在 上一部分 中,您了解到如何編寫一個 spider 程序來進行網頁的爬取, 作為 spider 的爬取結果,我們獲得了一個按照一定格式存儲的原始網頁庫,原 始網頁庫也是我們第二部分網頁預處理的數據基礎。網頁預處理的主要目標是將 原始網頁通過一步步的數據處理變成可方便搜索的數據形式。下面就讓我們逐步 介紹網頁預處理的設計和實現。
預處理模塊的整體結構
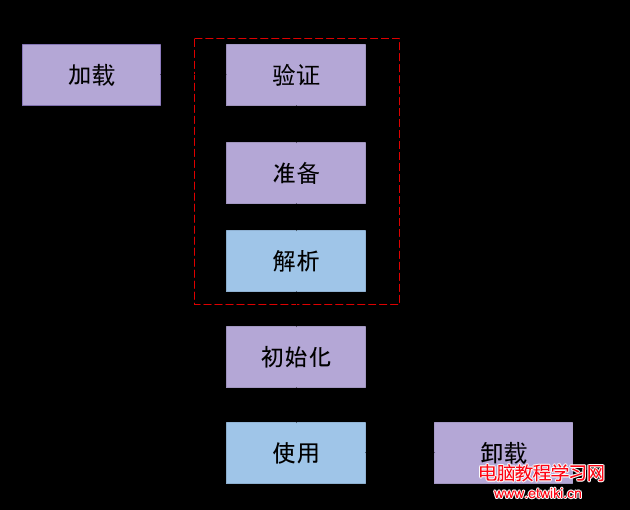
預處理模塊的整體結構如下:
圖 1. 預處理模塊的整體結構
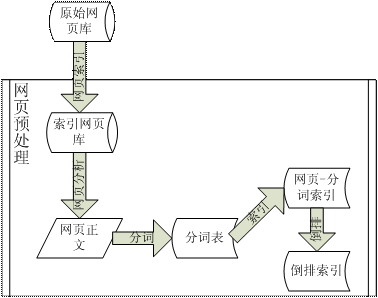
通過 spider 的收集,保存下來的網頁信息具有較好的信息存儲格式,但是 還是有一個缺點,就是不能按照網頁 URL 直接定位到所指向的網頁。所以,在 第一個流程中,需要先建立網頁的索引,如此通過索引,我們可以很方便的從原 始網頁庫中獲得某個 URL 對應的頁面信息。之後,我們處理網頁數據,對於一 個網頁,首先需要提取其網頁正文信息,其次對正文信息進行分詞,之後再根據 分詞的情況建立索引和倒排索引,這樣,網頁的預處理也全部完成。可能讀者對 於其中的某些專業術語會有一些不明白之處,在後續詳述各個流程的時候會給出 相應的圖或者例子來幫助大家理解。
建立索引網頁庫
原始網頁庫是按照格式存儲的,這對於網頁的索引建立提供了方便,下圖給 出了一條網頁信息記錄:
清單 1. 原始網頁庫中的一條網頁記錄
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx // 之前的記錄
version:1.0 // 記錄頭部
url:http://ast.nlsde.buaa.edu.cn/
date:Mon Apr 05 14:22:53 CST 2010
IP:218.241.236.72
length:3981
<!DOCTYPE …… // 記錄數據部分
<html> …… </html>
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx // 之後的記錄
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
我們采用“網頁庫名—偏移”的信息對來定位庫中的某條網頁記錄。由於數 據量比較大,這些索引網頁信息需要一種保存的方法,dySE 使用數據庫來保存 這些信息。數據庫們采用 mysql,配合 SQL-Front 軟件可以輕松進行圖形界面 的操作。我們用一個表來記錄這些信息,表的內容如下:url、content、offset 、raws。URL 是某條記錄對應的 URL,因為索引數據庫建立之後,我們是通過 URL 來確定需要的網頁的;raws 和 offset 分別表示網頁庫名和偏移值,這兩 個屬性唯一確定了某條記錄,content 是網頁內容的摘要,網頁的數據量一般較 大,把網頁的全部內容放入數據庫中顯得不是很實際,所以我們將網頁內容的 MD5 摘要放入到 content 屬性中,該屬性相當於一個校驗碼,在實際運用中, 當我們根據 URL 獲得某個網頁信息是,可以將獲得的網頁做 MD5 摘要然後與 content 中的值做一個匹配,如果一樣則網頁獲取成功,如果不一樣,則說明網 頁獲取出現問題。
這裡簡單介紹一下 mySql 的安裝以及與 Java 的連接:
安裝 mySql,最好需要三個組件,mySql,mySql-front,mysql-connector- java-5.1.7-bin.jar,分別可以在網絡中下載。注意:安裝 mySql 與 mySql- front 的時候要版本對應,MySql5.0 + MySql-Front3.2 和 MySql5.1 + MySql -Front4.1,這個組合是不能亂的,可以根據相應的版本號來下載,否則會爆“ ‘ 10.000000 ’ ist kein gUltiger Integerwert ”的錯誤。
導入 mysql-connector-java-5.1.7-bin.jar 到 eclipse 的項目中,打開 eclipse,右鍵點需要導入 jar 包的項 目名,選屬性(properties),再選 java 構建路徑(java Build Path),後在右側點 (libraries),選 add external JARs,之後選擇你要導入的 jar 包確定。
接著就可以用代碼來測試與 mySql 的連接了,代碼見本文附帶的 testMySql.java 程序,這裡限於篇幅就不在贅述。
對於數據庫的操作,我們最好進行一定的封裝,以提供統一的數據庫操作支 持,而不需要在其他的類中顯示的進行數據庫連接操作,而且這樣也就不需要建 立大量的數據庫連接從而造成資源的浪費,代碼詳見 DBConnection.java。主要 提供的操作是:建立連接、執行 SQL 語句、返回操作結果。
介紹了數據庫的相關操作時候,現在我們可以來完成網頁索引庫的建立過程 。這裡要說明的是,第一條記錄的偏移是 0,所以在當前記錄 record 處理之前 ,該記錄的偏移是已經計算出來的,處理 record 的意義在於獲得下一個記錄在 網頁庫中的偏移。假設當前 record 的偏移為 offset,定位於頭部的第一條屬 性之前,我們通過讀取記錄的頭部和記錄的數據部分來得到該記錄的長度 length,從而,offset+length 即為下一條記錄的偏移值。讀取頭部和讀取記錄 都是通過數據間的空行來標識的,其偽代碼如下:
清單 2. 索引網頁庫建立
For each record in Raws do
begin
讀取 record 的頭部和數據,從頭部中抽取 URL;
計算頭部和數據的長度,加到當前偏移值上得到新的偏移;
從 record 中數據中計算其 MD5 摘要值;
將數據插入數據庫中,包括:URL、偏移、數據 MD5 摘要、Raws;
end;
您可能會對 MD5 摘要算法有些疑惑,這是什麼?這有什麼用? Message Digest Algorithm MD5(中文名為消息摘要算法第五版)為計算機安全領域廣泛 使用的一種散列函數,用以提供消息的完整性保護。MD5 的典型應用是對一段信 息 (Message) 產生一個 128 位的二進制信息摘要 (Message-Digest),即為 32 位 16 進制數字串,以防止被篡改。對於我們來說,比如通過 MD5 計算,某個 網頁數據的摘要是 00902914CFE6CD1A959C31C076F49EA8,如果我們任意的改變 這個網頁中的數據,通過計算之後,該摘要就會改變,我們可以將信息的 MD5 摘要視作為該信息的指紋信息。所以,存儲該摘要可以驗證之後獲取的網頁信息 是否與原始網頁一致。
對 MD5 算法簡要的敘述可以為:MD5 以 512 位分組來處理輸入的信息,且 每一分組又被劃分為 16 個 32 位子分組,經過了一系列的處理後,算法的輸出 由四個 32 位分組組成,將這四個 32 位分組級聯後將生成一個 128 位散列值 。其中“一系列的處理”即為計算流程,MD5 的計算流程比較多,但是不難,同 時也不難實現,您可以直接使用網上現有的 java 版本實現或者使用本教程提供 的源碼下載中的 MD5 類。對於 MD5,我們知道其功能,能使用就可以,具體的 每個步驟的意義不需要深入理解。
正文信息抽取
PageGetter
在正文信息抽取之前,我們首先需要一個簡單的工具類,該工具類可以取出 數據庫中的內容並且去原始網頁集中獲得網頁信息,dySE 對於該功能的實現在 originalPageGetter.java 中,該類通過 URL 從數據庫中獲得該 URL 對應的網 頁數據的所在網頁庫名以及偏移,然後就可以根據偏移來讀取該網頁的數據內容 ,同樣以原始網頁集中各記錄間的空行作為數據內容的結束標記,讀取內容之後 ,通過 MD5 計算當前讀取的內容的摘要,校驗是否與之前的摘要一致。對於偏 移的使用,BufferedReader 類提供一個 skip(int offset) 的函數,其作用是 跳過文檔中,從當前開始計算的 offset 個字符,用這個函數我們就可以定位到 我們需要的記錄。
清單 3. 獲取原始網頁庫中內容
public String getContent(String fileName, int offset)
{
String content = "";
try {
FileReader fileReader = new FileReader(fileName);
BufferedReader bfReader = new BufferedReader (fileReader);
bfReader.skip(offset);
readRawHead(bfReader);
content = readRawContent(bfReader);
} catch (Exception e) {e.printStackTrace();}
return content;
}
上述代碼中,省略了 readRawHead 和 readRawContent 的實現,這些都是基 本的 I/O 操作,詳見所附源碼。
正文抽取
對於獲得的單個網頁數據,我們就可以進行下一步的處理,首先要做的就是 正文內容的抽取,從而剔除網頁中的標簽內容,這一步的操作主要采用正則表達 式來完成。我們用正則表達式來匹配 html 的標簽,並且把匹配到的標簽刪除, 最後,剩下的內容就是網頁正文。限於篇幅,我們以過濾 script 標簽為示例, 其代碼如下 :
清單 4. 標簽過濾
public String html2Text(String inputString) {
String htmlStr = inputString; // 含 html 標簽的字 符串
Pattern p_script; Matcher m_script;
try {
String regEx_script = "<script[^>]*?> [\\s\\S]*?</script>";
p_script = Pattern.compile (regEx_script,Pattern.CASE_INSENSITIVE);
m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); // 過濾 script 標簽
}catch(Exception e) {e.printStackTrace();}
return htmlStr;// 返回文本字符串
}
通過一系列的標簽過濾,我們可以得到網頁的正文內容,就可以用於下一步 的分詞了。
分詞
中文分詞是指將一個漢字序列切分成一個一個單獨的詞,從而達到計算機可 以自動識別的效果。中文分詞主要有三種方法:第一種基於字符串匹配,第二種 基於語義理解,第三種基於統計。由於第二和第三種的實現需要大量的數據來支 持,所以我們采用的是基於字符串匹配的方法。
基於字符串匹配的方法又叫做機械分詞方法,它是按照一定的策略將待分析 的漢字串與一個“充分大的”機器詞典中的詞條進行配,若在詞典中找到某個字 符串,則匹配成功(識別出一個詞)。按照掃描方向的不同,串匹配分詞方法可 以分為正向匹配和逆向匹配;按照不同長度優先匹配的情況,可以分為最大(最 長)匹配和最小(最短)匹配。常用的幾種機械分詞方法如下:
正向減字最大匹配法(由左到右的方向);
逆向減字最大匹配法(由右到左的方向);
最少切分(使每一句中切出的詞數最小);
雙向最大減字匹配法(進行由左到右、由右到左兩次掃描);
我們采用其中的正向最大匹配法。算法描述如下:輸入值為一個中文語句 S ,以及最大匹配詞
取 S 中前 n 個字,根據詞典對其進行匹配,若匹配成功,轉 3,否則轉 2 ;
n = n – 1:如果 n 為 1,轉 3;否則轉 1;
將 S 中的前 n 個字作為分詞結果的一部分,S 除去前 n 個字,若 S 為空 ,轉 4;否則,轉 1;
算法結束。
需要說明的是,在第三步的起始,n 如果不為 1,則意味著有匹配到的詞; 而如果 n 為 1,我們默認 1 個字是應該進入分詞結果的,所以第三步可以將前 n 個字作為一個詞而分割開來。還有需要注意的是對於停用詞的過濾,停用詞即 漢語中“的,了,和,麼”等字詞,在搜索引擎中是忽略的,所以對於分詞後的 結果,我們需要在用停用詞列表進行一下停用詞過濾。
您也許有疑問,如何獲得分詞字典或者是停用詞字典。停用詞字典比較好辦 ,由於中文停用詞數量有限,可以從網上獲得停用詞列表,從而自己建一個停用 詞字典;然而對於分詞字典,雖然網上有許多知名的漢字分詞軟件,但是很少有 分詞的字典提供,這裡我們提供一些在 dySE 中使用的分詞字典給您。在程序使 用過程中,分詞字典可以放入一個集合中,這樣就可以比較方便的進行比對工作 。
分詞的結果對於搜索的精准性有著至關重要的影響,好的分詞策略經常是由 若干個簡單算法拼接而成的,所以您也可以試著實現雙向最大減字匹配法來提高 分詞的准確率。而如果遇到歧義詞組,可以通過字典中附帶的詞頻來決定哪種分 詞的結果更好。
倒排索引
這個章節我們為您講解預處理模塊的最後兩個步驟,索引的建立和倒排索引 的建立。有了分詞的結果,我們就可以獲得一個正向的索引,即某個網頁以及其 對應的分詞結果。如下圖所示:
圖 2. 正向索引
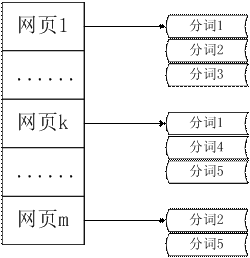
圖 3. 倒排索引
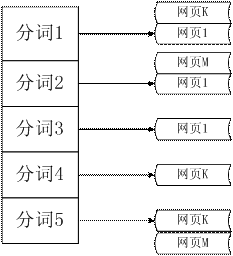
在本文的開頭,我們建立了索引網頁庫,用於通過 URL 可以直接定位到原始 網頁庫中該 URL 對應的數據的位置;而現在的正向索引,我們可以通過某個網 頁的 URL 得到該網頁的分詞信息。獲得正向索引看似對於我們的即將進行的查 詢操作沒有什麼實際的幫助,因為查詢服務是通過關鍵詞來獲得網頁信息,而正 向索引並不能通過分詞結果反查網頁信息。其實,我們建立正向索引的目的就是 通過翻轉的操作建立倒排索引。所謂倒排就是相對於正向索引中網頁——分詞結 果的映射方式,采用分詞——對應的網頁這種映射方式。與圖 2 相對應的倒排 索引如上圖 3 所示。
接下來我們分析如何從正向索引來得到倒排索引。算法過程如下:
對於網頁 i,獲取其分詞列表 List;
對於 List 中的每個詞組,查看倒排索引中是否含有這個詞組,如果沒有, 將這個詞組插入倒排索引的索引項,並將網頁 i 加到其索引值中;如果倒排索 引中已經含有這個詞組,直接將網頁 i 加到其索引值中;
如果還有網頁尚未分析,轉 1;否則,結束
建立倒排索引的算法不難實現,主要是其中數據結構的選用,在 dySE 中, 正向索引和倒排索引都是采用 HashMap 來存儲,映射中正向索引的鍵是采用網 頁 URL 對應的字符串,而倒排索引是采用分詞詞組,映射中的值,前者是一個 分詞列表,後者是一個 URL 的字符串列表。這裡可以采用一個優化,分別建立 兩個表,按照標號存儲分詞列表和 URL 列表,這樣,索引中的值就可以使用整 型變量列表來節省空間。
初步實驗
到目前為止,雖然我們還沒有正式的查詢輸入界面以及結果返回頁面,但這 絲毫不影響我們來對我們的搜索引擎進行初步的實驗。在倒排索引建立以後,我 們在程序中獲得一個倒排索引的實例,然後定義一個搜索的字符串,直接在倒排 索引中遍歷這個字符串,然後返回該詞組所指向的倒排索引中的 URL 列表即可 。
小結
網頁的預處理是搜索引擎的核心部分,建立索引網頁庫是為了網頁數據更方 便的從原始網頁庫中獲取,而抽取正文信息是後續操作的基礎。從分詞開始就正 式涉及到搜索引擎中文本數據的處理,分詞的好壞以及效率很大程度上決定著搜 索引擎的精確性,是非常需要關注的一點,而倒排索引時根據分詞的結果建立的 一個“詞組——對應網頁列表”映射,倒排索引是網頁搜索的最關鍵數據結構, 搜索引擎執行的速度與倒排索引的建立以及倒排索引的搜索方式息息相關。
後續內容
在本系列的第三部分中,您將了解到如何從創建網頁,從網頁中輸入查詢信 息通過倒排索引的搜索完成結果的返回,並且完成網頁排名的功能。