引言
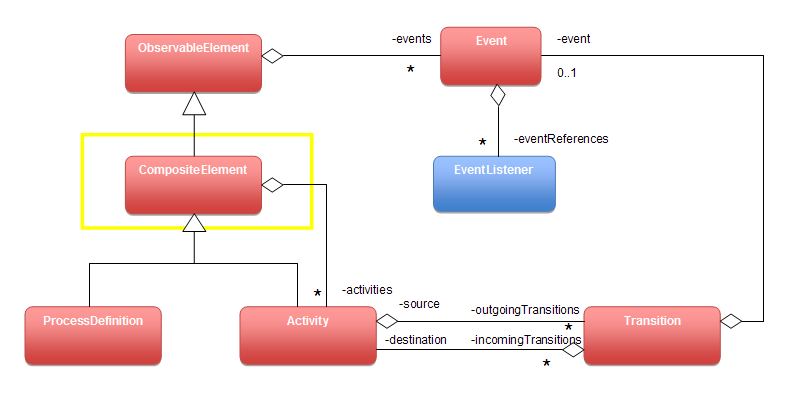
在上一章我們已經探討過hotspot上垃圾搜集器的實現,一共有六種實現六種組合。本次LZ與各位一起探討下這六種搜集器各自的威力以及組合的威力如何。
為了方便各位的觀看與對比,LZ決定采用當初寫設計模式時使用的方式,針對某些搜集器,分幾個維度去解釋這些搜集器。
client模式與server模式
在介紹本章內容之前,要說一下JVM的兩種模式,一種是client模式,一種是server模式。我們平時開發使用的模式默認是client模式,也可以使用命令行參數-server強制開啟server模式,兩者最大的區別在於在server模式下JVM做了很多優化。
server模式下的JAVA應用程序啟動較慢,不過由於server模式下JVM所做的優化,在程序長時間運行下,運行速度將會越來越快。相反,client模式下的JAVA應用程序雖然啟動快,但不適合長時間運行,若是運行時間較長的話,則會在性能上明顯低於server模式。
搜集器詳解
以下我們先探討一下單個垃圾搜集器的相關內容,最後我們再簡單的談一下組合之後,各個組合的特點。
Serial Garbage Collector
算法:采用復制算法
內存區域:針對新生代設計
執行方式:單線程、串行
執行過程:當新生代內存不夠用時,先暫停全部用戶程序,然後開啟一條GC線程使用復制算法對垃圾進行回收,這一過程中可能會有一些對象提升到年老代
特點:由於單線程運行,且整個GC階段都要暫停用戶程序,因此會造成應用程序停頓時間較長,但對於小規模的程序來說,卻非常適合。
適用場景:平時的開發與調試程序使用,以及桌面應用交互程序。
開啟參數:-XX:+UseSerialGC(client模式默認值)
Serial Old Garbage Collector
這裡針對serial old搜集器不再列舉各個維度的特點,因為它與serial搜集器是一樣的,區別是它是針對年老代而設計的,因此采用標記/整理算法。對於其余的維度特點,serial old與serial搜集器一模一樣。
ParNew Garbage Collector
算法:采用復制算法
內存區域:針對新生代設計
執行方式:多線程、並行
執行過程:當新生代內存不夠用時,先暫停全部用戶程序,然後開啟若干條GC線程使用復制算法並行進行垃圾回收,這一過程中可能會有一些對象提升到年老代
特點:采用多線程並行運行,因此會對系統的內核處理器數目比較敏感,至少需要多於一個的處理器,有幾個處理器就會開幾個線程(不過線程數是可以使用參數-XX:ParallelGCThreads=<N>控制的),因此只適合於多核多處理器的系統。盡管整個GC階段還是要暫停用戶程序,但多線程並行處理並不會造成太長的停頓時間。因此就吞吐量來說,ParNew要大於serial,在處理器越多的時候,效果越明顯。但是這並非絕對,對於單個處理器來說,由於並行執行的開銷(比如同步),ParNew的性能將會低於serial搜集器。不僅是單個處理器的時候,如果在容量較小的堆上,甚至在兩個處理器的情況下,ParNew的性能都並非一定可以高過serial。
適用場景:在中到大型的堆上,且系統處理器至少多於一個的情況
開啟參數:-XX:+UseParNewGC
Parallel Scavenge Garbage Collector
這個搜集器與ParNew幾乎一模一樣,都是針對新生代設計,采用復制算法的並行搜集器。它與ParNew最大的不同就是可設置的參數不一樣,它可以讓我們更精確的控制GC停頓時間以及吞吐量。
URL:http://www.bianceng.cn/Programming/Java/201410/45825.htm
parallel scavenge搜集器提供參數主要包括控制最大的停頓時間(使用-XX:MaxGCPauseMillis=<N>),以及控制吞吐量(使用-XX:GCTimeRatio=<N>)。由此可以看出,parallel scavenge就是為了提供吞吐量控制的搜集器。
不過千萬不要以為把最大停頓時間調的越小越好,或者吞吐量越大越好,在使用parallel scavenge搜集器時,主要有三個性能指標,最大停頓時間、吞吐量以及新生代區域的最小值。
parallel scavenge搜集器具有相應的調節策略,它將會優先滿足最大停頓時間的目標,次之是吞吐量,最後才是新生代區域的最小值。
因此,如果將最大停頓時間調的過小,將會犧牲整體的吞吐量以及新生代大小來滿足你的私欲。手心手背都是肉,我們最好還是不要這麼干。不過parallel scavenge有一個參數可以讓parallel scavenge搜集器全權接手內存區域大小的調節,這其中還包括了晉升為年老代(可使用-XX:MaxTenuringThreshold=n調節)的年齡,也就是使用-XX:UseAdaptiveSizePolicy打開內存區域大小自適應策略。
parallel scavenge搜集器可使用參數-XX:+UseParallelGC開啟,同時它也是server模式下默認的新生代搜集器。
Parallel Old Garbage Collector
Parallel Old與ParNew或者Parallel Scavenge的關系就好似serial與serial old一樣,相互之間的區別並不大,只不過parallel old是針對年老代設計的並行搜集器而已,因此它采用標記/整理算法。
Parallel Old搜集器還有一個重要的意義就是,它是除了serial old以外唯一一個可以與parallel scavenge搭配工作的年老代搜集器,因此為了避免serial old影響parallel scavenge可控制吞吐量的名聲,parallel old就作為了parallel scavenge真正意義上的搭檔。
它可以使用參數-XX:-UseParallelOldGC開啟,不過在JDK6以後,它也是在開啟parallel scavenge之後默認的年老代搜集器。
Concurrent Mark Sweep Garbage Collector
concurrent mark sweep(以下簡稱CMS)搜集器是唯一一個真正意義上實現了應用程序與GC線程一起工作(一起是針對客戶而言,而並不一定是真正的一起,有可能是快速交替)的搜集器。
CMS是針對年老代設計的搜集器,並采用標記/清除算法,它也是唯一一個在年老代采用標記/清除算法的搜集器。
采用標記/清除算法是因為它特殊的處理方式造成的,它的處理分為四個階段。
1、初始標記:需要暫停應用程序,快速標記存活對象。
2、並發標記:恢復應用程序,並發跟蹤GC Roots。
3、重新標記:需要暫停應用程序,重新標記跟蹤遺漏的對象。
4、並發清除:恢復應用程序,並發清除未標記的垃圾對象。
它比原來的標記/清除算法復雜了點,主要表現在並發標記和並發清除這兩個階段,而這兩個階段也是整個GC階段中耗時最長的階段,不過由於這兩個階段皆是與應用程序並發執行的,因此CMS搜集器造成的停頓時間是非常短暫的。這點還是比較好理解的。
不過它的缺點也是要簡單提一下的,主要有以下幾點。
1、由於GC線程與應用程序並發執行時會搶占CPU資源,因此會造成整體的吞吐量下降。也就是說,從吞吐量的指標上來說,CMS搜集器是要弱於parallel scavenge搜集器的。LZ這裡從oracle官網上摘錄下一段關於CMS的描述,裡面提到CMS性能與CPU個數的關系。
Since at least one processor is utilized for garbage collection during the concurrent phases, the concurrent collector does not normally provide any benefit on a uniprocessor (single-core) machine. However, there is a separate mode available that can achieve low pauses on systems with only one or two processors; see incremental mode below for details.
LZ的英文很一般(四級都沒過,慚愧,0.0),不過在借助工具的情況下也能大致翻譯出來這段話的意思,如下。
中文大意:由於在並發階段垃圾搜集至少使用了一個處理器,因此在單處理器的情況下使用並發搜集器,將得不到任何好處。不過,在單個或兩個處理器的系統上,有一種獨立的方式可以有效的達到低停頓的目的,詳情見下方的增量模式(incremental mode)。
很明顯,oracle的文檔指出,在單處理器的情況下,並發搜集器會因為搶占處理器,而造成性能降低。最後給出了一種增量模式的處理方式,不過在《深入理解JAVA虛擬機》一書中指出,增量模式已經被定義為不推薦使用。由於LZ摘錄的這段官方介紹是基於JDK5.0的介紹,而《深入理解JAVA虛擬機》一書中則是指的JDK6.0的版本,因此LZ暫且猜測,增量模式是在JDK6.0發布的時候被廢棄了,不過這個廢棄的時間或者說版本其實已經不重要了。
2、標記/清除很大的一個缺點,那就是內存碎片的存在。因此JVM提供了-XX:+UseCMSCompactAtFullCollection參數用於在全局GC(full GC)後進行一次碎片整理的工作,由於每次全局GC後都進行碎片整理會較大的影響停頓時間,JVM又提供了參數-XX:CMSFullGCsBeforeCompaction去控制在幾次全局GC後會進行碎片整理。
3、CMS最後一個缺點涉及到一個術語---並發模式失敗(Concurrent Mode Failure)。對於這個術語,官方是這樣解釋的。
if the concurrent collector is unable to finish reclaiming the unreachable objects before the tenured generation fills up, or if an allocation cannot be satisfied with the available free space blocks in the tenured generation, then the application is paused and the collection is completed with all the application threads stopped.The inability to complete a collection concurrently is referred to as concurrent mode failure and indicates the need to adjust the concurrent collector parameters.
中文大意:如果並發搜集器不能在年老代填滿之前完成不可達(unreachable)對象的回收,或者年老代中有效的空閒內存空間不能滿足某一個內存的分配請求,此時應用會被暫停,並在此暫停期間開始垃圾回收,直到回收完成才會恢復應用程序。這種無法並發完成搜集的情況就成為並發模式失敗(concurrent mode failure),而且這種情況的發生也意味著我們需要調節並發搜集器的參數了。
上面兩個情況感覺有點重復,不能滿足內存的分配請求不就是在年老代填滿之前,沒有完成對象回收造成的嗎?
這裡LZ個人的理解是,年老代填滿之前無法完成對象回收是指年老代在並發清除階段清除不及時,因此造成的空閒內存不足。而不能滿足內存的分配請求,則主要指的是新生代在提升到年老代時,由於年老代的內存碎片過多,導致一些分配由於沒有連續的內存無法滿足。
實際上,在並發模式失敗的情況下,serial old會作為備選搜集器,進行一次全局GC(Full GC),因此serial old也算是CMS的“替補”。顯然,由於serial old的介入,會造成較大的停頓時間。
為了盡量避免並發模式失敗發生,我們可以調節-XX:CMSInitiatingOccupancyFraction=<N>參數,去控制當年老代的內存占用達到多少的時候(N%),便開啟並發搜集器開始回收年老代。
組合的威力
上面我們已經簡單的介紹了各個搜集器的特點,下面LZ與各位分享三個典型的組合,其余三種組合一般不常用。
serial & serial old
這個組合是我們最常見的組合之一,也是client模式下的默認垃圾搜集器組合,也可以使用參數-XX:+UseSerialGC強制開啟。
由於它實現相對簡單,沒有線程相關的額外開銷(主要指線程切換與同步),因此非常適合運行於客戶端PC的小型應用程序,或者桌面應用程序(比如swing編寫的用戶界面程序),以及我們平時的開發、調試、測試等。
上面三種情況都有共同的特點。
1、由於都是在PC上運行,因此配置一般不會太高,或者說處理器個數不會太多。
2、上面幾種情況的應用程序都不會運行太久。
3、規模不會太大,也就是說,堆相對較小,搜集起來也比較快,停頓時間會比較短。
Parallel Scavenge & Parallel Old
這個組合我們並不常見,畢竟它不會出現在我們平時的開發當中,但是它卻是很多對吞吐量(throughout)要求較高或者對停頓時間(pause time)要求不高的應用程序的首選,並且這個組合是server模式下的默認組合(JDK6或JDK6之後)。當然,它也可以使用-XX:+UseParallelGC參數強制開啟。
該組合無論是新生代還是年老代都采用並行搜集,因此停頓時間較短,系統的整體吞吐量較高。它適用於一些需要長期運行且對吞吐量有一定要求的後台程序。
這些運行於後台的程序都有以下特點。
1、系統配置較高,通常情況下至少四核(以目前的硬件水平為准)。
2、對吞吐量要求較高,或需要達到一定的量。
3、應用程序運行時間較長。
4、應用程序規模較大,一般是中到大型的堆。
ParNew & CMS(Serial Old作為替補)
這個組合與上面的並行組合一樣,在平時的開發當中都不常見,而它則是對相應時間(response time)要求較高的應用程序的首選。該組合需要使用參數-XX:+UseConcMarkSweepGC開啟。
該組合在新生代采用並行搜集器,因此新生代的GC速度會非常快,停頓時間很短。而年老代的GC采用並發搜集,大部分垃圾搜集的時間裡,GC線程都是與應用程序並發執行的,因此造成的停頓時間依然很短。它適用於一些需要長期運行且對相應時間有一定要求的後台程序。
這些運行於後台的程序的特點與並行模式下的後台程序十分類似,不同的是第二點,采用ParNew & CMS組合的後台應用程序,一般都對相應時間有一定要求,最典型的就是我們的WEB應用程序。
結束語
本次LZ整理了各個搜集器的特點與各個組合的特點,此外,還有剩下的三種組合LZ這裡沒有提到,原因是這三種組合都不是特別常用,或者可以說幾乎不用,因為這三個組合都給人一種四不像的感覺,而且效果也確實不好。
希望本文能給各位帶來一些幫助,感謝各位的收看。
作者:zuoxiaolong(左潇龍)
出處:博客園左潇龍的技術博客--http://www.cnblogs.com/zuoxiaolong