引言
NetMind BeanKeeper 是一個開源的 java 對象 / 關系數據庫映 射框架,它可以幫助用戶快速將對象保存到關系數據庫中,同時它也支持自定義 地查詢和事務,可以滿足用戶在各種應用場景的需求。它最大的特點就是簡單, 無需配置。同時,它是純 Java 的,也支持 HSQLDB 和 MySQL 等多種關系數據庫。本文將介紹 BeanKeeper 的基本原理和架構,並將其同 Hibernate、Spring 等其他框架進行比較,總結其主要優點。最後將演示一個案例介紹如何借助 BeanKeeper 快捷地實現將 Java 對象保存到關系數據庫中。
BeanKeeper 的架構
對象持久性幾乎是所有 Java™ 應用程序( 從桌面應用程序到企業級應用程序)中的必備,持久性的缺點是它一直都不太簡 單。
面向對象的開發方法是當今企業級應用開發環境中的主流開發方法 ,關系數據庫是企業級應用環境中永久存放數據的主流數據存儲系統。對象和關 系數據是業務實體的兩種表現形式,業務實體在內存中表現為對象,在數據庫中 表現為關系數據。內存中的對象之間存在關聯和繼承關系,而在數據庫中,關系 數據無法直接表達多對多關聯和繼承關系。因此,需要 ORM(Object Relational Mapping)實現程序對象到關系數據庫數據的映射。
由於關 系數據庫是目前最流行的存儲系統,因此要將對象持久化到關系數據庫中,我們 就要解決 ORM 的問題。目前主流的 ORM 框架有:Spring、Hibernate 等框架。 它們都存在一個問題是:太復雜了。要利用這些框架進行對象持久化,開發人員 首先要閱讀幾百頁的文檔以了解如何使用這些框架,然後又要編寫 XML 配置映 射文件以告訴框架如果和進行 ORM。而且一旦對象模型發生改變後又要修改映射 文件。這些都極大地增加了開發人員的學習曲線和工作量,同時也容易出錯。而 Bean keeper 的理念是簡單的事情簡單做,它盡量簡化這些操作。
Bean Keeper 是一個基於 LGPL 協議的開源軟件,它具有如下特性:
使用簡單,你只需要學習 3 個借口就可以基本掌握其使用方法 ;
零配置。除了數據庫的連接 URL 外。你不需要其他配置 ;
可擴展性,這個類庫支持分布式操作,可以將您的數據進行多拷貝存儲和負 載平衡 ;
100% 地透明地支持 List、Map、Set 等集合 ;
自動分頁大數據集。分頁是 100% 透明地,包含百萬條記錄的數據集可以直 接地給表現層,而不用擔心內存和數據庫負載的問題 ;
自定義的面向對象的查詢語言,用戶不需要編寫復雜的 SQL 語句 ;
各種數據庫間的可移植性。BeanKeeper 屏蔽了各類數據庫之間的差異,比如 對 Null 值的處理,空字符串 (Oracle),查詢時大小寫敏感,保留字等差異。 這就意味著你可以更改底層的數據庫 ;
對事務的支持,能夠實現事務的提交和回滾。
下載 BeanKeeper
BeanKeeper 的安裝過程很簡單。首先,訪問 BeanKeeper 站點下載 Jar 包 。目前最新的發布版本是 2.6.0。本文中所有示例也是基於此版本。
BeanKeeper 是基於 LGPL 協議的,你可以在你的商業軟件中商業軟件通過類 庫引用 (link) 方式使用它而不需要開源商業軟件的代碼。但是如果修改它的代 碼或者衍生,則所有修改的代碼,涉及修改部分的額外代碼和衍生的代碼都必須 采用 LGPL 協議。
圖 1. BeanKeeper 目前版本

此外 BeanKeeper 還依賴於下列類庫::
commons-lang-2.4.jar
commons-io-1.4.jar
commons-logging.jar
commons-collections-3.2.1.jar
commons-configuration-1.6.jar
log4j-1.2.15.jar
在本例中,我們使用的是 MySQL 數據庫來持久化數據,所以我們還需要下載 MySQL 的 JDBC 驅動:
mysql-connector-java-5.0.8-bin.jar
保存對象
在本章中,我們將演示一個案例介紹如何利用 BeanKeeper 將員工 (Employee) 信息持久化到 MySQL 數據庫中。首先從 CSV 文件中一條條讀出員 工信息,然後將這些信息生成一個 EmployeeBean 對象,然後將 EmployeeBean 對象持久化。
首先我們需要定義一個“類似 JavaBean”類,那麼“類似 JavaBean”是什 麼意思呢?真正的 JavaBeans 是一些可視組件,可以在開發環境中配置它們以 便在 GUI 布局中使用。一些用真正的 JavaBeans 開始的慣例在 Java 社區中已 經變得非常普及,尤其是對於數據類。如果一個類遵守下列慣例,我就稱其為“ 類似 JavaBean”:
該類是公共的
它定義了一個公共的缺省(無參數)構造函數
它定義了公共的 getX 和 setX 方法用來訪問屬性(數據)值
既然技術上的定義不成問題,在談及這些“類似 JavaBean”類的其中一個時 ,我將跳過所有這些,並只稱呼它為“bean”類。
如下表所示,我們定義了一個 EmployeeBean 類,類中包含員工 id,姓名, 年齡,入職年月信息。
清單 1. EmployeeBean 類
package cn.ac.iscas.beankeeper.sample;
import java.util.Date;
public class EmployeeBean {
String id;
String name;
int age;
Date onBoardTime;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Date getOnBoardTime() {
return onBoardTime;
}
public void setOnBoardTime(Date onBoardTime) {
this.onBoardTime = onBoardTime;
}
}
接下來存儲 EmployeeBean 對象到數據庫中。首先從 CSV 文件中一條條讀出 員工信息,然後將這些信息生成一個 EmployeeBean 對象,最後將 EmployeeBean 對象持久化到數據庫。
清單 2. 保存 EmployeeBean 對象代碼
package cn.ac.iscas.beankeeper.sample;
import hu.netmind.persistence.Store;
import java.io.File;
import java.sql.Date;
import java.util.List;
import org.apache.commons.io.FileUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class EmployeeSave {
private static Log log;
/**
* @param args
*/
public static void main(String[] args) {
System.setProperty("log4j.configuration", "file:log4j.xml");
log = LogFactory.getLog(EmployeeBean.class);
try {
String csvFile = args[0];
// open store, uses MySQL driver
Store store = new Store ("org.gjt.mm.mysql.Driver",
"jdbc:mysql://localhost:3306/lhq?user=root&password=sa");
// read csv and generate beans
List historicalData = FileUtils.readLines(new File(csvFile));
// remove first line (header)
historicalData.remove(0);
// store beans to database
for (Object _data : historicalData) {
String[] data = ((String) _data).split (",");
EmployeeBean bean = new EmployeeBean();
bean.setId(data[0]);
bean.setName(data[1]);
bean.setAge(Integer.parseInt(data[2]));
bean.setOnBoardTime(Date.valueOf(data [3]));
// save stock bean to database
store.save(bean);
}
} catch (Exception e) {
log.error(e.getMessage(), e);
system.out.println("Usage: java sample.StockData "
+ "<symbol name> <historical prices file> <query>");
}
}
}
從上面的代碼我們可以看出,事實上持久化一個對象的過程非常簡單,我們 只需要首先實例化一個 Store 對象
Store store = new Store("org.gjt.mm.mysql.Driver",
"jdbc:mysql://localhost:3306/lhq? user=root&password=sa");
然後直接調用 store 的 save() 方法
store.save(bean);
這樣一個 bean 對象就被存儲到數據庫中了,具體如何實現 ORM 映射對用戶 來說是透明的,用戶不用關心對象的哪一個屬性對應到了數據庫表的哪一列。讀 者要是對 BeanKeeper 的後台實現比較感興趣,可以查看 MySQL 數據庫。
圖 2. 數據庫中生成的表

如圖 2 所示,BeanKeeper 在數據中生成了四張表:classes 表, employeebean 表,nodes 表和 tablemap 表。其中,classes 表和 tablemap 表保存了 Java 類到表名的映射信息,
圖 3.classes 表

圖 4.tablemap 表
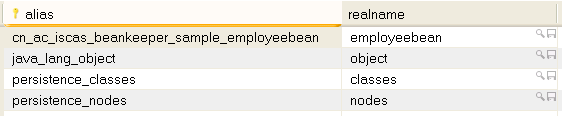
從圖 3 和圖 4 我們可以看到, cn.ac.iscas.beankeeper.sample.EmployeeData 類的對象被保存到了 employeebean 表中。
打開 employeebean 表 ( 圖 5) 我們可以看到,員工對象的各個屬性都已經 保存到表中。
圖 5.employeebean 表
查詢對象
接下來我們介紹如何從數據庫中查詢出對象。例如我們要找出所有小於 30 歲的,2005 年之後入職的員工,同時以工號進行排序。
清單 3. 查詢示例代碼
String query="find EmployeeBean where age<30 and onBoardTime>='2005-01-01' order by id";
Store store = new Store("org.gjt.mm.mysql.Driver",
"jdbc:mysql://localhost:3306/lhq?user=root&password=sa");
List<EmployeeBean> emps = store.find(query);
for(EmployeeBean emp:emps)
System.out.println(emp.getName());
BeanKeeper 查詢接口有四個:
find(String statement)
find(String statement, Object[] parameters)
findSingle(String statement)
findSingle(String statement, Object[] parameters)
其中 find 返回的是所有滿足條件的對象的集合 (List),List 接口的具體 實現類是 LazyList,它具有自動分頁的功能,所以即使返回的結果中包含上百 萬條記錄,你也不用擔心內存和數據庫負載的問題,他會自動地處理。除此之外 ,它還提供了 size() 方法,可以返回查詢結果的總記錄條數。
findSingle 方法返回單個對象,當查詢到第一個滿足條件的記錄後,即停止 查詢,返回結果。
事務控制
事務指的是一系列原子的數據庫操作,在我們的上下文中指的是對象操作。 這一些操作要麼是所有操作都成功完成,事務完成提交;要麼是某一操作失敗, 數據回滾到事務開始前的狀態。
BeanKeeper 目前只支持用戶管理的事務界限劃分,這就意味著你要指定事務 的開始和事務的結束。即使你不顯示地定義事務,事務其實也是隱含地存在的, 因為你對 store 的每個操作(比如 save() 和 remove() 方法)都會隱式地創 建一個事務,如果這個操作的某一環節出現了錯誤,這個事務將會回滾。
事務跟蹤器(Transaction tracker)負責管理應用中的所有事務。如果你想 跟蹤事務的提交和回滾事件,你可以給事務跟蹤器添加監聽器,這樣當提交和回 滾操作進行時你將可以得到通知。
TransactionListener 接口包括兩個方法:
void transactionCommited(Transaction transaction);
void transactionRolledback(Transaction transaction);
注意:這些方法得到觸發這個事件的事務對象時,這些事務已經結束了,所 以你不能利用它們去執行操作。同樣地,當你從跟蹤器中獲取到事務對象,並執 行某些數據庫相關的操作時,為避免形成死循環,此時跟蹤器中的事件將不會再 被觸發。
清單 4. 添加事務監聽器代碼
TransactionTracker tt= store.getTransactionTracker();
tt.addListener(new TransactionListener(){
@Override
public void transactionCommited(Transaction transaction) {
System.out.println("Transaction Commited");
}
@Override
public void transactionRolledback(Transaction transaction) {
System.out.println("Transaction Rolledback");
}
});
結束語
通過上文介紹,我們可以看出借助 NetMind BeanKeeper,我們不需要任何配 置,只需使用 BeanKeeper 的三個接口便可實現將對象保存到關系數據庫中,相 對於 Hibernate 等框架要簡單得多。同時它也支持復雜的查詢和事務功能,可 滿足大部分應用場景的需要。
原文地址:http://www.ibm.com/developerworks/cn/java/j-lo- beankeeper/index.html