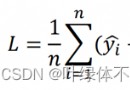要使用bs4,首先需要安裝對應的包
pip install beautifulsoup4
本質是通過html中的標簽、或者標簽中的屬性定位到其中的內容。這個過程可以重復多次,例如你可以找到一個較大范圍的唯一標簽,再在其中定位想要的內容。因此,它比正則表達式要容易上手得多,你只需要找對應標簽即可。
- find(標簽,屬性=值) 找到第一個符合的就停下,返回bs對象
- find_all(標簽,屬性=值) 找所有符合的,返回列表
- 因為find返回的是bs對象,所以可以繼續對其調用find直到找到為止。而find_all返回的是列表,一般只有最後一層才會用到它,然後通過列表取數據。
屬性的幾種寫法:
由於html部分標簽屬性的關鍵字跟python關鍵字是一樣的(例如class),直接寫這些屬性名會報python語法錯誤,因此bs4的屬性有兩種寫法可以避免這個問題。
前面我們通過正則表達式拿到了一部小說的所有url,這裡我們要做的就是讀取並循環請求這些url,然後用bs4匹配其中的小說文本內容。
隨便打開一章,查看源碼,看看文本內容在哪個標簽裡 我在仙宗當神獸[穿書] 網絡小說 - 第 142 章 一個大美人142 - 歸德讀書網
這裡很幸運的是div id="articlecon"這個屬性是唯一的,所以我們很方便就可以獲取到這塊內容。但是注意裡面並不全是文本,還有很多<p></p>標簽需要處理(後來發現這裡p標簽都是唯一的,但是這個例子太特殊,我們還是用div的標簽學習bs4用法)。
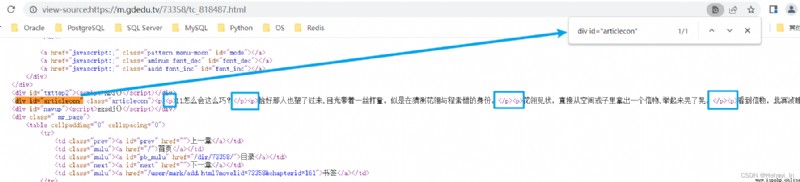
先拿一個鏈接,試著匹配div id="articlecon"部分內容
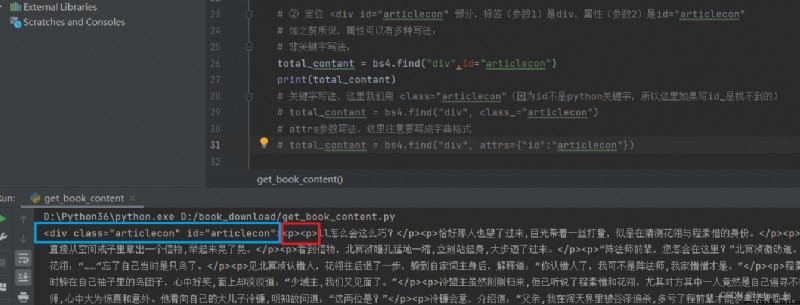
接下來的內容全在p標簽裡,因此要用find_all全部匹配出來。這裡注意它有兩層p標簽,所以還要先find一次p標簽。
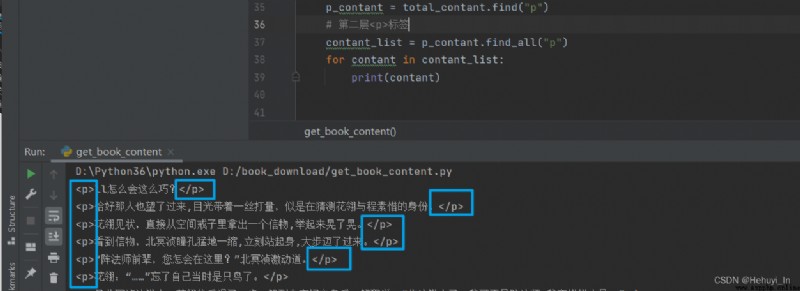
find_all返回一個列表,裡面每個元素是p標簽和其中的內容,如果只想要其中的內容,需要再調用getText函數。如果想要標簽中的屬性,則用 列表.get("href")。
例如 <a href=www.baidu.com>百度</a>
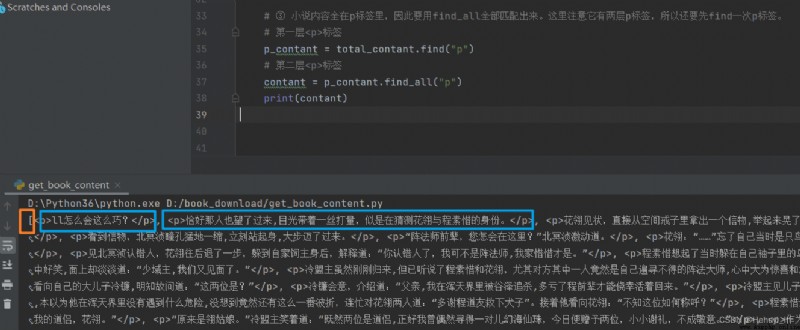
循環取出其中的內容,來看一下區別
直接輸出:
使用getText方法
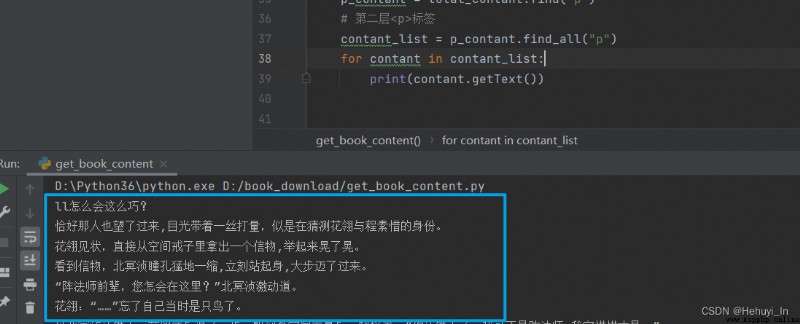
成功~~ 接下來把循環加上,就能輸出所有章節內容了
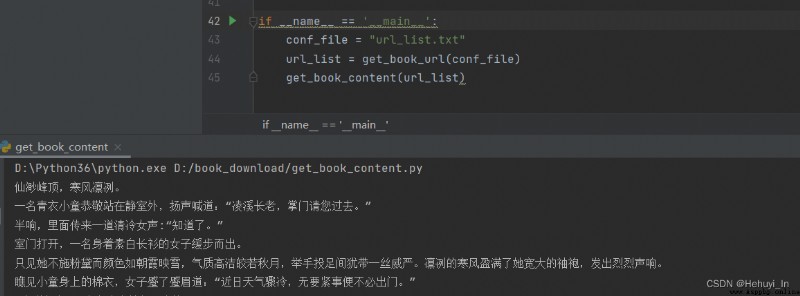
再來我們把輸出存到txt文件中,小說下載就大功告成了~
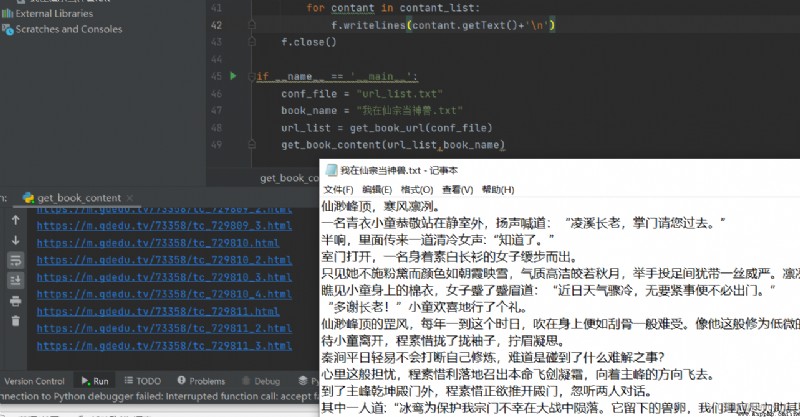
代碼如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2022-06-13 22:26
# @Author: Hehuyi_In
# @File : get_book_content.py
import requests
from bs4 import BeautifulSoup
def get_book_url(conf_file):
f = open(conf_file)
url_list = f.read().splitlines()
f.close()
return url_list
def get_book_content(url_list,book_name):
f = open(book_name, 'a', encoding='utf-8')
for url in url_list:
print(url)
resp = requests.get(url)
# ① 將頁面源碼(參數1)交給bs4處理,得到bs4對象;參數2說明傳入的是html,使用html.parser解析
bs4 = BeautifulSoup(resp.text,"html.parser")
# ② 定位 <div id="articlecon" 部分,標簽(參數1)是div,屬性(參數2)是id="articlecon"
# 如之前所說,屬性可以有多種寫法:
# 非關鍵字寫法:
total_contant = bs4.find("div",id="articlecon")
# print(total_contant)
# 關鍵字寫法,這裡我們用 class="articlecon"(因為id不是python關鍵字,所以這裡如果寫id_是找不到的)
# total_contant = bs4.find("div", class_="articlecon")
# attrs參數寫法,這裡注意要寫成字典格式
# total_contant = bs4.find("div", attrs={"id":"articlecon"})
# ③ 小說內容全在p標簽裡,因此要用find_all全部匹配出來。這裡注意它有兩層p標簽,所以還要先find一次p標簽。
# 第一層<p>標簽
p_contant = total_contant.find("p")
# 第二層<p>標簽
contant_list = p_contant.find_all("p")
for contant in contant_list:
f.writelines(contant.getText()+'\n')
f.close()
if __name__ == '__main__':
conf_file = "url_list.txt"
book_name = "我在仙宗當神獸.txt"
url_list = get_book_url(conf_file)
get_book_content(url_list,book_name)補兩個視頻中的截圖,暫時還沒測這兩個例子。一個抓表格數據,一個抓圖片。
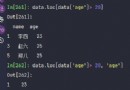
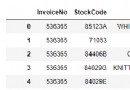
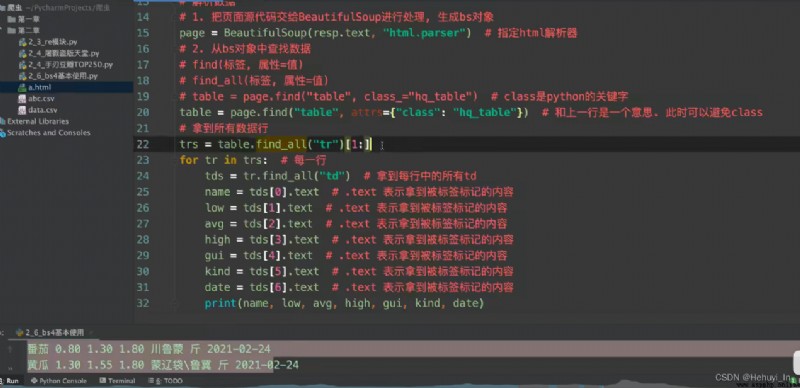
筆記-抓取表格數據
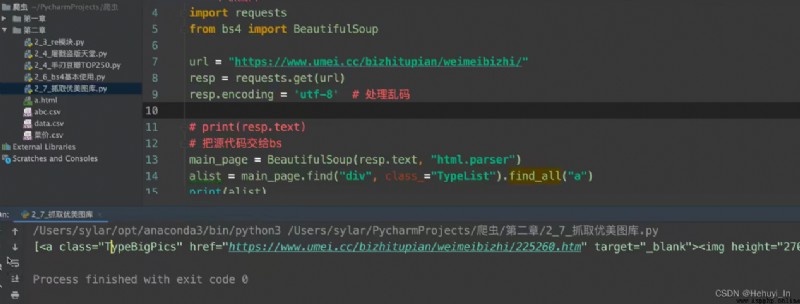
圖片抓取:進主頁,抓子頁面高清圖片
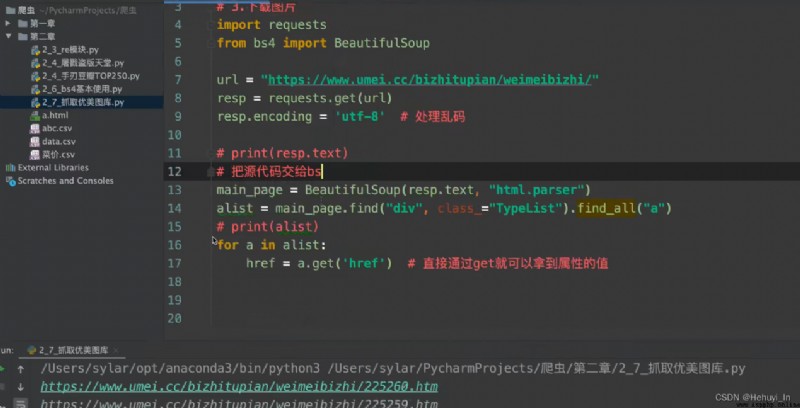
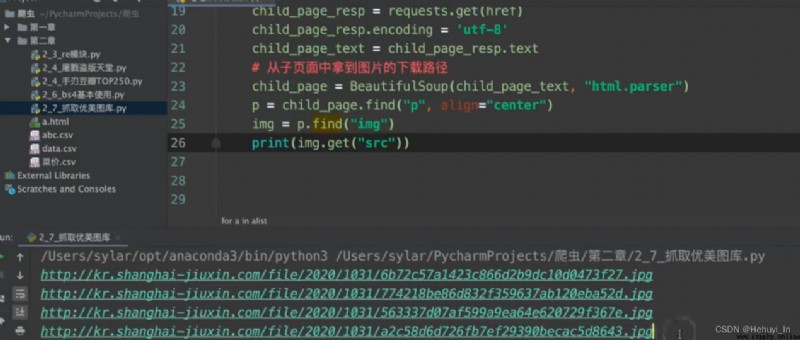
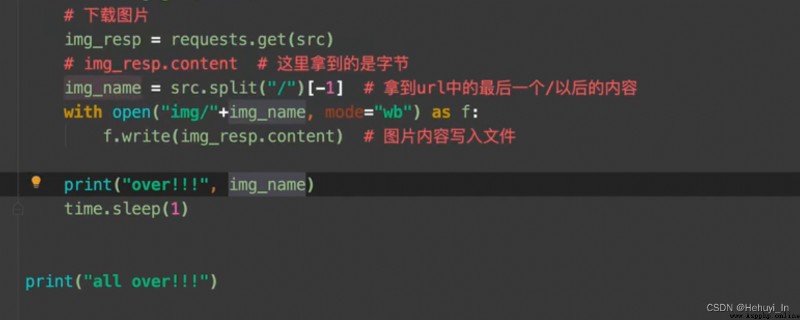
參考:B站視頻 P28-P32
2021年最新Python爬蟲教程+實戰項目案例(最新錄制)_哔哩哔哩_bilibili