.runoob.com/python/python-exceptions.html"
dfs = pd.read_html(url, header=None, encoding='utf-8')# Return is a list
df=dfs[0]
df.head()
# Output
""" Exception name describe 0 NaN NaN 1 BaseException The base class for all exceptions 2 SystemExit The interpreter requests exit 3 KeyboardInterrupt User interrupt execution ( Usually the input ^C) 4 Exception Regular error base class """
import numpy as np
df = pd.DataFrame(np.random.randn(3, 3),columns=['A','B','C'])
df.to_html("test_1.html",index=False)
dfs = pd.read_html("test_1.html")
dfs[0]
# Output
""" A B C 0 -0.348165 -0.572741 -0.190966 1 0.700785 -0.848750 -1.853054 2 0.941161 -0.944569 0.749450 """
# Parameters filepath_or_buffer: Path of data input , It can be URL
#sep: Read csv The separator specified when the file is , Default to comma
#index_col: After we read the file , You can specify a column as DataFrame The index of
pd.read_csv(filepath_or_buffer='data.csv',index_col=0)
# Output
""" num1 num2 num3 num4 0 1 2 3 4 1 6 12 7 9 2 11 13 15 18 3 12 10 16 18 """
#index_col In addition to specifying a single column , We can also specify multiple columns
pd.read_csv(filepath_or_buffer='data.csv',index_col=['num1','num2'])
# Output
Unnamed: 0 num3 num4
num1 num2
1 2 0 3 4
6 12 1 7 9
11 13 2 15 18
12 10 3 16 18
#usecols: If there are many columns in the dataset , And we don't want all the columns 、 But as long as the specified column , You can use this parameter
#pd.read_csv('data.csv', usecols=[" Name 1", " Name 2", ....])
pd.read_csv('data.csv', usecols=["num1", "num2"])
# Output
num1 num2
0 1 2
1 6 12
2 11 13
3 12 10
#usecols In addition to specifying the column name , You can also select the desired column by index , The sample code is as follows
df = pd.read_csv("data.csv", usecols = [1, 2])
df
# Output
num1 num2
0 1 2
1 6 12
2 11 13
3 12 10
#usecols Parameter can receive a function , The column name is passed to the function as a parameter. , If the conditions are met , Select the column , Otherwise, the column is not selected
pd.read_csv("data.csv", usecols = lambda x:len(x)<5)
# Output
num1 num2 num3 num4
0 1 2 3 4
1 6 12 7 9
2 11 13 15 18
3 12 10 16 18
#prefix: When the imported data does not header When , Can be used to prefix column names
pd.read_csv("data.csv", prefix="test_", header = None)
# Output
test_0 test_1 test_2 test_3 test_4
0 NaN num1 num2 num3 num4
1 0.0 1 2 3 4
2 1.0 6 12 7 9
3 2.0 11 13 15 18
4 3.0 12 10 16 18
#skiprows: Filter out which lines , The index of the line filled in the parameter
pd.read_csv("data.csv", skiprows=[0, 1])
# The above code filters out the first two lines of data , Directly output the data of the third and fourth lines , You can see that the data in the second row is taken as the header
# Output
1 6 12 7 9
0 2 11 13 15 18
1 3 12 10 16 18
#nrows: This parameter sets the number of file lines read in at one time , Very useful for reading large files , such as 16G In memory PC Can't hold hundreds of G The large files
pd.read_csv("data.csv", nrows=2)
# Output
Unnamed:0 num1 num2 num3 num4
0 0 1 2 3 4
1 1 6 12 7 9
# This method is mainly used to DataFrame write in csv The file of , The sample code is as follows
df=pd.read_csv("data.csv", usecols = lambda x:len(x)<5)
df.to_csv(" file name .csv", index = False)
# We can also output to zip File format
df = pd.read_csv("data.csv")
compression_opts = dict(method='zip',
archive_name='output.csv')
df.to_csv('output.zip', index=False,
compression=compression_opts)
#! pip install xlrd # First execution read_excel when , Installation required xlrd package
#!pip install openpyxl # First execution read_excel when , Installation required openpyxl package
df = pd.read_excel("data.xlsx",engine='openpyxl') # because xlrd Package version problem , So you have to add engine='openpyxl'
df
# Output
Unnamed: 0 num1 num2 num3 num4
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18
#dtype: This parameter can set the data type of a specified column
df = pd.read_excel("data.xlsx",engine='openpyxl',dtype={
'Unnamed: 0': str, 'num1': float})
print(df.info())
df
# Output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 4 non-null object
1 num1 4 non-null float64
2 num2 4 non-null int64
3 num3 4 non-null int64
4 num4 4 non-null int64
dtypes: float64(1), int64(3), object(1)
memory usage: 288.0+ bytes
None
Unnamed: 0 num1 num2 num3 num4
0 0 1.0 2 3 4
1 1 6.0 12 7 9
2 2 11.0 13 15 18
3 3 12.0 10 16 18
#heet_name: For reading excel Which one of them sheet Set the data in
df = pd.read_excel("data.xlsx",engine='openpyxl', sheet_name="Sheet2")
df
# Output
Unnamed: 0 num5 num6 num7 num8
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18
# Of course, if we want to read more than one at a time Sheet The data is also OK , The last data returned is in dict The form returns
df = pd.read_excel("data.xlsx",engine='openpyxl',sheet_name=["Sheet1", "Sheet2"])
df
# Output
{
'Sheet1': Unnamed: 0 num1 num2 num3 num4
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18,
'Sheet2': Unnamed: 0 num5 num6 num7 num8
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18}
# For example, we just want Sheet1 The data of , have access to get function
df.get("Sheet1")
# Output
Unnamed: 0 num1 num2 num3 num4
0 0 1 2 3 4
1 1 6 12 7 9
2 2 11 13 15 18
3 3 12 10 16 18
# take DataFrame Object write Excel form , In addition to that ExcelWriter() Methods also have the same effect
df1 = pd.DataFrame([['A', 'B'], ['C', 'D']],
index=['Row 1', 'Row 2'],
columns=['Col 1', 'Col 2'])
df1.to_excel("output1.xlsx")
# Appoint Sheet The name of
df1.to_excel("output1.xlsx", sheet_name='Sheet_Name_1_1_1')
# Will be multiple DataFrame The dataset is output to a Excel The difference is Sheet among
df2 = df1.copy()
with pd.ExcelWriter('output2.xlsx') as writer:
df1.to_excel(writer, sheet_name='Sheet_name_1_1_1')
df2.to_excel(writer, sheet_name='Sheet_name_2_2_2')
# In the existing Sheet Based on , Add another Sheet
df3 = df1.copy()
with pd.ExcelWriter('output2.xlsx', mode="a", engine="openpyxl") as writer:
df3.to_excel(writer, sheet_name='Sheet_name_3_3_3')
#mode Parameters have w and a Two kinds of ,w Is overwrite write , Will cover the original Sheet,a It's append write append, Add a new one Sheet
# Can be generated to Excel File and compressed package processing
import zipfile
with zipfile.ZipFile("output_excel.zip", "w") as zf:
with zf.open("output_excel.xlsx", "w") as buffer:
with pd.ExcelWriter(buffer) as writer:
df1.to_excel(writer)
# For data in date format or date time format , It can also be processed accordingly
from datetime import date, datetime
df = pd.DataFrame(
[
[date(2019, 1, 10), date(2021, 11, 24)],
[datetime(2019, 1, 10, 23, 33, 4), datetime(2021, 10, 20, 13, 5, 13)],
],
index=["Date", "Datetime"],
columns=["X", "Y"])
df
# Output
X Y
Date 2019-01-10 00:00:00 2021-11-24 00:00:00
Datetime 2019-01-10 23:33:04 2021-10-20 13:05:13
# Store and write according to the date format
with pd.ExcelWriter(
"output_excel_date.xlsx",
date_format="YYYY-MM-DD",
datetime_format="YYYY-MM-DD HH:MM:SS"
) as writer:
df.to_excel(writer)
# Read data separated by spaces
import pandas as pd
df = pd.read_table('sentences.txt',header=None, encoding='utf8') #enconding='utf8' No overtime , Chinese will display garbled code
df
# Output
0
0 I love you China !
1 China is great , Peace of the motherland !
2 The people are happy !
from datetime import date, datetime
df = pd.DataFrame(
[
[date(2019, 1, 10), date(2021, 11, 24)],
[datetime(2019, 1, 10, 23, 33, 4), datetime(2021, 10, 20, 13, 5, 13)],
],
index=["Date", "Datetime"],
columns=["X", "Y"])
df.to_pickle('test.pkl')
df
# result
X Y
Date 2019-01-10 00:00:00 2021-11-24 00:00:00
Datetime 2019-01-10 23:33:04 2021-10-20 13:05:13
df2 = pd.read_pickle("test.pkl")
df2
# result
X Y
Date 2019-01-10 00:00:00 2021-11-24 00:00:00
Datetime 2019-01-10 23:33:04 2021-10-20 13:05:13
df=pd.read_clipboard()
df
# result
X Y
Date 2019-01-10 00:00:00 2021-11-24 00:00:00
Datetime 2019-01-10 23:33:04 2021-10-20 13:05:13
df.to_clipboard()
 Python sorts dictionaries. After sorting, it is still a dictionary. Whats wrong
Python sorts dictionaries. After sorting, it is still a dictionary. Whats wrong
python Sort the dictionary , D
 Pyspark reported an error org apache. spark. SparkException: Python worker failed to connect back.
Pyspark reported an error org apache. spark. SparkException: Python worker failed to connect back.
resolvent pycharm Configure en
 [web development] implement web server based on termux on Android mobile phones (Python, node.js, c/c++)
[web development] implement web server based on termux on Android mobile phones (Python, node.js, c/c++)
Web Server series related arti