版權聲明:此文章轉載自易極客(http://easygeek.com.cn/article/fYvqyq.Html)
如需轉載請聯系聽雲College團隊成員小尹 郵箱:yinhy#tingyun.com
Java內存模型規范了Java虛擬機與計算機內存是如何協同工作的,Java虛擬機是一個完整的計算機的一個模型,因此這個模型自然也包含一個內存模型——又稱為Java內存模型。如果你想設計表現良好的並發程序,理解Java內存模型是非常重要的。Java內存模型規定了如何和何時可以看到由其他線程修改過後的共享變量的值,以及在必須時如何同步的訪問共享變量。
原始的Java內存模型存在一些不足,因此Java內存模型在Java1.5時被重新修訂。這個版本的Java內存模型在Java8中人在使用。
Java內存模型把Java虛擬機內部劃分為線程棧和堆,這張圖演示了Java內存模型的邏輯視圖。

每一個運行在Java虛擬機裡的線程都擁有自己的線程棧,這個線程棧包含了這個線程調用的方法當前執行點相關的信息,一個線程僅能訪問自己的線程棧,一個線程創建的本地變量對其它線程不可見,僅自己可見。即使兩個線程執行同樣的代碼,這兩個線程依然使用自己的線程棧中的代碼來創建本地變量。因此,每個線程擁有每個本地變量的獨有版本。
所有原始類型的本地變量都存放在線程棧上,因此對其它線程不可見。一個線程可能向另一個線程傳遞一個原始類型變量的拷貝,但是它不能共享這個原始類型變量自身。堆上包含在Java程序中創建的所有對象,無論是哪一個對象創建的,這包括原始類型的對象版本。如果一個對象被創建然後賦值給一個局部變量,或者用來作為另一個對象的成員變量,這個對象任然是存放在堆上。
下面這張圖演示了調用棧和本地變量存放在線程棧上,對象存放在堆上。

一個本地變量可能是原始類型,在這種情況下,它總是“呆在”線程棧上。一個本地變量也可能是指向一個對象的一個引用,在這種情況下,引用(這個本地變量)存放在線程棧上,但是對象本身存放在堆上。一個對象可能包含方法,這些方法可能包含本地變量,這些本地變量任然存放在線程棧上,即使這些方法所屬的對象存放在堆上。一個對象的成員變量可能隨著這個對象自身存放在堆上,不管這個成員變量是原始類型還是引用類型。
靜態成員變量跟隨著類定義一起也存放在堆上,存放在堆上的對象可以被所有持有對這個對象引用的線程訪問。當一個線程可以訪問一個對象時,它也可以訪問這個對象的成員變量。如果兩個線程同時調用同一個對象上的同一個方法,它們將會都訪問這個對象的成員變量,但是每一個線程都擁有這個本地變量的私有拷貝。
下圖演示了上面提到的點:

兩個線程擁有一些列的本地變量,其中一個本地變量(Local Variable 2)執行堆上的一個共享對象(Object 3),這兩個線程分別擁有同一個對象的不同引用,這些引用都是本地變量,因此存放在各自線程的線程棧上,這兩個不同的引用指向堆上同一個對象。注意,這個共享對象(Object 3)持有Object2和Object4一個引用作為其成員變量(如圖中Object3指向Object2和Object4的箭頭),通過在Object3中這些成員變量引用,這兩個線程就可以訪問Object2和Object4。
這張圖也展示了指向堆上兩個不同對象的一個本地變量。在這種情況下,指向兩個不同對象的引用不是同一個對象,理論上兩個線程都可以訪問Object1和Object5,如果兩個線程都擁有兩個對象的引用。但是在上圖中,每一個線程僅有一個引用指向兩個對象其中之一。因此,什麼類型的Java代碼會導致上面的內存圖呢?如下所示:
public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
int localVariable1 = 45;
MySharedObject localVariable2 =
MySharedObject.sharedInstance;
//... do more with local variables.
methodTwo();
}
public void methodTwo() {
Integer localVariable1 = new Integer(99);
//... do more with local variable.
}
}
public class MySharedObject {
//static variable pointing to instance of MySharedObject
public static final MySharedObject sharedInstance =
new MySharedObject();
//member variables pointing to two objects on the heap
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
public long member1 = 12345;
public long member1 = 67890;
}
methodOne()聲明了一個原始類型的本地變量和一個引用類型的本地變量,如果兩個線程同時執行run()方法,就會出現上圖所示的情景,run()方法調用methodOne()方法,methodOne()調用methodTwo()方法。每個線程執行methodOne()都會在它們對應的線程棧上創建localVariable1和localVariable2的私有拷貝。localVariable1變量彼此完全獨立,僅“生活”在每個線程的線程棧上。一個線程看不到另一個線程對它的localVariable1私有拷貝做出的修改。
每個線程執行methodOne()時也將會創建它們各自的localVariable2拷貝。然而,兩個localVariable2的不同拷貝都指向堆上的同一個對象。代碼中通過一個靜態變量設置localVariable2指向一個對象引用。僅存在一個靜態變量的一份拷貝,這份拷貝存放在堆上。因此,localVariable2的兩份拷貝都指向由MySharedObject指向的靜態變量的同一個實例。MySharedObject實例也存放在堆上。它對應於上圖中的Object3。
注意,MySharedObject類也包含兩個成員變量,這些成員變量隨著這個對象存放在堆上,這兩個成員變量指向另外兩個Integer對象,這些Integer對象對應於上圖中的Object2和Object4。
注意,methodTwo()創建一個名為localVariable的本地變量。這個成員變量是一個指向一個Integer對象的對象引用。這個方法設置localVariable1引用指向一個新的Integer實例。在執行methodTwo方法時,localVariable1引用將會在每個線程中存放一份拷貝。這兩個Integer對象實例化將會被存儲堆上,但是每次執行這個方法時,這個方法都會創建一個新的Integer對象,兩個線程執行這個方法將會創建兩個不同的Integer實例。methodTwo方法創建的Integer對象對應於上圖中的Object1和Object5。
還有一點,MySharedObject類中的兩個long類型的成員變量是原始類型的。因為,這些變量是成員變量,所以它們任然隨著該對象存放在堆上,僅有本地變量存放在線程棧上。
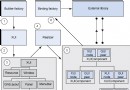
現代硬件內存模型與Java內存模型有一些不同。理解內存模型架構以及Java內存模型如何與它協同工作也是非常重要的。這部分描述了通用的硬件內存架構,下面的部分將會描述Java內存是如何與它“聯手”工作的。下面是現代計算機硬件架構的簡單圖示:
enter image description here
一個現代計算機通常由兩個或者多個CPU,其中一些CPU還有多核。從這一點可以看出,在一個有兩個或者多個CPU的現代計算機上同時運行多個線程是可能的。每個CPU在某一時刻運行一個線程是沒有問題的。這意味著,如果你的Java程序是多線程的,在你的Java程序中每個CPU上一個線程可能同時(並發)執行。每個CPU都包含一系列的寄存器,它們是CPU內內存的基礎。CPU在寄存器上執行操作的速度遠大於在主存上執行的速度。這是因為CPU訪問寄存器的速度遠大於主存。每個CPU可能還有一個CPU緩存層。實際上,絕大多數的現代CPU都有一定大小的緩存層。CPU訪問緩存層的速度快於訪問主存的速度,但通常比訪問內部寄存器的速度還要慢一點。一些CPU還有多層緩存,但這些對理解Java內存模型如何和內存交互不是那麼重要。只要知道CPU中可以有一個緩存層就可以了。一個計算機還包含一個主存。所有的CPU都可以訪問主存。主存通常比CPU中的緩存大得多。
通常情況下,當一個CPU需要讀取主存時,它會將主存的部分讀到CPU緩存中。它甚至可能將緩存中的部分內容讀到它的內部寄存器中,然後在寄存器中執行操作。當CPU需要將結果寫回到主存中去時,它會將內部寄存器的值刷新到緩存中,然後在某個時間點將值刷新回主存。當CPU需要在緩存層存放一些東西的時候,存放在緩存中的內容通常會被刷新回主存。CPU緩存可以在某一時刻將數據局部寫到它的內存中,和在某一時刻局部刷新它的內存。它不會再某一時刻讀/寫整個緩存。通常,在一個被稱作“cache lines”的更小的內存塊中緩存被更新。一個或者多個緩存行可能被讀到緩存,一個或者多個緩存行可能再被刷新回主存。

上面已經提到,Java內存模型與硬件內存架構之間存在差異。硬件內存架構沒有區分線程棧和堆。對於硬件,所有的線程棧和堆都分布在主內中。部分線程棧和堆可能有時候會出現在CPU緩存中和CPU內部的寄存器中。如下圖所示:
enter image description here
當對象和變量被存放在計算機中各種不同的內存區域中時,就可能會出現一些具體的問題。主要包括如下兩個方面:
1、線程對共享變量修改的可見性-當讀,2、寫和檢查共享變量時出現race conditions
下面我們專門來解釋以下這兩個問題。
共享對象可見性
如果兩個或者更多的線程在沒有正確的使用volatile聲明或者同步的情況下共享一個對象,一個線程更新這個共享對象可能對其它線程來說是不接見的。想象一下,共享對象被初始化在主存中。跑在CPU上的一個線程將這個共享對象讀到CPU緩存中。然後修改了這個對象。只要CPU緩存沒有被刷新會主存,對象修改後的版本對跑在其它CPU上的線程都是不可見的。這種方式可能導致每個線程擁有這個共享對象的私有拷貝,每個拷貝停留在不同的CPU緩存中。
下圖示意了這種情形。跑在左邊CPU的線程拷貝這個共享對象到它的CPU緩存中,然後將count變量的值修改為2。這個修改對跑在右邊CPU上的其它線程是不可見的,因為修改後的count的值還沒有被刷新回主存中去。

解決這個問題你可以使用Java中的volatile關鍵字。volatile關鍵字可以保證直接從主存中讀取一個變量,如果這個變量被修改後,總是會被寫回到主存中去。
Race Conditions
如果兩個或者更多的線程共享一個對象,多個線程在這個共享對象上更新變量,就有可能發生race conditions。想象一下,如果線程A讀一個共享對象的變量count到它的CPU緩存中。再想象一下,線程B也做了同樣的事情,但是往一個不同的CPU緩存中。現在線程A將count加1,線程B也做了同樣的事情。現在count已經被增在了兩個,每個CPU緩存中一次。如果這些增加操作被順序的執行,變量count應該被增加兩次,然後原值+2被寫回到主存中去。然而,兩次增加都是在沒有適當的同步下並發執行的。無論是線程A還是線程B將count修改後的版本寫回到主存中取,修改後的值僅會被原值大1,盡管增加了兩次。下圖演示了上面描述的情況:

解決這個問題可以使用Java同步塊。一個同步塊可以保證在同一時刻僅有一個線程可以進入代碼的臨界區。同步塊還可以保證代碼塊中所有被訪問的變量將會從主存中讀入,當線程退出同步代碼塊時,所有被更新的變量都會被刷新回主存中去,不管這個變量是否被聲明為volatile。