備注: 本篇文章是關於先前相同主題文章的最新版本。先前文章主要介紹創建高性能解析器的一些要點,但它吸收了讀者的一部分批評建議。原來的文章進行了全面修訂,並補充了相對完整的代碼。我們希望你喜歡本次更新。
如果你沒有指定數據或語言標准的或開源的Java解析器, 可能經常要用Java實現你自己的數據或語言解析器。或者,可能有很多解析器可選,但是要麼太慢,要麼太耗內存,或者沒有你需要的特定功能。或者開源解析器存在缺陷,或者開源解析器項目被取消諸如此類原因。上述原因都沒有你將需要實現你自己的解析器的事實重要。
當你必需實現自己的解析器時,你會希望它有良好表現,靈活,功能豐富,易於使用,最後但更重要是易於實現,畢竟你的名字會出現在代碼中。本文中,我將介紹一種用Java實現高性能解析器的方式。該方法不具排他性,它是簡約的,並實現了高性能和合理的模塊化設計。該設計靈感來源於VTD-XML ,我所見到的最快的java XML解析器,比StAX和SAX Java標准XML解析器更快。
解析器有多種分類方式。在這裡,我只比較兩個基本解析器類型的區別:
順序訪問解析器(Sequential access parser)
隨機訪問解析器(Random access parser)
順序訪問意思是解析器解析數據,解析完畢後將解析數據移交給數據處理器。數據處理器只訪問當前已解析過的數據;它不能回頭處理先前的數據和處理前面的數據。順序訪問解析器已經很常見,甚至作為基准解析器,SAX和StAX解析器就是最知名的例子。
隨機訪問解析器是可以在已解析的數據上或讓數據處理代碼向前和向後(隨機訪問)。隨機訪問解析器例子見XML DOM解析器。
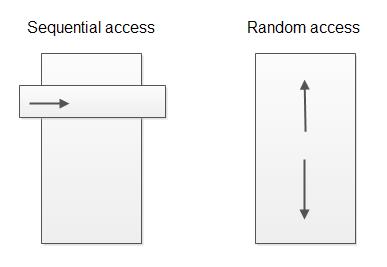
順序訪問解析器只能讓你在文檔流中訪問剛解析過的“窗口”或“事件”,而隨機訪問解析器允許你按照想要的方式訪問遍歷。
我這裡介紹的解析器設計屬於隨機訪問變種。
隨機訪問解析器實現總是比順序訪問解析器慢一些,這是因為它們一般建立在某種已解析數據對象樹上,數據處理器能訪問上述數據。創建對象樹實際上在CPU時鐘上是慢的,並且耗費大量內存。
代替在解析數據上構建對象樹,更高性能的方式是建立指向原始數據緩存的索引緩存。索引指向已解析數據的元素起始點和終點。代替通過對象樹訪問數據,數據處理代碼直接在含有原始數據的緩存中訪問已解析數據。如下是兩種方法的示意圖:
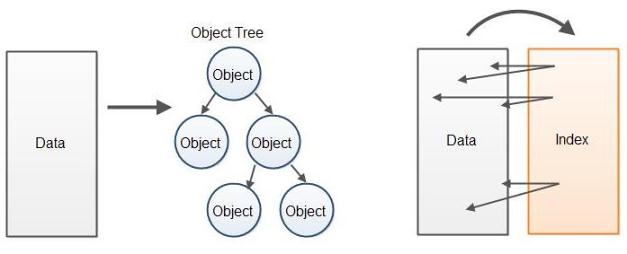
因為沒找到更好的名字,我就叫該解析器為“索引疊加解析器”。該解析器在原始數據上新建了一個索引疊加層。這個讓人想起數據庫構建存儲在硬盤上的數據索引的方式。它在原始未處理的數據上創建了指針,讓浏覽和搜索數據更快。
如前所說,該設計受VTD-XML的啟發, VTD是虛擬令牌描述符(Virtual Token Descriptor)的英文縮寫。因此,你可以叫它虛擬令牌描述符解析器。不過,我更喜歡索引疊加的命名,因為這是虛擬令牌描述符代表,在原始數據上的索引。
一般解析器設計會將解析過程分為兩步。第一步將數據分解為內聚的令牌,令牌是一個或多個已解析數據的字節或字符。第二步解釋這些令牌並基於這些令牌構建更大的元素。兩步示意圖如下:
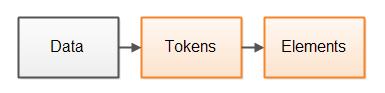
圖中元素並不是指XML元素(盡管XML元素也解析元素),而更大“數據元素”構造了已解析數據。在我XML文檔中表示XML元素,而在JSON 文檔中則表示JSON對象,諸如此類。
舉例說明,字符串將被分解為如下令牌:
< myelement >
一旦數據分解為多個令牌,解析器更容易理解它們和判斷這些令牌構造的大元素。解析器將會識別XML元素以 ‘<’令牌開頭後面是字符串令牌(元素名稱),然後是一系列可選的屬性,最後是‘>’令牌。
兩步方法也將用於我們的解析器設計。輸入數據首先由分析器組件分解為多個令牌。 然後解析器解析這些令牌識別輸入數據的大元素邊界。
你也可以增加可選的第三步驟—“元素導航步驟”到解析過程中。 若解析器從已解析數據中構造對象樹,那麼對象樹一般會包含對象樹導航的鏈接。當我們構建元素索引緩存代替對象樹時,我們需要一個獨立組件幫助數據處理代碼導航元素索引緩存。
我們解析器設計概覽參見如下示意圖:
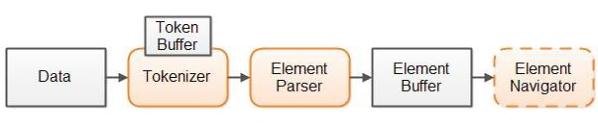
我們首先將所有數據讀到數據緩存內。為了保證可以通過解析中創建的索引隨機訪問原始數據,所有原始數據必需放到內存中。
接著,分析器將數據分解為多個令牌。開始索引,結束索引和令牌類型都會保存於分析器中一個內部令牌緩存。使用令牌緩存使其向前和向後訪問成為可能,上述情況下解析器需要令牌緩存。
第三步,解析器查找從分析器獲取的令牌,在上下文中校驗它們,並判斷它們表示的元素。然後,解析器基於分析器獲取的令牌構造元素索引(索引疊加)。解析器逐一獲得來自分析器的令牌。因此,分析器實際上不需要馬上將所有數據分解成令牌。而僅僅是在特定時間點找到一個令牌。
數據處理代碼能訪問元素緩存,並用它訪問原始數據。或者,你可能會將數據緩存封裝到元素訪問組件中,讓訪問元素緩存更容易。
該設計基於已解析數據構建對象樹,但它需建立訪問結構—元素緩存,由索引(整型數組)指向含有原始數據的數據緩存。我們能使用這些索引訪問存於原始數據緩存的數據。
下面小節將從設計的不同方面更詳細地進行介紹。
數據緩存是含有原始數據的一種字節或字符緩存。令牌緩存和元素緩存持有數據緩存的索引。
為了隨機訪問解析過了的數據,內存表示上述信息的機制是必要的。我們不使用對象樹而是用包含原始數據的數據緩存。
將所有數據放在內存中需消耗大塊的內存。若數據含有的元素是相互獨立的,如日志記錄,將整個日志文件放在內存中將是矯枉過正了。相反,你可以拉大塊的日志文件,該文件存有完整的日志記錄。因為每個日志記錄可完全解析,並且獨立於其它日志記錄的處理,所以我們不需要在同一時間將整個日志文件放到內存中。在我的文章—“使用緩存迭代訪問數據流”中,我已經描述了如何遍歷塊中的數據流。
分析器將數據緩分解為多個令牌。令牌信息存儲在令牌緩存中,包含如下內容:
令牌定位(起始索引)
令牌長度
令牌類型 (可選)
上述信息放在數組中。如下實例說明處理邏輯:
public class IndexBuffer {
public int[] position = null;
public int[] length = null;
public byte[] type = null;
/* assuming a max of 256 types (1 byte / type) */
}
當分析器找到數據緩存中令牌時,它將構建位置數組的起始索引位置,長度數組的令牌長度和類型數組的令牌類型。
若不使用可選的令牌類型數組,你仍能通過查看令牌數據來區分令牌類型。這是性能和內存消耗的權衡。
解析器是在性質上與分析器類似,只不過它采用令牌作為輸入和輸出的元素索引。如同使用令牌,一個元素由它的位置(起始索引),長度,以及可選的元素類型來決定。這些數字存儲在與存儲令牌相同的結構中。
再者,類型數組是可選的。若你很容易基於元素的第一個字節或字符確定元素類型,你不必存儲元素類型。
元素緩存中標記的要素精確粒度取決於數據被解析,以及需要後面數據處理的代碼。例如,如果你實現一個XML解析器,你可能會標記為每個“解析器元素”的開始標簽, 屬性和結束標簽。
解析器生成帶有指向元數據的索引的元素緩存。該索引標記解析器從數據中獲取的元素的位置(起始索引),長度和類型。你可以使用這些索引來訪問原始數據。
看一看上文的IndexBuffer代碼,你就知道元素緩存每個元素使用9字節;四個字節標記位置,四個自己是令牌長度,一個字節是令牌類型。
你可以減少IndexBuffer 的內存消耗。例如,如果你知道元素從不會超過65,536字節,那麼你可以用短整型數組代替整型來存令牌長度。這將每個元素節省兩個字節,使內存消耗降低為每個元素7個字節。
此外,如果知道將解析這些文件長度從不會超過16,777,216字節,你只需要三個字節標識位置(起始索引)。在位置數組中,每一整型第四字節可以保存元素類型,省去了一個類型數組。如果您有少於128的令牌類型,您可以使用7位的令牌類型而不是八個。這使您可以花25位在位置上,這增加了位置范圍最大到33,554,432。如果您令牌類型少於64,您可以安排另一個位給位置,諸如此類。
VTD-XML實際上會將所有這些信息壓縮成一個Long型,以節省空間。處理速度會有損失,因為額外的位操作收拾單獨字段到單個整型或long型中,不過你可以節省一些內存。總而言之,這是一個權衡。
元素導航組件幫助正在處理數據的代碼訪問元素緩存。務必記住,一個語義對象或元素(如XML元素)可能包括多個解析器元素。為了方便訪問,您可以創建一個元素導航器對象,可以在語義對象級別訪問解析器元素。例如,一個XML元素導航器組件可以通過在起始標記和到起始標記來訪問元素緩存。
使用元素導航組件是你的自由。如果要實現一個解析器在單個項目中的使用,你可以要跳過它。但是,如果你正在跨項目中重用它,或作為開源項目發布它,你可能需要添加一個元素導航組件,這取決於如何訪問已解析數據的復雜度。
為了讓索引疊加解析器設計更清晰,我基於索引疊加解析器設計用Java實現了一個小的JSON解析器。你可以在GitHub上找到完整的代碼。
JSON是JavaScript Object Notation的簡寫。JSON是一種流行的數據格式,基於AJAX來交換Web服務器和浏覽器之間的數據,Web浏覽器已經內置了JSON解析為JavaScript對象的原生支持。後文,我將假定您熟悉JSON。
如下是一個JSON簡單示例:
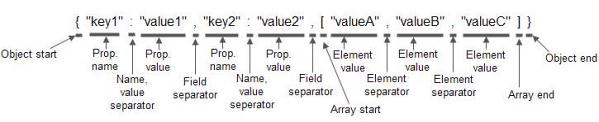
{ "key1" : "value1" , "key2" : "value2" , [ "valueA" , "valueB" , "valueC" ] }
JSON分析器將JSON字符串分解為如下令牌:
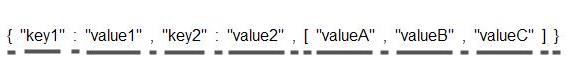
這裡下劃線用於強調每個令牌的長度。
分析器也能判斷每個令牌的基本類型。如下是同一個JSON示例,只是增加了令牌類型:

注意令牌類型不是語義化的。它們只是說明基本令牌類型,而不是它們代表什麼。
解析器解釋基本令牌類型,並使用語義化類型來替換它們。如下示例是同一個JSON示例,只是由語義化類型(解析器元素)代替:
一旦解析器完成了上述JSON解析,你將有一個索引,包含上面打標記元素的位置,長度和元素類型。你可以訪問索引從JSON抽取你需要的數據。
在GitHub庫中的實現包含兩個JSON解析器。其中一個分割解析過程為JsonTokenizer和JsonParser(如本文前面所述),以及一個為JsonParser2結合分析和解析過程為一個階段,一個類。JsonParser2速度更快,但更難理解。因此,我會在下面的章節快速介紹一下在JsonTokenizer和JsonParser類,但會跳過JsonParser2。
(本文第一個版本有讀者指出,從該指數疊加分析器的輸出是不是難於從原始數據緩沖區中提取數據。正如前面提到的,這就是添加一個元素導航組件的原因。為了說明這樣的元素導航組件的原理,我已經添加了JsonNavigator類。稍後,我們也將快速浏覽一下這個類。)
為了介紹分析和解析過程實現原理,我們看一下JsonTokenizer 和JsonParser 類的核心代碼部分。提醒,完整代碼可以在GitHub 訪問 。
如下是JsonTokenizer.parseToken()方法,解析數據緩存的下一個索引:
public void parseToken() {
skipWhiteSpace();
this.tokenBuffer.position[this.tokenIndex] = this.dataPosition;
switch (this.dataBuffer.data[this.dataPosition]) {
case '{': {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_CURLY_BRACKET_LEFT;
}
break;
case '}': {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_CURLY_BRACKET_RIGHT;
}
break;
case '[': {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_SQUARE_BRACKET_LEFT;
}
break;
case ']': {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_SQUARE_BRACKET_RIGHT;
}
break;
case ',': {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_COMMA;
}
break;
case ':': {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_COLON;
}
break;
case '"': { parseStringToken(); } break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': {
parseNumberToken();
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_NUMBER_TOKEN;
}
break;
case 'f': {
if (parseFalse()) {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_BOOLEAN_TOKEN;
}
}
break;
case 't': {
if (parseTrue()) {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_BOOLEAN_TOKEN;
}
}
break;
case 'n': {
if (parseNull()) {
this.tokenBuffer.type[this.tokenIndex] = TokenTypes.JSON_NULL_TOKEN;
}
}
break;
}
this.tokenBuffer.length[this.tokenIndex] = this.tokenLength;
}
如你所見,代碼相當簡潔。首先,skipWhiteSpace()調用跳過存在於當前位置的數據中的空格。接著,當前令牌(數據緩存的索引)的位置存於tokenBuffer 。第三,檢查下一個字符,並根據字符是什麼(它是什麼樣令牌)來執行switch-case 結構。最後,保存當前令牌的令牌長度。
這的確是分析一個數據緩沖區的完整過程。請注意,一旦一個字符串索引開始被發現,該分析器調用parseStringToken()方法,通過掃描的數據,直到字符串令牌結尾。這比試圖處理parseToken()方法內所有邏輯執行更快,也更容易實現。
JsonTokenizer 內方法的其余部分只是輔助parseToken()方法,或者移動數據位置(索引)到下一個令牌(當前令牌的第一個位置),諸如此類。
JsonParser類主要的方法是parseObject()方法,它主要處理從JsonTokenizer得到令牌的類型,並試圖根據上述類型的輸入數據找到JSON對象中。
如下是parseObject() 方法:
private void parseObject(JsonTokenizer tokenizer) {
assertHasMoreTokens(tokenizer);
tokenizer.parseToken();
assertThisTokenType(tokenizer.tokenType(), TokenTypes.JSON_CURLY_BRACKET_LEFT);
setElementData(tokenizer, ElementTypes.JSON_OBJECT_START);
tokenizer.nextToken();
tokenizer.parseToken();
byte tokenType = tokenizer.tokenType();
while (tokenType != TokenTypes.JSON_CURLY_BRACKET_RIGHT) {
assertThisTokenType(tokenType, TokenTypes.JSON_STRING_TOKEN);
setElementData(tokenizer, ElementTypes.JSON_PROPERTY_NAME);
tokenizer.nextToken();
tokenizer.parseToken();
tokenType = tokenizer.tokenType();
assertThisTokenType(tokenType, TokenTypes.JSON_COLON);
tokenizer.nextToken();
tokenizer.parseToken();
tokenType = tokenizer.tokenType();
switch (tokenType) {
case TokenTypes.JSON_STRING_TOKEN: {
setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_STRING);
}
break;
case TokenTypes.JSON_STRING_ENC_TOKEN: {
setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_STRING_ENC);
}
break;
case TokenTypes.JSON_NUMBER_TOKEN: {
setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_NUMBER);
}
break;
case TokenTypes.JSON_BOOLEAN_TOKEN: {
setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_BOOLEAN);
}
break;
case TokenTypes.JSON_NULL_TOKEN: {
setElementData(tokenizer, ElementTypes.JSON_PROPERTY_VALUE_NULL);
}
break;
case TokenTypes.JSON_CURLY_BRACKET_LEFT: {
parseObject(tokenizer);
}
break;
case TokenTypes.JSON_SQUARE_BRACKET_LEFT: {
parseArray(tokenizer);
}
break;
}
tokenizer.nextToken();
tokenizer.parseToken();
tokenType = tokenizer.tokenType();
if (tokenType == TokenTypes.JSON_COMMA) {
tokenizer.nextToken(); //skip , tokens if found here.
tokenizer.parseToken();
tokenType = tokenizer.tokenType();
}
}
setElementData(tokenizer, ElementTypes.JSON_OBJECT_END); }
}
parseObject()方法希望看到一個左花括號({),後跟一個字符串標記,一個冒號和另一個字符串令牌或數組的開頭([])或另一個JSON對象。當JsonParser從JsonTokenizer獲取這些令牌時,它存儲開始,長度和這些令牌在自己elementBuffer中的語義。然後,數據處理代碼可以浏覽這個elementBuffer後,從輸入數據中提取任何需要的數據。
看過JsonTokenizer和JsonParser類的核心部分後能讓我們理解分析和解析的工作方式。為了充分理解代碼是如何運作的,你可以看看完整的JsonTokenizer和JsonParser實現。他們每個都不到200行,所以它們應該是易於理解的。
JsonNavigator是一個元素訪問組件。它可以幫助我們訪問 JsonParser 和JsonParser2創建的元素索引。兩個組件產生的索引是相同的,所以來自兩個組件的任何一個索引都可以。如下是代碼示例:
JsonNavigator jsonNavigator = new JsonNavigator(dataBuffer, elementBuffer);
一旦JsonNavigator創建,您可以使用它的導航方法,next(),previous()等等。你可以使用asString(),asInt()和asLong()來提取數據。你可以使用isEqualUnencoded(String)來比較在數據緩沖器中元素的常量字符串。
使用JsonNavigator類看起來非常類似於使用GSON流化API。可以比較一下AllBenchmarks類的gsonStreamBuildObject(Reader)方法,和JsonObjectBuilder類parseJsonObject(JsonNavigator)方法。
他們看起來很相似,不是麼? 只是,parseJsonObject()方法能夠使用JsonNavigator的一些優化(在本文後面討論),像數組中基本元素計數,以及對JSON字段名稱更快的字符串比較。
VTD-XML對StAX,SAX和DOM解析器等XML解析器做了的廣泛的基准化比較測試。在核心性能上,VTD-XML贏得了他們。
為了對索引疊加解析器的性能建立一些信任依據,我已經參考GSON實現了我的JSON解析器。本文的第一個版本只測算了解析一個JSON文件的速度與通過GSON反射構造對象。基於讀者的意見,我現在已經擴大了基准,基於四種不同的模式來測算GSON:
1、訪問JSON文件所有元素,但不做任何數據處理。
2、訪問JSON文件所有元素,並建立一個JSONObject。
3、解析JSON文件,並構建了一個Map對象。
4、解析JSON文件,並使用反射它建立一個JSONObject。
請記住,GSON是一個高質量的產品,經過了很好的測試,也具有良好的錯誤報告等。只有我的JSON解析器是在概念驗證級別。基准測試只是用來獲得性能上的差異指標。他們不是最終的數據。也請閱讀下文的基准討論。
如下是一些基准結構化組織的細節:
· 為了平衡JIT,盡量減小一次性開銷,諸如此類。JSON輸入完成1000萬次的小文件解析,100萬次中等文件和大文件。
· 基准化測試分別重復三個不同類型的文件, 看看解析器如何做小的,中等和大文件。上述文件類型大小分別為58字節,783字節和1854字節。這意味著先迭代1000萬次的一個小文件,進行測算。然後是中等文件,最後在大文件。上述文件存於GitHub庫的數據目錄中。
· 在解析和測算前,文件完全裝載進內存中。這樣解析耗時不包含裝載時間。
· 1000萬次迭代(或100萬次迭代)測算都是在自己的進程中進行。這意味著,每個文件在單獨的進程進行解析。一個過程運行一次。每個文件都測算3次。解析文件1000萬次的過程啟動和停止3次。流程是順序進行的,而不是並行。
如下是毫秒級的執行時間數據:

如你所見,索引疊加實現(JsonParser和JsonParser2)比Gson更快。下面我們將討論一下產生上述結果的原因的推測。
GSON Streaming API並非更快的主要原因是當遍歷時所有數據都從流中抽取,即使不需要這些數據。每一個令牌變成一個string,int,double等,存在消耗。這也是為什麼用Gson streaming API解析JSON文件和構建JsonOject和訪問元素本身是一樣快。 唯一增加的顯式時間是JsonObject內部的JsonObject和數組的實例化。
數據獲取不能解釋這一切,盡管,使用JsonParser2構建一個JSONObject比使用Gson streaming API構建JSONObject幾乎快兩倍。如下說明了一些我看到的索引疊加解析器比流式解析器的性能優勢:
首先,如果你看一下小的和大的文件的測試數據,每一次解析式GSON都存在一次性開銷。 JsonParser2+ JsonParser和GSON基准測試間的性能差異在小的文件上更明顯。可能原因是theCharArrayReader創建,或類似的事情。也可能是GSON內部的某項處理。
第二,索引疊加解析器可以允許你控制你想抽取的數據量。這個讓你更細粒度的控制解析器的性能。
第三, 若一個字符串令牌含有需要手動從UTF-8轉換為UTF-16的轉義字符(如“\”\ t\ N \ R“),JsonParser和JsonParser2在分析時能夠識別。如果一個字符串令牌不包含轉義字符,JsonNavigator可以用一個比它們更快的字符串創建機制。
第四,JsonNavigator能夠讓數據緩沖區中的數據的字符串比較更快。 當你需要檢查字段名是否等於常量名時,非常方便。使用Gson's streaming API,你將需將字段名抽取為一個String對象,並比較常量字符串和String對象。JsonNavigator可以直接比較常量字符串和數據緩沖區中的字符,而無需先創建一個String對象。這可以節省一個String對象的實例化,並從數據緩沖區中的數據復制到一個String對象的時間,它是僅用於比較(如檢查JSON字段名稱是否等於“key”或“name”或其它)。JsonNavigator使用方式如下所示:
if(jsonNavigator.isEqualUnencoded("fieldName")) { }
第五,JsonNavigator可以在其索引向前遍歷,計數包含原始值(字符串,數字,布爾值,空值等,但不包含對象或嵌套數組)數組中的元素數量。當你不知道數組包含有多少個元素,我們通常抽取元素並把它們放到一個List中。一旦你遇到數組結束的標記,將List轉成數組。這意味著構建了非必要的List對象。此外,即使該數組包含原始值,如整數或布爾值,所有抽取的數據也必須要插入到List對象。抽取數值插入List時進行了不必要的對象創建(至少是不必要的自動裝箱)。再次,創建基礎值數組時,所有的對象都必須再次轉換成原始類型,然後插入到數組中。如下所示是Gson streaming API工作代碼:
List<Integer> elements = new ArrayList<Integer>();
reader.beginArray();
while (reader.hasNext()) {
elements.add(reader.nextInt());
}
reader.endArray();
int[] ints = new int[elements.size()];
for (int i = 0; i < ints.length; i++) {
ints[i] = elements.get(i);
}
當知道數組包含的元素數時,我們可以立即創建最終的Java數組,然後將原始值直接放入數組。在插入數值到數組時,這節省了List實例化和構建,原始值自動裝箱和對象轉換到原始值的時間。如下所示是使用JsonNavigator功能相同的代碼:
int[] ints = new int[jsonNavigator.countPrimitiveArrayElements()];
for (int i = 0, n = ints.length; i < n; i++) {
ints[i] = jsonNavigator.asInt();
jsonNavigator.next();
}
即使剛剛從JSON數組構建List對象,知道元素的個數可以讓你從一開始就能正確的實例化一個ArrayList對象。這樣,你就避免了在達到預設阈值時需動態調整ArrayList大小的麻煩。如下是示例代碼:
List<String> strings = new ArrayList<String>(jsonNavigator.countPrimitiveArrayElements());
jsonNavigator.next(); // skip over array start.
while (ElementTypes.JSON_ARRAY_END != jsonNavigator.type()) {
strings.add(jsonNavigator.asString());
jsonNavigator.next();
}
jsonNavigator.next(); //skip over array end.
第六,當需訪問原始數據緩沖區時,可以在很多地方用ropes代替String對象。一個rope是一個含有char數組引用的一個字符串令牌,有起始位置和長度。可以進行字符串比較,就像一個字符串復制rope等。某些操作可能用rope要比字符串對象快。因為不復制原始數據,它們還占用更少的內存。
第七,如果需要做很多來回的數據訪問,您可以創建更高級的索引。 VTD-XML中的索引包含元素的縮進層次,以及同一層的下一個元素(下一個同級)的引用,帶有更高縮進層的第一個元素(初始元素),等等。這些都是增加到線性解析器元素索引頂部的整型索引。這種額外的索引可以讓已解析數據的遍歷速度更快。
若看看JsonParser和JsonParser2代碼,你將看到更快的JsonParser2比JsonParser更糟糕的錯誤報告。當分析和解析階段一分為二時,良好的數據驗證和錯誤報告更易於實現。
通常情況下,這種差異將觸發爭論,在解析器的實現進行取捨時,優先考慮性能還是錯誤報告。然而,在索引疊加解析器中,這一討論是沒有必要的。
因為原始數據始終以其完整的形式存在於內存中,你可以同時具有快和慢的解析器解析相同的數據。您可以快速啟動快的解析器,若解析失敗,您可以使用較慢的解析器來檢測其中輸入數據中的錯誤位置。當快的解析器失敗時,只要將原始數據交給較慢的解析器。基於這種方式,你可以獲得兩個解析的優點。
基於數據(GSON)創建的對象樹與僅標識在數據中找到的數據索引進行比較,而沒有討論比較的標的,這是不公平的比較。
在應用程序內部解析文件通常需要如下步驟:

首先是數據從硬盤或者網絡上裝載。接著,解碼數據,例如從UTF-8到UTF-16。第三步,解析數據。第四步,處理數據。
為了只測量原始的解析器速度, 我預裝載待解析的文件到內存。 該基准測試的代碼沒有以任何方式處理數據。盡管該基准化測試只是測試基礎的解析速度,在運行的應用程序中,性能差異並沒有轉化成性能顯著提高。如下是原因:
流式解析器總是能在所有數據裝載進內存前開始解析數據。我的JSON解析器現在實現版本不能這樣做。這意味著即使它在基礎解析基准上更快,在現實運行的應用程序中,我的解析器必須等待數據裝載,這將減慢整體的處理速度。如下圖說明:

為了加速整體解析速度,你很可能修改我的解析器為數據裝載時即可以解析數據。但是很可能會減慢基本解析性能。但整體速度仍可能更快。
此外,通過在執行的基准測試之前數據預加載到內存中,我也跳過數據解碼步驟。數據從UTF-8轉碼為UTF-16是也存在消耗。在現實應用程序中,你不可以跳過這一步。每個待解析的文件來必須要解碼。這是所有解析器都要支持的一點。流式解析器可以在讀數據時進行解碼。索引疊加分析器也可以在讀取數據到緩沖區時進行解碼。
VTD-XML 和Jackson (另一個JSON解析器)使用另一種技術。它們不會解碼所有的原始數據。相反,它們直接在原始數據上進行分析,消費各種數據格式,如(ASCII,UTF-8等)。這可以節省昂貴的解碼步驟,解碼要使用相當復雜分析器。
一般來說,要想知道那個解析器在你的應用程序更快,需要基於你真實需要解析的數據的基准上進行全量測試。
我聽到的一個反對索引疊加分析器的論點是,要能夠指向原始數據,而不是將其抽取到一個對象樹,解析時保持所有數據在內存中是必要的。在處理大文件時,這將導致內存消耗暴增。
一般來說,流式分析器(如SAX或StAX)在解析大文件時將整個文件存入內存。然而,只有文件中的數據可以以更小的塊進行解析和處理,每個塊都是獨立進行處理的,這種說法才是對的。例如,一個大的XML文件包含一列元素,其中每一個元素都可以單獨被解析和處理(如日志記錄列表)。如果數據能以獨立的塊進行解析,你可以實現一個工作良好的索引疊加解析器。
如果文件不能以獨立塊進行解析,你仍然需要提取必要的信息到一些結構,這些結構可以為處理後面塊的代碼進行訪問。盡管使用流式解析器可以做到這一點,你也可以使用索引疊加解析器進行處理。
從輸入數據中創建對象樹的解析器通常會消耗比原數據大小的對象樹更多的內存。對象實例相關聯的內存開銷,加上需要保持對象之間的引用的額外數據,這是主要原因。
此外,因為所有的數據都需要同時在內存中,你需要解析前分配一個數據緩沖區,大到足以容納所有的數據。但是,當你開始解析它們時,你並不知道文件大小,如何辦呢?
假如你有一個網頁應用程序(如Web服務,或者服務端應用),用戶使用它上傳文件。你不可能知道文件大小,所以開始解析前無法分配合適的緩存給它。基於安全考慮,你應該總是設置一個最大允許文件大小。否則,用戶可以通過上傳超大文件讓你的應用崩潰。或者,他們可能甚至寫一個程序,偽裝成上傳文件的浏覽器,並讓該程序不停地向服務器發送數據。您可以分配一個緩沖區適合所允許的最大文件大小。這樣,你的緩沖區不會因有效文件耗光。如果它耗光了空間,那說明你的用戶已經上傳了過大的文件。