在大型web應用中,緩存可算是當今的一個標准開發配置了。在大規模的緩存應用中,應運而生了分布式緩存系統。分布式緩存系統的基本原理,大家也有所耳聞。key-value如何均勻的分散到集群中?說到此,最常規的方式莫過於hash取模的方式。比如集群中可用機器適量為N,那麼key值為K的的數據請求很簡單的應該路由到hash(K) mod N對應的機器。的確,這種結構是簡單的,也是實用的。但是在一些高速發展的web系統中,這樣的解決方案仍有些缺陷。隨著系統訪問壓力的增長,緩存系統不得不通過增加機器節點的方式提高集群的相應速度和數據承載量。增加機器意味著按照hash取模的方式,在增加機器節點的這一時刻,大量的緩存命不中,緩存數據需要重新建立,甚至是進行整體的緩存數據遷移,瞬間會給DB帶來極高的系統負載,設置導致DB服務器宕機。 那麼就沒有辦法解決hash取模的方式帶來的诟病嗎?看下文。
選擇具體的機器節點不在只依賴需要緩存數據的key的hash本身了,而是機器節點本身也進行了hash運算。
(1) hash機器節點
首先求出機器節點的hash值(怎麼算機器節點的hash?ip可以作為hash的參數吧。。當然還有其他的方法了),然後將其分布到0~2^32的一個圓環上(順時針分布)。如下圖所示:
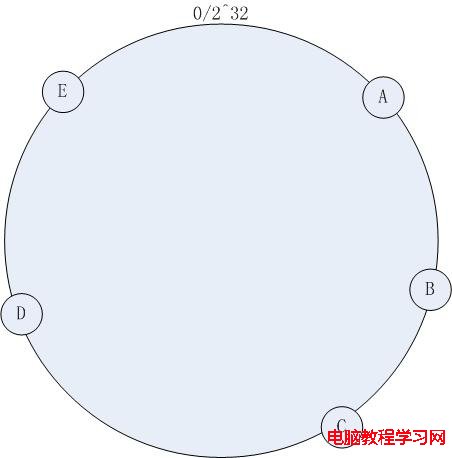
集群中有機器:A , B, C, D, E五台機器,通過一定的hash算法我們將其分布到如上圖所示的環上。
(2)訪問方式
如果有一個寫入緩存的請求,其中Key值為K,計算器hash值Hash(K), Hash(K) 對應於圖 – 1環中的某一個點,如果該點對應沒有映射到具體的某一個機器節點,那麼順時針查找,直到第一次找到有映射機器的節點,該節點就是確定的目標節點,如果超過了2^32仍然找不到節點,則命中第一個機器節點。比如 Hash(K) 的值介於A~B之間,那麼命中的機器節點應該是B節點(如上圖 )。
(3)增加節點的處理
如上圖 – 1,在原有集群的基礎上欲增加一台機器F,增加過程如下:
計算機器節點的Hash值,將機器映射到環中的一個節點,如下圖:
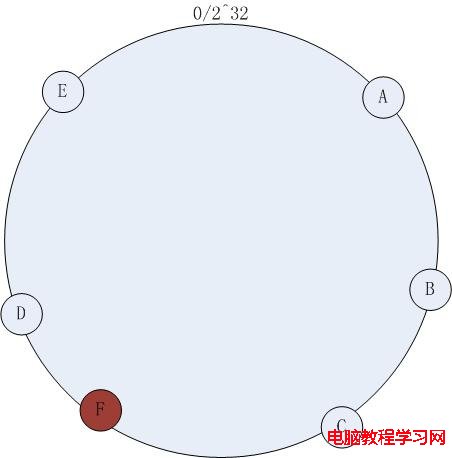
增加機器節點F之後,訪問策略不改變,依然按照(2)中的方式訪問,此時緩存命不中的情況依然不可避免,不能命中的數據是hash(K)在增加節點以前落在C~F之間的數據。盡管依然存在節點增加帶來的命中問題,但是比較傳統的 hash取模的方式,一致性hash已經將不命中的數據降到了最低。
Consistent Hashing最大限度地抑制了hash鍵的重新分布。另外要取得比較好的負載均衡的效果,往往在服務器數量比較少的時候需要增加虛擬節點來保證服務器能均勻的分布在圓環上。因為使用一般的hash方法,服務器的映射地點的分布非常不均勻。使用虛擬節點的思想,為每個物理節點(服務器)在圓上分配100~200個點。這樣就能抑制分布不均勻,最大限度地減小服務器增減時的緩存重新分布。用戶數據映射在虛擬節點上,就表示用戶數據真正存儲位置是在該虛擬節點代表的實際物理服務器上。
下面有一個圖描述了需要為每台物理服務器增加的虛擬節點。
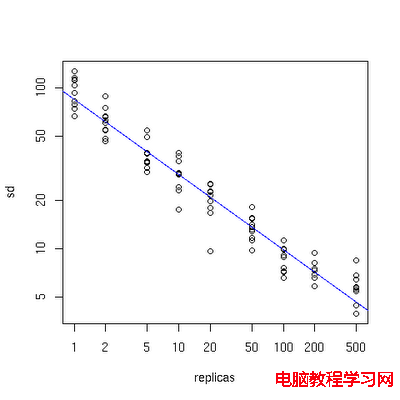
x軸表示的是需要為每台物理服務器擴展的虛擬節點倍數(scale),y軸是實際物理服務器數,可以看出,當物理服務器的數量很小時,需要更大的虛擬節點,反之則需要更少的節點,從圖上可以看出,在物理服務器有10台時,差不多需要為每台服務器增加100~200個虛擬節點才能達到真正的負載均衡。