簡介:事務策略 系列文章的作者 Mark Richards 將討論如何在 Java™ 平台中為具有高吞吐 量和高用戶並發性需求的應用程序實現事務策略。理解如何進行折衷將幫助您確保高水平的數據完整性和 一致性,並減少隨後開發流程中的重構工作。
我在本 系列 的前幾篇文章中所介紹的 API 層 和 客戶端編排策略 事務策略是應用於大多數標准業 務應用程序的核心策略。它們簡單、可靠、相對易於實現,並且提供了最高水平的數據完整性和一致性。 但有時,您可能需要減小事務的作用域以獲取吞吐量、改善性能並提高數據庫的並發性。您如何才能實現 這些目的,同時仍然維持高水平的數據完整性和一致性呢?答案是使用 High Concurrency 事務策略。
High Concurrency 策略源自 API 層 策略。API 層策略雖然非常堅固和可靠,但它存在一些缺點。始 終在調用棧的最高層(API 層)啟動事務有時會效率低下,特別是對於具有高用戶吞吐量和高數據庫並發 性需求的應用程序。限制特定的業務需求,長時間占用事務和長時間鎖定都會消耗過多資源。
與 API 層策略類似,High Concurrency 策略釋放了客戶機層的任何事務責任。但是,這還意味著, 您只能通過客戶機層調用一次任何特定的邏輯工作單元(LUW)。High Concurrency 策略旨在減小事務的 總體作用域,以便資源鎖定的時間更短,從而增加應用程序的吞吐量、並發性以及性能。
通過使用此策略所獲取的好處在一定程度上將由您所使用的數據庫以及它所采用的配置決定。一些數 據庫(比如說使用 InnoDB 引擎的 Oracle 和 MySQL)不會保留讀取鎖,而其他數據庫(比如沒有 Snapshot Isolation Level 的 SQL Server)則與之相反。保留的鎖越多,無論它們是共享還是專用的, 它們對數據庫(以及應用程序)的並發性、性能和吞吐量的影響就越大。
但是,獲取並在數據庫中保留鎖僅僅是高並發性任務的一個部分。並發性和吞吐量還與您釋放鎖的時 間有關。無論您使用何種數據庫,不必要地長時間占用事務將更長地保留共享和專用鎖。在高並發性下, 這可能會造成數據庫將鎖級別從低級鎖提高到頁面級鎖,並且在一些極端情況下,從頁面級鎖切換到表級 鎖。在多數情況下,您無法控制數據引擎用於選擇何時升級鎖級別的啟發方法。一些數據庫(比如 SQL Server)允許您禁用頁面級鎖,以期它不會從行級鎖切換到表級鎖。有時,這種賭博有用,但大多數情況 下,您都不會實現預期中的並發性改善。
底線是,在高數據庫並發性的場景中,數據庫鎖定(共享或專用)的時間越長,則越有可能出現以下 問題:
數據庫連接耗盡,從而造成應用程序處於等待狀態
由共享和專用鎖造成的死鎖,從而造成性能較差以及事務失敗
從頁面級鎖升級到表級鎖
換句話說,應用程序在數據庫中所處的時間越長,應用程序能處理的並發性就越低。我所列出的任何 問題都會造成您的應用程序運行緩慢,並且將直接減少總體吞吐量和降低性能 — 以及應用程序處理大型 並發性用戶負載的能力。
折衷
High Concurrency 策略解決了高並發性需求,因為它能將事務在體系結構中的作用域盡可能減小。其 結果是,事務會比在 API 層事務策略中更快地完成(提交或回滾)。但是,就像您從 Vasa 中學到的( 見 參考資料),您不能同時擁有它們。生活中充滿了折衷,事務處理也不例外。您不能期望提供與 API 層策略同樣可靠的事務處理,同時提供最大的用戶並發性和最高的吞吐量。
因此,您在使用 High Concurrency 事務策略時放棄了什麼呢?根據您的應用程序的設計,您可能需 要在事務作用域外部執行讀取操作,即使讀取操作用於更新目的。“等一等!”您說:“您不能這樣做 — 您可能會更新在最後一次讀取之後發生了變化的數據!”這是合理的擔憂,並且也是需要開始考慮折 衷的地方。通過此策略,由於您未對數據保持讀取鎖,因此在執行更新操作時遇到失效數據異常的機率會 增加。但是,與 Vasa 的情況一樣,所有這些都可以歸結為一個問題,即哪個特性更加重要:可靠、堅固 的事務策略(如 API 層策略),還是高用戶並發性和吞吐量。在高並發性情形中,同時實現兩者是極為 困難的。如果您嘗試這樣做,則可能會適得其反。
第二個折衷之處是事務可靠性的總體缺乏。此策略難以實現,並且需要更長的時間進行開發和測試, 並且比 API 層或 Client Orchestration 策略更易於出錯。考慮到這些折衷,您首先應該分析當前的情 形以確定使用此策略是否是正確的方法。由於 High Concurrency 策略派生自 API 層策略,因此一種比 較好的方法是先使用 API 層策略,並使用較高的用戶負載對應用程序執行負載測試(比您預期的峰值負 載更高)。如果您發現吞吐量較低、性能較第、等待次數非常多,或者甚至出現死鎖,則要准備遷移到 High Concurrency 策略。
在本文的其余部分,我將向您介紹 High Concurrency 事務策略的其他一些特性,以及實現它的兩種 方法。
基本結構和特性
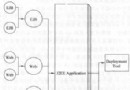
圖 1 通過我在 事務策略 系列中所使用的邏輯應用程序棧展示了 High Concurrency 事務策略。包含 事務邏輯的類顯示為紅色陰影。
圖 1. 體系結構層和事務邏輯
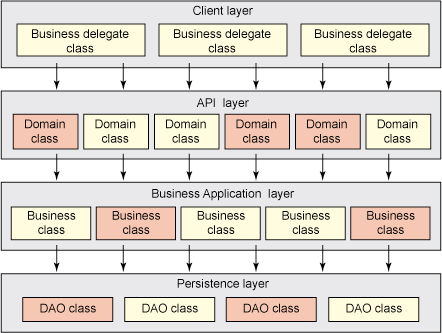
一些 API 層策略的特性和規則是有效的 — 但並非所有。注意,圖 1 中的客戶機層沒有事務邏輯, 這意味著任何類型的客戶機都可以用於此事務策略,包括基於 Web 的客戶機、桌面、Web 服務和 Java Message Service (JMS)。並且事務策略遍布於客戶機下面的層中,但這不是絕對的。一些事務可能在 API 層中開始,一些在業務層中開始,還有一些甚至在 DAO 層中開始。這種一致性的缺乏是造成策略難 以實現、維護和治理的原因之一。
在大多數情況下,您會發現您需要使用 Programmatic Transaction 模型 來減小事務作用域,但有時 您仍然會使用 Declarative Transaction 模型。但是,您通常不能在相同的應用程序中混用 Programmatic 和 Declarative Transaction 模型。在使用這種事務策略時,不應該堅持使用這種 Programmatic Transaction 模型,這樣您就不會遇到各種問題。但是,如果您發現自己可以在此策略中 使用 Declarative Transaction 模型,那麼您應該在使用 REQUIRED 事務屬性開始事務的層中標記所有 公共寫方法(插入、更新和刪除)。此屬性表示需要一個事務,並且如果事務不存在,則由方法啟動。
與其他事務策略一樣,無論您選擇開始事務的組件或層是什麼,啟動事務的方法都被認為是事務擁有 者。只要可能,事務擁有者應該是對事務執行提交和回滾的唯一方法。
事務策略實現
您可以使用兩個主要技巧來實現 High Concurrency 事務策略。先讀取(read-first)技巧涉及在盡 可能高的應用層(通常為 API 層)對事務作用域范圍外的讀取操作進行分組。低級(lower-level)技巧 涉及在體系結構中盡可能低的層啟動事務,同時仍然能夠更新操作的原子性和隔離。
先讀取技巧
先讀取技巧涉及重構(或編寫)應用程序邏輯和工作流,以便所有的處理和讀取操作在事務作用域的 外部首先發生。這種方法消除了不必要的共享或讀取鎖,但是如果數據在您能夠提交工作之前更新或提交 ,則可能會引入失效數據異常。為了應對可能的這種情況,如果在此事務策略中使用對象關系映射(ORM )框架,則應確保使用了版本驗證功能。
為了演示這種先讀取技巧,我們從一些實現 API 層事務策略的代碼入手。在清單 1 中,事務在 API 層中開始,並且包圍了整個工作單元,包括所有的讀取、處理和更新操作:
清單 1. 使用 API 層策略
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public void processTrade(TradeData trade) throws Exception {
try {
//first validate and insert the trade
TraderData trader = service.getTrader(trade.getTraderID());
validateTraderEntitlements(trade, trader);
verifyTraderLimits(trade, trader);
performPreTradeCompliance(trade, trader);
service.insertTrade(trade);
//now adjust the account
AcctData acct = service.getAcct(trade.getAcctId());
verifyFundsAvailability(acct, trade);
adjustBalance(acct, trade);
service.updateAcct(trade);
//post processing
performPostTradeCompliance(trade, trader);
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
注意在 清單 1 中,所有的處理都包含在 Java Transaction API (JTA) 事務的作用域內,包括所有 的確認、驗證和兼容性檢查(提前和事後)。如果您通過探查器工具來運行 processTrade() 方法,那麼 就會看到每個方法調用的執行時間將與表 1 相似:
表 1. API 層方法探查 — 事務作用域
方法名稱 執行時間 (ms) service.getTrader() 100 validateTraderEntitlements() 300 verifyTraderLimits() 500 performPreTradeCompliance() 2300 service.insertTrade() 200 service.getAcct() 100 verifyFundsAvailability() 600 adjustBalance() 100 service.updateAcct() 100 performPostTradeCompliance() 1800processTrade() 方法的持續時間稍微長於 6 秒 (6100 ms)。由於事務的起始時間與方法相同,因此 事務的持續時間也是 6100 ms。根據您所使用的數據庫類型以及特定的配置設計,您將在事務執行過程中 保持共享和專用鎖(從執行讀取操作開始)。此外,在由 processTrade() 方法調用的方法中執行的任何 讀取操作也可以在數據庫中保持一個鎖。您可能會猜想,在本例中,在數據庫中保持鎖持續 6 秒以上將 不能擴展以支持高用戶負載。
清單 1 中的代碼在沒有高用戶並發性或高吞吐量需求的環境中可能會非常出色地運行。遺憾的是,這 只是大多數人用於測試的一種環境。一旦此代碼進入生產環境,其中數以百計的交易者(或者是全球的) 都在進行交易,則該系統最有可能會運行得非常糟糕,並且極有可能會遇到數據庫死鎖(根據您所使用的 數據庫而定)。
現在,我將修復 清單 1 中的代碼,方法是應用 High Concurrency 事務策略的先讀取技巧。在 清單 1 所示的代碼中,第一個要注意的地方是總共只用了 300 ms 的更新操作(插入和更新)。(此處,我假 定 processTrade() 方法調用的其他方法不執行更新操作。基本技巧是在事務作用域之外執行讀取操作和 非更新處理,並且僅將更新封裝在事務內部。清單 2 中的代碼演示了減小事務作用域並仍然維持原子性 的必要性:
清單 2. 使用 High Concurrency 策略(先讀取技巧)
public void processTrade(TradeData trade) throws Exception {
UserTransaction txn = null;
try {
//first validate the trade
TraderData trader = service.getTrader(trade.getTraderID());
validateTraderEntitlements(trade, trader);
verifyTraderLimits(trade, trader);
performPreTradeCompliance(trade, trader);
//now adjust the account
AcctData acct = service.getAcct(trade.getAcctId());
verifyFundsAvailability(acct, trade);
adjustBalance(acct, trade);
performPostTradeCompliance(trade, trader);
//start the transaction and perform the updates
txn = (UserTransaction)ctx.lookup("UserTransaction");
txn.begin();
service.insertTrade(trade);
service.updateAcct(trade);
txn.commit();
} catch (Exception up) {
if (txn != null) {
try {
txn.rollback();
} catch (Exception t) {
throw up;
}
}
throw up;
}
}
注意,我將 insertTrade() 和 updateAcct() 方法移動到了 processTrade() 方法的末尾,並將它們 封裝在了一個編程事務中。通過這種方法,所有讀取操作和相應的處理將在事務的上下文之外執行,因此 不會在事務持續時間內在數據庫中保持鎖。在新代碼中,事務持續時間只有 300 ms,這顯著低於 清單 1 中的 6100 ms。再次,其目標是減少在數據庫中花費的時間,從而減少數據庫的總體並發性,以及應用程 序處理較大並發用戶負載的能力。通過使用 清單 2 中的代碼將數據庫占用時間減少至 300 ms,從理論 上說,吞吐量將實現 20 倍的提升。
如表 2 所示,在事務作用域中執行的代碼至減少至 300 ms:
表 2. API 層方法探查 — 修改後的事務作用域
方法名稱 執行時間 (ms) service.insertTrade() 200 service.updateAcct() 100雖然這從數據庫並發性的角度來說是一種顯著的改善,但先讀取技巧帶來了一個風險:由於為更新指 定的對象上沒有任何鎖,因此任何人都可以在此 LUW 過程中更新這些未鎖定的實體。因此,您必須確保 被插入或更新的對象一般情況下不會由多個用戶同時更新。在之前的交易場景中,我做了一個安全的假設 ,即只有一個交易者會在特定的時間操作特定的交易和帳戶。但是,並非始終都是這種情況,並且可能會 出現失效數據異常。
另外需要注意:在使用 Enterprise JavaBeans (EJB) 3.0 時,您必須通知容器您計劃使用編程事務 管理。為此,您可以使用 @TransactionManagement(TransactionManagementType.BEAN) 注釋。注意,這 個注釋是類級的(而不是方法級的),這表示您不能在相同的類中結合 Declarative 和 Programmatic 事務模型。選擇並堅持其中之一。
低級技巧
假設您希望堅持使用 Declarative Transaction 模型來簡化事務處理,但是仍然能在高用戶並發性場 景中增加吞吐量。同時,您應該在這種事務策略中使用低級技巧。通過此技巧,您通常會遇到與先讀取技 巧相同的折衷問題:讀取操作通常是在事務作用域的外部完成的。並且,實現這種技巧最有可能需要代碼 重構。
我仍然從 清單 1 中的示例入手。不用在相同的方法中使用編程事務,而是將更新操作移動到調用棧 的另一個公共方法中。然後,完成讀取操作和處理時,您可以調用更新方法;它會開始一個事務,調用更 新方法並返回。清單 3 演示了這個技巧:
清單 3. 使用 High Concurrency 策略(低級技巧)
@TransactionAttribute (TransactionAttributeType.SUPPORTS)
public void processTrade(TradeData trade) throws Exception {
try {
//first validate the trade
TraderData trader = service.getTrader(trade.getTraderID());
validateTraderEntitlements(trade, trader);
verifyTraderLimits(trade, trader);
performPreTradeCompliance (trade, trader);
//now adjust the account
AcctData acct = service.getAcct (trade.getAcctId());
verifyFundsAvailability(acct, trade);
adjustBalance (acct, trade);
performPostTradeCompliance(trade, trader);
//Now perform the updates
processTradeUpdates(trade, acct);
} catch (Exception up) {
throw up;
}
}
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public void processTradeUpdates(TradeData trade, AcctData acct) throws Exception {
try {
service.insertTrade(trade);
service.updateAcct(trade);
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
通過此技巧,您可以有效地在調用棧的較低層次開始事務,從而減少花費在數據庫中的時間。注意, processTradeUpdates() 方法僅更新在父方法(或以上)中修改中創建的實體。再次,保持事務的時間不 再是 6 秒,您只需要 300 ms。
現在是最難的部分。與 API 層策略或 Client Orchestration 策略不同,High Concurrency 策略並 未使用一致的實現方法。這便是 圖 1 看上去為何像一名經驗豐富的曲棍球員(包括缺少的牙齒)的原因 。對於一些 API 調用,事務可能會在 API 層的末端開始,而其他時候,它可能僅限於 DAO 層(特別是 對於LUW 中的單表更新)。技巧是確定在多個客戶機請求之間共享的方法,並確保如果某個事務是在較高 級的方法中開始的,則它將在較低級的方法中使用。遺憾的是,此特性的效果是,作為非事務擁有者的較 低級方法可以對異常執行回滾。結果,開始事務的父方法不能對異常采取正確的措施,並且在嘗試回滾( 或提交)已經標記為回滾的事務時會出現異常。
實現指南
有些情況僅需要稍微小些的事務作用域來滿足吞吐量和並發性需求,而另一些情況需要大大縮小事務 作用域來實現所需的目的。不管具體情況如何,您都可以遵循以下的實現指導,它們能夠幫助您設計和實 現High Concurrency 策略:
在著手使用低級別技術之前,首先要從先讀技術開始。這樣,事務至少包含在應用程序架構的 API 層 ,並且不擴散到其他層中。
當使用聲明性事務時,經常使用 REQUIRED 事務屬性而不是 MANDATORY 事務屬性來獲得保護,避免啟 動某個事務的方法調用另一個事務方法。
在采用此事務策略之前,確保您在事務作用域外部執行讀取操作時是相對安全的。查看您的實體模型 並問自己多個用戶同時操作相同的實體是常見的、少見還是不可能的。舉例來說,兩個用戶可以同時修改 相同的帳戶嗎?如果您的回答是常見,則面臨著極高的失效數據異常風險,那麼這個策略對於您的應用程 序探查來說是一個很差的選擇。
並不需要讓所有 讀取操作都處於事務作用域之外。如果有一個特定的實體經常會被多個用戶同時更改 ,則應該想盡一切辦法將它添加到事務作用域中。但是應該清楚,添加到事務作用域中的讀取操作和處理 越多,吞吐量和用戶負載功能的下降就越大。
結束語
一切都歸結於如何在問題之間取得折衷。為了在應用程序或子系統中支持高吞吐量和高用戶並發性, 您需要高數據庫並發性。要支持高數據庫並發性,則需要減少數據庫鎖,並盡可能縮短保持資源的時間。 某些數據庫類型和配置可以處理一些這種工作,但在大多數情況下,解決方案最終歸結為如何設計代碼和 事務處理。對這些問題有一些了解之後,您在稍後可以更加輕松地完成復雜的重構工作。選擇正確的事務 策略對應用程序的成功至關重要。對於高用戶並發性需求,可以使用 High Concurrency 事務策略作為確 保高水平數據完整性,同時維持高並發性和吞吐量需求的解決方案。