我們曾不只一次的聽到2010年將是Java模塊化的一年的言論;也知道目前為Java提供模塊化的OSGi正在受到IBM和Eclipse基金會的大力支持。但作為實現Java模塊化應用的基礎框架,OSGi似乎並不完美;我們經常能聽到關於OSGi過於復雜的抱怨。
從個人的角度,我以開放的心態去了解OSGi。令人失望的是,我發現它的規則非常復雜而且是低階的(low-level),對於大多數企業 Java 環境,需要對其進行許多改善/縮寫的工作,才能讓它更容易被人理解。對於大多數實際的企業需求,它又顯得功能過於強大。比較而言,Jigsaw 感覺更“干淨”,以 Java 為中心,緊湊而且易於理解。
說實話,這種抱怨讓我有點困惑。我來假設一下,如果OSGi 現在並不存在,有人給我一項任務,為Java 平台設計一個新的模塊系統,那麼對於這個模塊系統的最合理的需求集合將直接指向OSGi,因為OSGi的設計目的可能是滿足我們需求的最簡單的解決方案。
是不是我的想象力不夠?或者這不過是愛因斯坦剃刀原理(事物應盡可能簡單而不是更簡單)打敗奧卡姆剃刀原理(如無必要,勿增實體)的又一個實例?
另外,我認可OSGi 初看並不是那麼簡單這一說法,尤其是你不了解它為什麼會是現在這樣的時候。
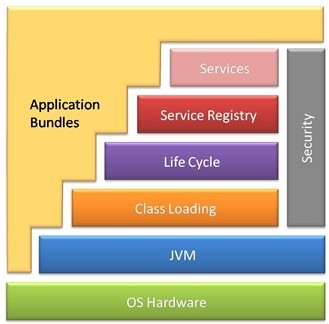
OSGi框架的各個組成部分
在這篇文章中,我將按照上述的那個假設,從零開始設計OSGi 系統。當然許多細節問題在這裡我不能一一講述。下面切入正題,為什麼OSGi 成為現在這個樣子?我們一起看看OSGi不算漫長但足夠復雜的進化(這種進化是積極的,因為它為解決業界實際存在的問題而生)。
模塊分離
我們的第一個需求是清晰地劃分模塊,這樣一個模塊中的類就不會具有我們無法控制的功能:使用或覆蓋另一個模塊中的類。在傳統的 Java 中有一個“classpath”(類路徑),這是一個巨大的類列表,當多個類碰巧使用相同的名稱時,總是使用第一個類,而第二個和其他所有的同名類將被忽略。看起來這種事情不會經常發生,當事實並非如此。當存在許多庫而這些庫又依靠其他庫時,這個問題就變得常見了。這個覆蓋問題絕對是致命的,因為它會導致一些奇怪的錯誤,比如 LinkageError、IncompatibleClassChangeError 等。事實上能夠看到這些錯誤,那還是比較幸運的。倒霉的是這些錯誤沒有提示,而系統一聲不響地錯誤地運行,哪怕在部署之前我們做了許多先行測試。
對於類的覆蓋和不可能空的可見性,預防方法是為每一個模塊創建一個類加載器(class loader)。類加載器能夠做到僅加載它能夠直接識別的類,在我們的這個系統中,就是某個模塊的內容(不過,它也可以根據類對類的方式,請求其他類加載器提供類,這種方式稱為委派,即 delegation)。使用類加載器之後,每個模塊包括他需要處理的代碼和類,而且能夠保證獲得按照計劃應該使用的類,即使系統中的其他模塊包含同名的類。
從整體上恢復可見性等功能
完成以上步驟之後,我們到達這樣一個點:所有模塊完全隔離,無法互相通信。為了讓這個系統變得實用些,我們需要恢復一些功能,以便能夠看到其他模塊中的類,不過這樣做時必須非常謹慎,而且必須使用嚴格控制的方式。這裡我們又多了一個需求:模塊需要能夠隱藏某些部署細節。
在 Java 中,protected/默認和 public 類型之間缺少訪問修飾符。假設我寫了一個庫,希望這個庫中其他包能夠使用我的一個類,我必須讓這個類設置為 public。但這樣這個類將對所有人是可見的,包括這個庫外部的客戶,這些客戶將能夠直接使用我的內部類。我們想要的是一個“模塊”級的訪問級別,但現在的問題是 javac 編譯器無法區分模塊邊界在哪裡,因此對於這樣的訪問修飾符它無法執行任何檢測。事實上,現有的“默認”訪問修飾符也是有問題的,因為它應該只對同一個“運行時包(runtime package,即由某個特定類加載器加載的包)”提供訪問權。但同樣 javac 無法確定運行時存在哪些加載器。對於這種情況,Javac 會采取冒險的方式:即使之後會導致 IllegalAccessErrors 錯誤,它也會提供訪問權。
在我們這個模塊系統中,我們選擇的解決方式是允許模塊僅“導出”其內容的一部分。如果模塊中某些部分是非導出的,那麼對於其他模塊就是不可見的。但默認導出哪些內容?除了某些明顯需要隱藏的部分,我們應該導出所有內容嗎?或者除了那些明顯需導出的部分,我們應該隱藏所有其他內容?選擇後者看起來能夠到來更好的透明度:我們可以很方便查看導出列表,確定那些可見的部分,即模塊的“表面部分”。
請注意,我目前還沒指定具體導出什麼內容,這是一個需要仔細考慮的問題。
導出的反面是什麼?當然是導入。一個模塊想要使用其他模塊中代碼可以從後者進行導入。現在我們有了另一個選擇……我們應該導入另一個模塊導出的所有內容嗎?或者只導入我們所需的那部分?同樣我們還是選擇後者,因為它會帶來更好的透明度:重要的是我們導入了什麼而不是從哪裡導入。
與購物行為進行類比
關於導入的話題非常重要,所以這裡次岔開一下話題,讓我們看一個有點搞笑又有點誇張的購物行為。
我妻子和我的購物方式是不同的。我認為購物是一件麻煩的瑣事。每當不得不去買東西時,我就找到一家商店(或者一組商店),那裡有我需要的東西,我只買我需要的商品,買到之後回家。只要能買到我需要的東西,我不關心是從哪家商店買到的。
而我妻子去了一家商店,那家商店買什麼她就買什麼。
很明顯我覺得我的購物方式更好,因為我妻子無法控制她能買到什麼東西。如果她常去的一家商店更換了貨櫃上的商品,那她買回來的將是另外一些東西。當然很多東西並不是她需要的,而且她真正需要的又沒有買到。
更糟糕的是,有時她買回來的東西並不能獨自使用,因為還需要其他東西,比如電池。所以她不得不再次去商店裡買電池,同樣這次她會買下電池商店裡出售的各種電池。再進一步假設,從電池商店裡買到的某樣東西還依靠其他東西才能使用,所以她又跑去另一家商店,僅僅是為了讓某些商品能夠正常工作,而這些商品從最初就不是我們所需要的。這個問題被稱為“扇出”(fan-out)。
通過這個購物類比,相信你對模塊系統將有一個更清晰的概念。這種非理智的購物行為等同於這樣一個系統:我們申明了對某個模塊的依靠性,而這個系統強制我們從該模塊導入所有內容。當進行導入時,應導入所有我們實際需要的內容,而不管它來自哪裡,同時忽略其他所有內容,可能內容只是碰巧位於它的包內。使用 Maven 構建工具時我們遇到這個尖銳的“扇出”問題,這個工具僅提供整體模塊的依賴性(即“買下整個商店”方式)。其結果是,在編譯 200 個字節的源文件之前,必須下載整個互聯網的內容。
導入和導出的粒度(granularity)
從模塊導入和導出內容的粒度應該是怎樣的?由於存在各種嵌入等級,Java 中有多種等級的粒度。方法和域嵌入到類中,類又嵌入到包中,包嵌入到模塊或 JAR 文件中。
不難看出共享等級不應是方法和域。導入一個類的某些方法而排除例外一些,這種方式很明顯是荒唐的。不僅僅這種方式是如此。我們可以為某個模塊中類寫一些方法/域,在另一個模塊中再寫一些方法/域,這種方式也同樣是不可行的。想象一下,為在模塊中的每一個共享方法寫一些導入和導出列表,運行時對這些列表進行檢查以及診斷為題的復雜度將是非常恐怖的,會出現許多錯誤,因為類並不是設計用來在運行時進行分割的。
現在看看另一個極端,共享等級也不應是整個模塊,因為這樣模塊就不能隱藏實施細節的部分,導入方將經常性地遇到“買下整個商店”的問題。
所以唯一合理的選擇是類和包。老實說,選擇類也不是那麼合理。雖然沒有方法/域那麼糟糕,但類的數量非常多,由於它太過於依賴同一個包中的其他類,無論是將類列出作為我們的導入和導出,還是將包中的一些類劃分到某個模塊同時將同一個包中另一些類劃分到了另一個模塊中,都是不合理的。
最終的結果,OSGi 選擇了包。Java 包的內容通常具有某種程度的一致性,但列出導入和導出的包並不是那麼麻煩,而且在某個模塊加入一些包而在另一個模塊在加入另一些包,並不會對如何東西造成損壞。應該屬於模塊內部的代碼可以放到一個或多個非導出的包中。
我們的損失的無法干淨地處理那些所謂的“分裂包”(split- package)。在 OSGi 中,包是進行共享的最基本單元:當導入個包時,你獲得一個模塊導出包的所有內容而不包括其他內容。一些傳統的包,一直堅持在許多模塊中共享包內容,對於這些包也存在一些方法進行處理,但這好過對每個包進行調整以便讓它作為整體只能由某個模塊導出。
包連線(wiring)
既然對於模塊如何自我分離然後再連接有了一個模型,我們現在可以想象創建一個框架,這個框架將為這些模塊構造實際的運行時實例。它將負責安裝模塊以及構造類加載器(這些類加載器知道相應模塊的內容)。
然後它將查看新安裝的模塊的導入,並試圖找到匹配的導出。假設模塊 A 導出包 com.foo,模塊 B 要導入這個包。該框架將通知 B,它可以從模塊 A 獲得 com.foo 的類,這個稱為連線(wiring)。如果 B 的類加載器要加載類 com.foo.Bar,它將委派 A 的類加載器來做。對整個模塊的導入進行連線的過程成為解析(resolution),當所有導入都成功進行連線後,那麼這個組件(bundle)就被解析 (resolved)了,這將令它完全可用。
一個預料之外的好處是我們可以動態地安裝、更新和卸載模塊。對於已經解析的模塊,安裝新模塊對它們沒有影響,雖然這可能導致某些之前不可解析的模塊變得可解析。當進行卸載或更新時,該框架非常清楚那些模塊受到影響,並且如果需要它將更改它們的狀態。為了能夠順利地進行,還有一些額外的細節需要處理,比如,一個模塊在卸載或者取消解析之前正在做非常的事情,那麼需要向它發送通知,以便讓它干淨利落地關閉。所以,OSGi 中的動態模塊並不是憑空出現的,這裡並沒有什麼神奇的功能,但 OSGi 至少讓它成為可能。
某些 OSGi 用戶更喜歡避免動態加載,這樣做沒有問題。這不是 OSGi 最重要的功能,但由於對於 OSGi 它是獨一無二的,英尺獲得了過多的關注。無論如何,沒有人強迫你使用它,即使從來不去利用動態性的優勢,你仍然能夠從 OSGi 獲得許多好處。
版本控制
我們的模塊系統現在看起來非常不錯,但隨著時間的推移,模塊不可避免地會發生方便,對稱我們還不能處理。所以,我們還需要支持“版本控制”。
如何進行版本控制?手洗,導出方可可進行聲明,為其導出的包提供一些有用的信息:“這個是 API 版本 1.0.0”。導入方現在能夠只導入與其預期匹配並且經過編譯/測試的版本,並且解決接受某個版本,比如版本 3.0.0。但是如果導入方想要版本 1.0.0 而只有版本 1.0.1 可用時,應該如何處理呢?一個稍高一點的版本看起來不會保護巨大的更改,所以導入方應該可以接受版本 1.0.1。事實上,導入方應為其可接受版本指定一個范圍,比如類似這樣的一個范圍:“版本 1.0.0 到 2.0.0 但不含 2.0.0”。對包進行連線的流程可以支持這種范圍,如果導出的導出版本位於導入指定的范圍內,就將導入與該導出進行連線。為了讓這個機制能夠正常使用,版本編號應該是有順序的並且能夠進行比較。
我們如何確定版本 1.0.1 相對於 1.0.0 沒有包含巨大的更改呢?很遺憾,我們無法確認這種事情。對於版本編號,OSGi 強烈建議而不是強制使用以下語法規則:
1. 對於非向後兼容的更改,對主要(第一)部分進行遞增。
2. 對於向後兼容的功能改善,對次要(中間)部分進行遞增。
3. 對於未造成可見的功能更改的故障修復,對最後部分進行遞增。
如果所有人都遵守這些語法規則,那麼指定導入范圍將是一件輕松簡單的事情。但現實世界並不是這麼簡單,因此在試用如何外部庫時,我們必須小心地處理兼容問題。
對模塊和元數據進行打包
我們這個模塊系統需要一種方法來對模塊的內容以及描述導入和導出的元數據進行打包,將其包括到一個可部署的單元中。
Java 已經有了標准的部署單元:JAR 文件。JAR 文件可能並不算一種非常成熟的模塊,但對於移動大塊的編譯代碼還是不錯的,所以我們並不需要創建新的東西。那麼現在的唯一問題是,將元數據(即導入和導出列表、版本等等)放在哪裡?
看起來配置格式強烈地受到一時潮流的影響;如果我們是在 2000 年到 2006 年期間設計這個模塊系統,我們很可能會選擇將元數據放到 JAR 文件下的某個 XML 文件中這種方式能夠工作,但會遇到許多問題:對於流程,XML 文件並不是特別有效率,尤其是我們必須在 JAR 文件的某個地方才能找到它,而且在進行語法分析之前還要對其進行解壓。JAR 文件是一個 ZIP 壓縮包,所以要找到某個特定文件,意味著必須讀取末端,找到用於跟蹤記錄的中央目錄,然後再跳轉到該目錄指定的分支上。換句話說,通常不得不讀取整個 JAR 文件,對於需掃描大型目錄的工具,如果這個目錄下有很多模塊,這個過程將變得非常痛苦。比如,搜索某個可用的模塊,以滿足某個依賴關系。
另外 XML 幾乎不能人工編輯。為了正確的編輯這種文件,我們需要使用特定的編輯根據。
另一方面,如果是在 2006年之後設計這個模塊系統,我們的第一個想法會是使用 Java 注釋(annotation)。如果使用適當,我非常喜歡注釋,將類似 @Export(version="1.0.0") 的東西放到 Java 源文件中的包聲明上,很明顯比在單獨文件中對其進行維護要更有吸引力。不過,等一下……在包的每個源文件中,包聲明都會重復一次;難道我們也必須在所有源文件中加入注釋?
為了解決這個問題,Java 語言規范(JLS)建議使用一個名為“package-info.java” 特定源文件。但對於不屬於任何特定包的元數據怎麼處理呢?比如導入包的列表或模塊本身的名稱和版本。Java 語言規范建議我們需要使用另一個特定源文件,使用類似“module-info.Java”名稱。
到目前一切順利,現在讓我們看看如何對模塊進行處理。
這些特定的源文件將在 package-info.class 和 module-info.class 中被編譯為字節碼,這樣就不需要打開 ZIP 壓縮的 JAR 文件來查看元數據了。所有模塊掃描工具都必須對整個模塊系統進行讀取,而且也必須能夠處理字節碼。運行時模塊系統自身也必須立即為模塊常見一個類加載器,用於讀取它的元數據;結果是,如果我們能夠將類加載器的創建推遲到真正從模塊中加載某個類那個時刻,就可以消除大量的優化工作。
已經發生的事實是,OSGi 的設計的確是在 2000 年之前,所以它的確選擇了這些方案中的其中之一。回頭看看 JAR 文件規范,答案自動浮現:META-INF/MANIFEST.MF 是應用程序專用元數據的標准位置。在規范中這樣寫道:“忽略不可理解的屬性。這類屬性可能包含應用程序所用的特定部署新型。”
MANIFEST.MF 專為提高流程的效率而設計,而且它至少比 XML 更快。某種長度上,它是可讀的;至少與 XML 一樣可讀,很明顯比編譯的 Java 字節碼更具有可讀性。此外,標准的 jar 命令行工具通常將 MANIFEST.MF 放到 JAR 文件的第一項中,所以為了獲取元數據,工具只需掃描文件中的前幾百個字節。
令人遺憾的是 MANIFEST.MF 並不完美。其一,由於規則要求每行不超過 72 個字節,手工編寫相對困難,考慮到單個 UTF-8 字符為 1-6 個字節,這種規則會導致一些問題。一個更好的方式是利用另一格式的模板來生成 MANIFEST.MF。Bnd 工具是這樣的,Maven 的 Bundle Pulin 和 SpringSource 的 Bundlor 也是如此。
事實上,Bnd 甚至包括對於處理注釋的實驗式的支持,比如 @Exporton 源代碼注釋。這樣我們將能夠獲得來自2個方面的好處:注釋的便利性,以及 MANIFEST.MF 的效率和運行時可讀性/工具性。
後期綁定
模塊拼圖的最後一塊是部署到接口的後期綁定。我認為這是模塊化一個至關重要的功能,雖然某些模塊系統對此完全忽略,或者認為它不屬於模塊化這個范圍。
人們都知道,Java 中的接口會破壞功能提供者和使用方之間的耦合性。定義一個接口,其作用相對於使用方和提供方的合同,如何一方都不需直接獲得對方的信息,這樣我們就可以將它們放到不同的模塊中,而這些模塊之間不存在互相的依賴關系。而是每一個模塊對於接口存在依靠性,我們可以選擇囧這個接口放在第三個模塊中。唯一的問題是如何為使用方類提供接口實例,而最常見的答案是使用依賴注入(Dependency Injection,縮寫為DI),比如 Spring 或 Guice。
因此,為了完成我們的模塊系統,只需使用現有的 DI 框架即可。畢竟我們追求的簡潔性,聲明一個問題不屬於我們處理的范圍,讓別人來解決,沒有什麼比這個還簡單。但是,這種方式並不是非常令人滿意,因為 DI 框架事實上也需要知道模塊的邊界。傳統的 DI 使用方式的問題在於它會創建巨大的中心化配置,這個配置會對所有模塊產生影響。Peter KrIEns 將這一問題稱為“全能類”(God Class)問題,在這個問題中,一個組件了解每個模塊的所有內容,並要求所有模塊對其進行綁定(作為一個無神論者,我認為這個不可能做到,但即便你是有神論者,我肯定你也同意除了當前已存在的上帝之外,我們不應再去制造更多神)。這些全能類(或 XML 配置)非常脆弱,難於維護,否定了將代碼劃分到模塊中所帶來的大多數好處。
我們應該尋找一種去中心化的方法。不是讓全能類告訴我們去做什麼,我們可以假設,每個模塊可能常見對象並將它們發布到某些地方,而其他模塊可以找到它們。我們將這些發布的對象成為“服務”,而它們發布的地方稱為 “服務寄存器”。有關服務,最重要的信息是它進行部署的接口,所以我們可以將它作為最初的注冊碼。現在,一個模塊,如果需要找到特定接口的實例,只需查詢寄存器,看看當時提供哪些服務。寄存器本身仍然是位於任何模塊之外的中性化組件,但它不是全能的,而是更像一個共享黑板。
我們不需要放棄 DI,事實上它還非常有用:現有的 DI 框架可用來向其他服務中注入服務,以及將某些對象發布為服務。DI 框架不在指揮整個系統,相反它只是在單個模塊中的部署的應用。我們甚至可以使用多個 DI 框架,比如在同一個應用程序中同時使用 Spring 和 Guice,當想要集成第三方組件而這個組件使用的框架不是我們所選擇的那個時,這是非常有用的。最後,服務寄存器為發布和查詢提供可編程的 API 接口,但只能用於低階工作,如部署一個新的 DI 框架。
總結
希望以上的泛泛而論能夠解釋為什麼 OSGi 會是現在這個樣子;從某種意義上說,這是一種技術的進化。人們將會繼續抱怨OSGi 太復雜,但我認為任何存在的復雜性都是必要的,用於解決我以上描述的難題。
當然它並不是完美的。比如,版本控制還可以進行改善,尤其是對於那些版本方案非常奇怪的第三方庫。為版本編號賦予一定的意義,仍然是正確的做法,但為了對版本和 API 兼容性進行管理,還需要更多的協助工具。還有傳統的庫,仍然在危險的假設一個扁平化系統類路徑的存在。按照我的觀點,任何在類名稱中使用字符串或調用 Class.forName() 來獲得對象的庫都是錯誤的,因為它假設所有類對於模塊都是可見的,而在任何類型的模塊化系統中,這都是不正確的。很遺憾,這些問題還不能在一夜之間完全解決,所以處理這些破損的庫,我們需要一些策略。不過處理這些問題需要一種不同的方式,從而對於其他人來說,不至於破壞模塊化的規則。