背景 :
在使用搜索引擎和電商的搜索功能時,大家一定遇到過這樣的情景:我想搜索博客園,可不小心輸成博客員了,不用擔心搜不到你想要的結果,因為建立在大數據上的搜索引擎會幫你自動糾錯,就這個例子Google和Baidu返回給我的分別是:
顯示以下查詢字詞的結果: 博客園 和 您要找的是不是: 博客園 ,他們都做到了自動糾錯,關於自動糾錯我之前也寫過一篇陋文,當時是自己實現的N-Gram模型,但是效果不是太好,主要是針對不同的語料庫算法的精確度是不一樣的,我想換個算法試試看,目前主流的計算串間的距離(相反的,你也可以理解為相似度)是Levenshtein,當要實現時,發現lucene已經做了這個事,那咱就站在巨人的肩膀上成長吧。
引用包:
lucene-core-3.1.0.jar + lucene-spellchecker-3.1.0.jar,你可以在這裡得到
使用示例:
在類SpellCorrector的main方法中加入以下代碼
//創建目錄
File dict = new File("");
Directory directory = FSDirectory.open(dict);
//實例化拼寫檢查器
SpellChecker sp = new SpellChecker(directory);
//創建詞典
File dictionary = new File(SpellCorrecter.class.getResource("dictionary.txt").getFile());
//對詞典進行索引
sp.indexDictionary(new PlainTextDictionary(dictionary));
//有錯別字的搜索
String search = "非常勿擾";
//建議個數,這裡我只想要最接近的那一個,你可以設置成別的數字,如3
// 查看本欄目
紅顏血淚
冰上火一般的激情
在敵之手
馳風競艇王第二部
釣金龜
潇湘路一號
戲裡戲外第二季
草原狼爵士樂
拯救大兵瑞恩
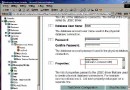
好了,接下來就直接運行吧,見下圖:
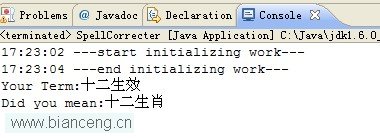
完整代碼和字典在這裡(限於工作原因,字典只保留部分電影名稱,你可以用你自己的語料庫)