1.背景:
這周由於項目需要對搜索框中輸入的錯誤影片名進行校正處理,以提升搜索命中率和用戶體驗,研究了一下中文文本自動糾錯(專業點講是校對,proofread),並初步實現了該功能,特此記錄。
2.簡介:
中文輸入錯誤的校對與更正是指在輸入不常見或者錯誤文字時系統提示文字有誤,最簡單的例子就是在word裡打字時會有紅色下劃線提示。實現該功能目前主要有兩大思路:
(1) 基於大量字典的分詞法:主要是將待分析的漢字串與一個很大的“機器詞典”中的詞條進行匹配,若在詞典中找到則匹配成功;該方法易於實現,比較適用於輸入的漢字串
屬於某個或某幾個領域的名詞或名稱;
(2) 基於統計信息的分詞法:常用的是N-Gram語言模型,其實就是N-1階Markov(馬爾科夫)模型;在此簡介一下該模型:
上式是Byes公式,表明字符串X1X2……Xm出現的概率是每個字單獨出現的條件概率之積,為了簡化計算假設字Xi的出現僅與前面緊挨著的N-1個字符有關,則上面的公式變為:
這就是N-1階Markov(馬爾科夫)模型,計算出概率後與一個阈值對比,若小於該阈值則提示該字符串拼寫有誤。
3.實現:
由於本人項目針對的輸入漢字串基本上是影視劇名稱以及綜藝動漫節目的名字,語料庫的范圍相對穩定些,所以這裡采用2-Gram即二元語言模型與字典分詞相結合的方法;
先說下思路:
對語料庫進行分詞處理 —>計算二元詞條出現概率(在語料庫的樣本下,用詞條出現的頻率代替) —>對待分析的漢字串分詞並找出最大連續字符串和第二大連續字符串 —>
利用最大和第二大連續字符串與語料庫的影片名稱匹配—>部分匹配則現實拼寫有誤並返回更正的字符串(所以字典很重要)
備注:分詞這裡用ICTCLAS Java API
上代碼:
創建類ChineseWordProofread
3.1 初始化分詞包並對影片語料庫進行分詞處理
public ICTCLAS2011 initWordSegmentation(){
ICTCLAS2011 wordSeg = new ICTCLAS2011();
try{
String argu = "F:\\Java\\workspace\\wordProofread"; //set your project path
System.out.println("ICTCLAS_Init");
if (ICTCLAS2011.ICTCLAS_Init(argu.getBytes("GB2312"),0) == false)
{
System.out.println("Init Fail!");
//return null;
}
/*
* 設置詞性標注集
ID 代表詞性集
1 計算所一級標注集
0 計算所二級標注集
2 北大二級標注集
3 北大一級標注集
*/
wordSeg.ICTCLAS_SetPOSmap(2);
}catch (Exception ex){
System.out.println("words segmentation initialization failed");
System.exit(-1);
}
return wordSeg;
}
public boolean wordSegmentate(String argu1,String argu2){
boolean ictclasFileProcess = false;
try{
//文件分詞
ictclasFileProcess = wordSeg.ICTCLAS_FileProcess(argu1.getBytes("GB2312"), argu2.getBytes("GB2312"), 0);
//ICTCLAS2011.ICTCLAS_Exit();
}catch (Exception ex){
System.out.println("file process segmentation failed");
System.exit(-1);
}
return ictclasFileProcess;
}
3.2 計算詞條(tokens)出現的頻率
public Map<String,Integer> calculateTokenCount(String afterWordSegFile){
Map<String,Integer> wordCountMap = new HashMap<String,Integer>();
File movieInfoFile = new File(afterWordSegFile);
BufferedReader movieBR = null;
try {
movieBR = new BufferedReader(new FileReader(movieInfoFile));
} catch (FileNotFoundException e) {
System.out.println("movie_result.txt file not found");
e.printStackTrace();
}
String wordsline = null;
try {
while ((wordsline=movieBR.readLine()) != null){
String[] words = wordsline.trim().split(" ");
for (int i=0;i<words.length;i++){
int wordCount = wordCountMap.get(words[i])==null ? 0:wordCountMap.get(words[i]);
wordCountMap.put(words[i], wordCount+1);
totalTokensCount += 1;
if (words.length > 1 && i < words.length-1){
StringBuffer wordStrBuf = new StringBuffer();
wordStrBuf.append(words[i]).append(words[i+1]);
int wordStrCount = wordCountMap.get(wordStrBuf.toString())==null ? 0:wordCountMap.get(wordStrBuf.toString());
wordCountMap.put(wordStrBuf.toString(), wordStrCount+1);
totalTokensCount += 1;
}
}
}
} catch (IOException e) {
System.out.println("read movie_result.txt file failed");
e.printStackTrace();
}
return wordCountMap;
}
3.3 找出待分析字符串中的正確tokens
public Map<String,Integer> calculateTokenCount(String afterWordSegFile){
Map<String,Integer> wordCountMap = new HashMap<String,Integer>();
File movieInfoFile = new File(afterWordSegFile);
BufferedReader movieBR = null;
try {
movieBR = new BufferedReader(new FileReader(movieInfoFile));
} catch (FileNotFoundException e) {
System.out.println("movie_result.txt file not found");
e.printStackTrace();
}
String wordsline = null;
try {
while ((wordsline=movieBR.readLine()) != null){
String[] words = wordsline.trim().split(" ");
for (int i=0;i<words.length;i++){
int wordCount = wordCountMap.get(words[i])==null ? 0:wordCountMap.get(words[i]);
wordCountMap.put(words[i], wordCount+1);
totalTokensCount += 1;
if (words.length > 1 && i < words.length-1){
StringBuffer wordStrBuf = new StringBuffer();
wordStrBuf.append(words[i]).append(words[i+1]);
int wordStrCount = wordCountMap.get(wordStrBuf.toString())==null ? 0:wordCountMap.get(wordStrBuf.toString());
wordCountMap.put(wordStrBuf.toString(), wordStrCount+1);
totalTokensCount += 1;
}
}
}
} catch (IOException e) {
System.out.println("read movie_result.txt file failed");
e.printStackTrace();
}
return wordCountMap;
}
3.4 得到最大連續和第二大連續字符串(也可能為單個字符)
public String[] getMaxAndSecondMaxSequnce(String[] sInputResult){
List<String> correctTokens = getCorrectTokens(sInputResult);
//TODO
System.out.println(correctTokens);
String[] maxAndSecondMaxSeq = new String[2];
if (correctTokens.size() == 0) return null;
else if (correctTokens.size() == 1){
maxAndSecondMaxSeq[0]=correctTokens.get(0);
maxAndSecondMaxSeq[1]=correctTokens.get(0);
return maxAndSecondMaxSeq;
}
String maxSequence = correctTokens.get(0);
String maxSequence2 = correctTokens.get(correctTokens.size()-1);
String littleword = "";
for (int i=1;i<correctTokens.size();i++){
//System.out.println(correctTokens);
if (correctTokens.get(i).length() > maxSequence.length()){
maxSequence = correctTokens.get(i);
} else if (correctTokens.get(i).length() == maxSequence.length()){
//select the word with greater probability for single-word
if (correctTokens.get(i).length()==1){
if (probBetweenTowTokens(correctTokens.get(i)) > probBetweenTowTokens(maxSequence)) {
maxSequence2 = correctTokens.get(i);
}
}
//select words with smaller probability for multi-word, because the smaller has more self information
else if (correctTokens.get(i).length()>1){
if (probBetweenTowTokens(correctTokens.get(i)) <= probBetweenTowTokens(maxSequence)) {
maxSequence2 = correctTokens.get(i);
}
}
} else if (correctTokens.get(i).length() > maxSequence2.length()){
maxSequence2 = correctTokens.get(i);
} else if (correctTokens.get(i).length() == maxSequence2.length()){
if (probBetweenTowTokens(correctTokens.get(i)) > probBetweenTowTokens(maxSequence2)){
maxSequence2 = correctTokens.get(i);
}
}
}
//TODO
System.out.println(maxSequence+" : "+maxSequence2);
//delete the sub-word from a string
if (maxSequence2.length() == maxSequence.length()){
int maxseqvaluableTokens = maxSequence.length();
int maxseq2valuableTokens = maxSequence2.length();
float min_truncate_prob_a = 0 ;
float min_truncate_prob_b = 0;
String aword = "";
String bword = "";
for (int i=0;i<correctTokens.size();i++){
float tokenprob = probBetweenTowTokens(correctTokens.get(i));
if ((!maxSequence.equals(correctTokens.get(i))) && maxSequence.contains(correctTokens.get(i))){
if ( tokenprob >= min_truncate_prob_a){
min_truncate_prob_a = tokenprob ;
aword = correctTokens.get(i);
}
}
else if ((!maxSequence2.equals(correctTokens.get(i))) && maxSequence2.contains(correctTokens.get(i))){
if (tokenprob >= min_truncate_prob_b){
min_truncate_prob_b = tokenprob;
bword = correctTokens.get(i);
}
}
}
//TODO
System.out.println(aword+" VS "+bword);
System.out.println(min_truncate_prob_a+" VS "+min_truncate_prob_b);
if (aword.length()>0 && min_truncate_prob_a < min_truncate_prob_b){
maxseqvaluableTokens -= 1 ;
littleword = maxSequence.replace(aword,"");
}else {
maxseq2valuableTokens -= 1 ;
String temp = maxSequence2;
if (maxSequence.contains(temp.replace(bword, ""))){
littleword = maxSequence2;
}
else littleword = maxSequence2.replace(bword,"");
}
if (maxseqvaluableTokens < maxseq2valuableTokens){
maxSequence = maxSequence2;
maxSequence2 = littleword;
}else {
maxSequence2 = littleword;
}
}
maxAndSecondMaxSeq[0] = maxSequence;
maxAndSecondMaxSeq[1] = maxSequence2;
return maxAndSecondMaxSeq ;
}
3.5 返回更正列表
public List<String> proofreadAndSuggest(String sInput){
//List<String> correctTokens = new ArrayList<String>();
List<String> correctedList = new ArrayList<String>();
List<String> crtTempList = new ArrayList<String>();
//TODO
Calendar startProcess = Calendar.getInstance();
char[] str2char = sInput.toCharArray();
String[] sInputResult = new String[str2char.length];//cwp.wordSegmentate(sInput);
for (int t=0;t<str2char.length;t++){
sInputResult[t] = String.valueOf(str2char[t]);
}
//String[] sInputResult = cwp.wordSegmentate(sInput);
//System.out.println(sInputResult);
// 查看本欄目
public static void main(String[] args) {
String argu1 = "movie.txt"; //movies name file
String argu2 = "movie_result.txt"; //words after segmenting name of all movies
SimpleDateFormat sdf=new SimpleDateFormat("HH:mm:ss");
String startInitTime = sdf.format(new java.util.Date());
System.out.println(startInitTime+" ---start initializing work---");
ChineseWordProofread cwp = new ChineseWordProofread(argu1,argu2);
String endInitTime = sdf.format(new java.util.Date());
System.out.println(endInitTime+" ---end initializing work---");
Scanner scanner = new Scanner(System.in);
while(true){
System.out.print("請輸入影片名:");
String input = scanner.next();
if (input.equals("EXIT")) break;
cwp.proofreadAndSuggest(input);
}
scanner.close();
}
在我的機器上實驗結果如下:
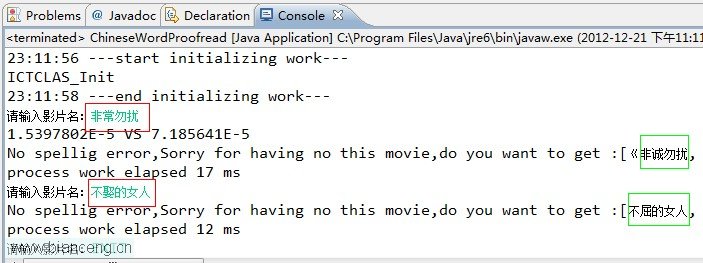
最後要說的是我用的語料庫沒有做太多處理,所以最後出來的有很多正確的結果,比如非誠勿擾會有《非誠勿擾十二月合集》等,這些只要在影片語料庫上處理下即可;
還有就是該模型不適合大規模在線數據,比如說搜索引擎中的自動校正或者叫智能提示,即使在影視劇、動漫、綜藝等影片的自動檢測錯誤和更正上本模型還有很多提升的地方,若您不吝惜鍵盤,請敲上你的想法,讓我知道,讓我們開源、開放、開心,最後源碼在github上,可以自己點擊ZIP下載後解壓,在eclipse中創建工程wordproofread並將解壓出來的所有文件copy到該工程下,即可運行。